
안녕하세요 여러분, 혹시 이 물건이 냉장고로 보이십니까?
혹시 냉장고라고 생각하셨다면, 정답입니다.(옷장 같기도 해서)
모두가 방금 떠올렸듯 우리는 이 물건을 ‘냉장고’라고 부릅니다.
‘냉장고’는 어떠한 용도인가요? 혹은 무엇이 들어있는지 예상할 수 있나요?
Of course.. 너무 당연하게도 우리는 ‘냉장고’의 용도와 그 안에 무엇이 들어있는지 충분히 예상할 수 있습니다.
What?
Repository Pattern
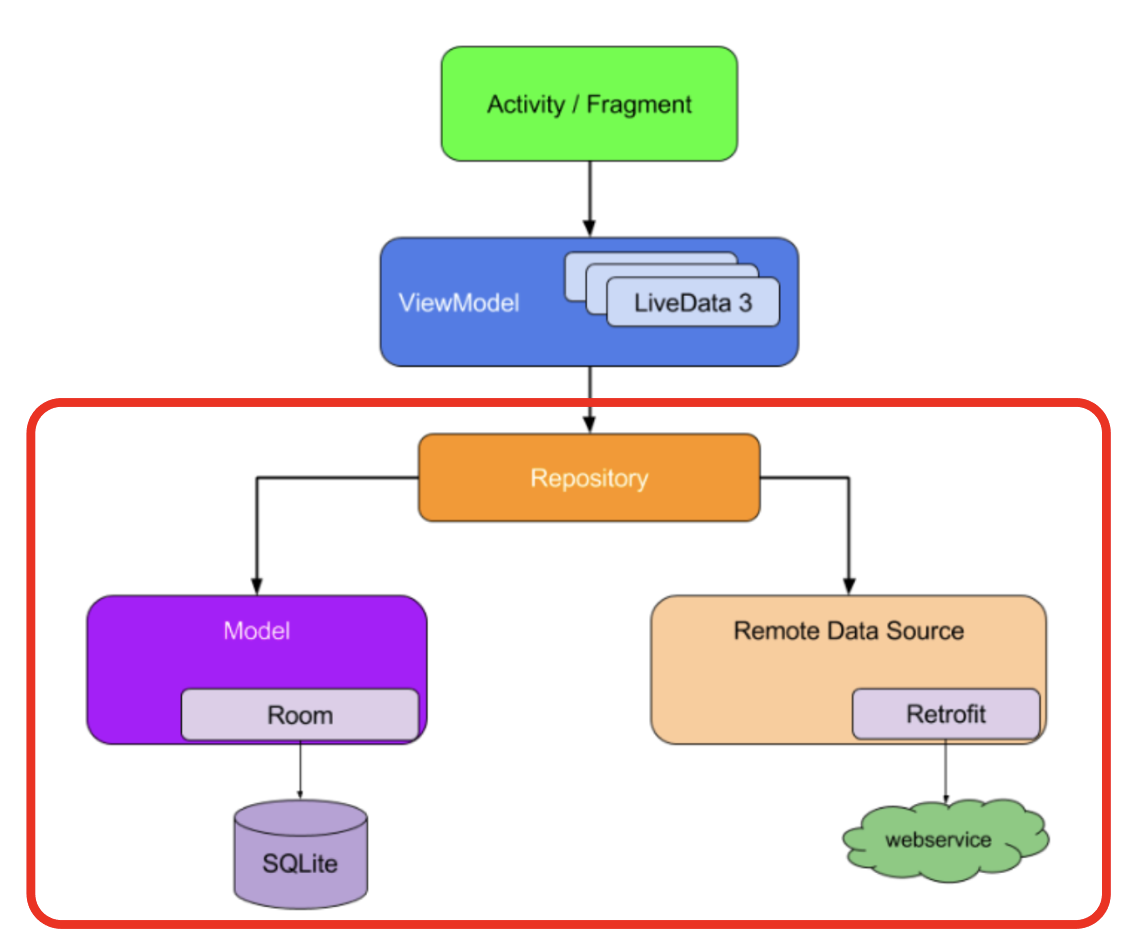
레포지토리 패턴 관련 제일 흔한 짤
저장소 패턴은 데이터 레이어를 앱의 나머지 부분에서 분리하는 디자인 패턴입니다. 데이터 레이어는 UI와는 별도로 앱의 데이터와 비즈니스 로직을 처리하는 앱 부분을 나타내며 앱의 나머지 부분에서 이 데이터에 액세스할 수 있도록 일관된 API를 노출합니다. UI가 사용자에게 정보를 제공하는 동안 데이터 레이어에는 네트워킹 코드, Room 데이터베이스, 오류 처리, 데이터를 읽거나 조작하는 코드 등이 포함됩니다.
“저장소 패턴은 데이터 레이어를 앱의 나머지 부분에서 분리하는 디자인 패턴입니다.”
더 쉽게 말해, 앱에서 데이터와 관련된 로직들을 따로 분리해서 모아둔 것이 바로 이 ‘레포지터리 패턴’입니다.
엥? 이게 끝이야? 네. 이게 끝입니다.
Why?
‘레포지토리 패턴’은 앱에서 데이터 레이어를 분리하며, 중앙집권 형태로 일관된 데이터 API를 제공합니다.
이를 통해 얻을 수 있는 이점은 다음과 같습니다.
- 데이터 추상화로 인한 데이터 관리가 용이하다.
- 데이터의 교체가 용이하다.
- 여러 데이터 소스에 대한 중복 코드를 방지하고 일관성을 유지할 수 있다.
- 데이터가 모듈화되어 있다 보니 테스트 또한 용이하다.
- 관심사가 분리되어 데이터, 비즈니스 로직에 집중할 수 있다.
흔히 찾아볼 수 있는 ‘레포지토리 패턴’의 장점들입니다. 보다시피 다 거기서 거기 같은 말입니다.
결론적으로, 단순히 데이터를 하나의 레이어로 모아둔 것으로 위와 같은 이점들을 팔로우할 수 있습니다.
적어도 안드로이드 공식문서에서 언급하는 ‘레포지토리 패턴’에 대한 개념은 여기까지가 끝입니다.
(처음 접하신다면 여기까지만 이해하셔도 좋습니다.)
다만, 몇 가지 짚고 넘어갈 사항이 있습니다.
1. 레포지토리는 앱 데이터의 특정 부분에 대해 single source of truth(SSOT)를 지켜야 합니다.
위에서 설명했듯, 레포지토리는 데이터를 한 군데에 집약적으로 관리합니다.
그렇기 때문에 SSOT가 지켜지지 않는다면, 해당 레포지토리를 사용하는 데에 있어 데이터의 일관성에 관해 원치 않는 ‘Side-Effect’가 발생할 수 있습니다.
만약 이를 지키지 못한다면, 안티 패턴이 되어버릴 가능성이 큽니다.
2. 데이터 추상화로 인한 데이터 관리가 용이하다.
여기서 ‘추상화’라고 함은, 우리가 흔히 생각하는 interface 혹은 abstract class를 뜻하는 것이 아닙니다.
 |  |
|---|
김치냉장고(A)와 비스포크 냉장고(B)의 공통점은 무엇인가요? 맞습니다. 이 둘은 냉장고(C)란 사실..
우리는 김치냉장고(A)와 비스포크 냉장고(B)를 냉장고(C)라는 보다 고수준의 개념으로 ‘추상화’할 수 있습니다.
[ 오! 나의귀신님 ] 이란 드라마를 보셨나요?
메인셰프(조정석)가 수셰프(강기영)에게 냉장고(C)에서 새우(Z)를 가져오라고 시켰습니다.
메인셰프는 수셰프가 가져온 새우(Z)가 김치냉장고(A)에서 왔는지, 비스포크 냉장고(B)에서 왔는지 알 수도, 알 필요도 없습니다.
코드에 비유하자면,
우리는 Remote(A)와 Local(B) 을 레포지토리(C)라는 보다 고수준의 개념으로 ‘추상화’할 수 있습니다.
이 레포지토리(C)에서 가져온 데이터(Z)의 출처가 Remote(A)에서 왔는지, Local(B)에서 왔는지 알 수도, 알 필요도 없습니다.
그렇기 때문에 데이터의 출처가 변경되어도, 그 변경 사항이 다른 레이어까지 전파되지 않습니다.
레포지토리 패턴을 이야기하며 interface 를 떠올리셨다면, “클린아키텍처의 DIP” 와 혼동하고 있진 않은지 재점검이 필요합니다.
HOW?

잘 보고 갑니다