스프링 배치 중 오류가 생긴다면 어떻게 복구할 수 있을까? 오류가 발생했을 때 어떤 처리를 하고 있었는지, 잡이 다시 시작된다면 어떻게 되는지에 대한 정보는 Job Repository의 상태 관리를 통해서 알 수 있다. 또한 모니터링도 가능하다.
Job Repository
스프링 배치에서 Job Repository는 인터페이스, 데이터 저장소 두가지 의미를 가진다. 이 중에서 데이터 저장소에 대해 다뤄보자. 데이터 저장소는 관계형 데이터베이스, 인메모리 저장소 이렇게 두가지 저장소를 제공한다.
관계형 데이터 베이스
6개의 테이블이 존재한다.
- BATCH_JOB_INSTANCE
- BATCH_JOB_EXECUTION
- BATCH_JOB_EXECUTION_PARAMS
- BATCH_JOB_EXECUTION_CONTEXT
- BATCH_STEP_EXECUTION
- BATCH_STEP_EXECUTION_CONTEXT
BATCH_JOB_INSTANCE
시작점이다. 잡을 실행하면 job instance 레코드가 테이블에 저장된다.
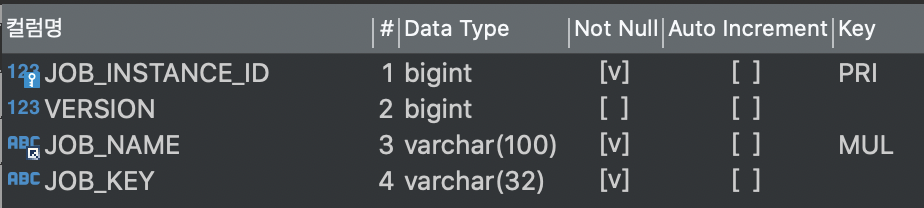
테이블의 PK
optimistic locking에 사용되는 레코드 버전
실행된 잡의 이름
잡 이름과 잡 파라미터의 해시값(job instance를 고유하게 식별하는 값)
BATCH_JOB_EXECUTION
그 다음으로 BATCH_JOB_EXECUTION 테이블에서 배치 잡의 실제 실행 기록을 저장한다.
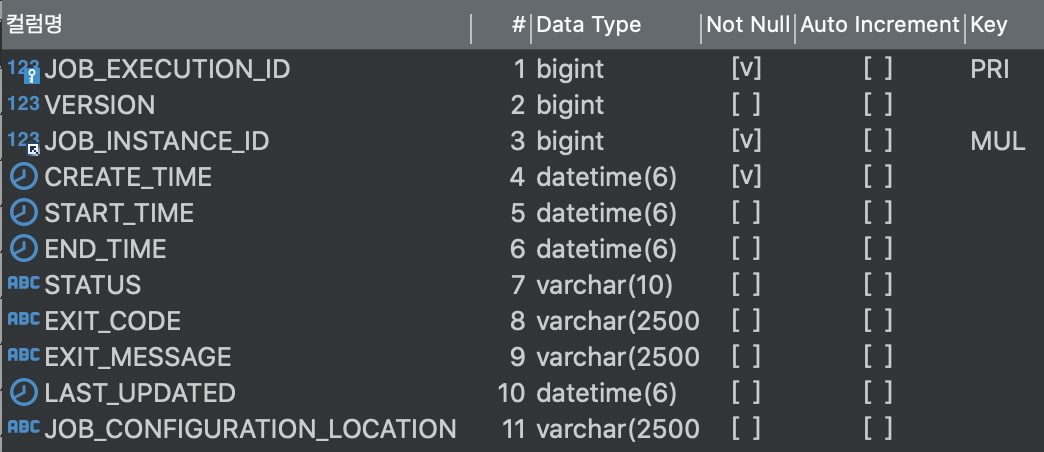
테이블의 PK
optimistic locking에 사용되는 레코드 버전
BATCH_JOB_INSTANCE의 FK
레코드 생성 시간
잡 실행 시작 시간
잡 실행 완료 시간
잡 실행의 배치 상태
잡 실행의 종료 코드
EXIT_CODE와 관련된 메시지나 스택 트레이스
레코드의 마지막 갱신 시간
BATCH_JOB_EXECUTION_CONTEXT
Batch job의 execution context에 대한 정보를 저장하고 있다. 이 정보는 배치가 여러번 실행해야 하는 상황에서 유용하게 쓰인다.

테이블의 PK
Trimmed SERIALIZER_CONTEXT
직렬화된 execution context
이 때 직렬화에는 XStream의 JSON 처리 기능이 사용됐지만 스프링 배치 4부터 Jackson2를 사용하도록 변경되었다.
BATCH_JOB_EXECUTION_PARAMS
잡이 실행될 때마다 사용된 파라미터들에 대한 정보를 저장한다. 이 때 잡에 전달된 모든 파라미터가 테이블에 저장되며 재시작시에는 잡의 식별 파라미터만 전달하여 새로운 job instance가 필요한지 판단한다.
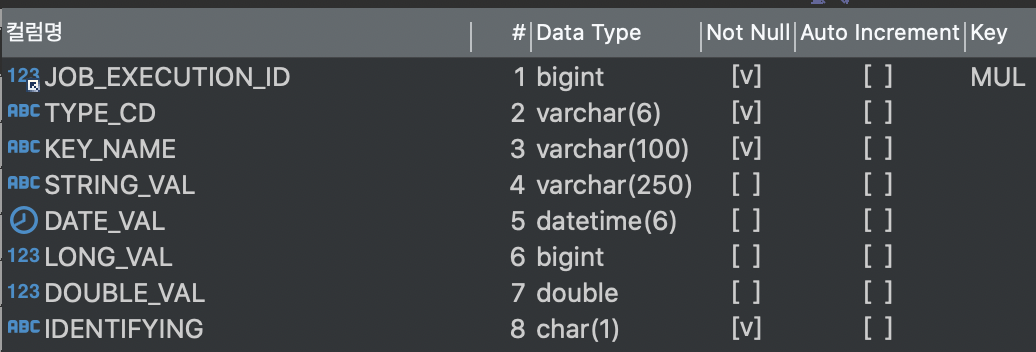
테이블의 PK
파라미터 값의 타입
파라미터의 이름
각 타입별 파라미터 값
식별 파라미터 여부를 나타내는 플래그
BATCH_STEP_EXECUTION
스텝의 메타 데이터를 저장하는 테이블이다.
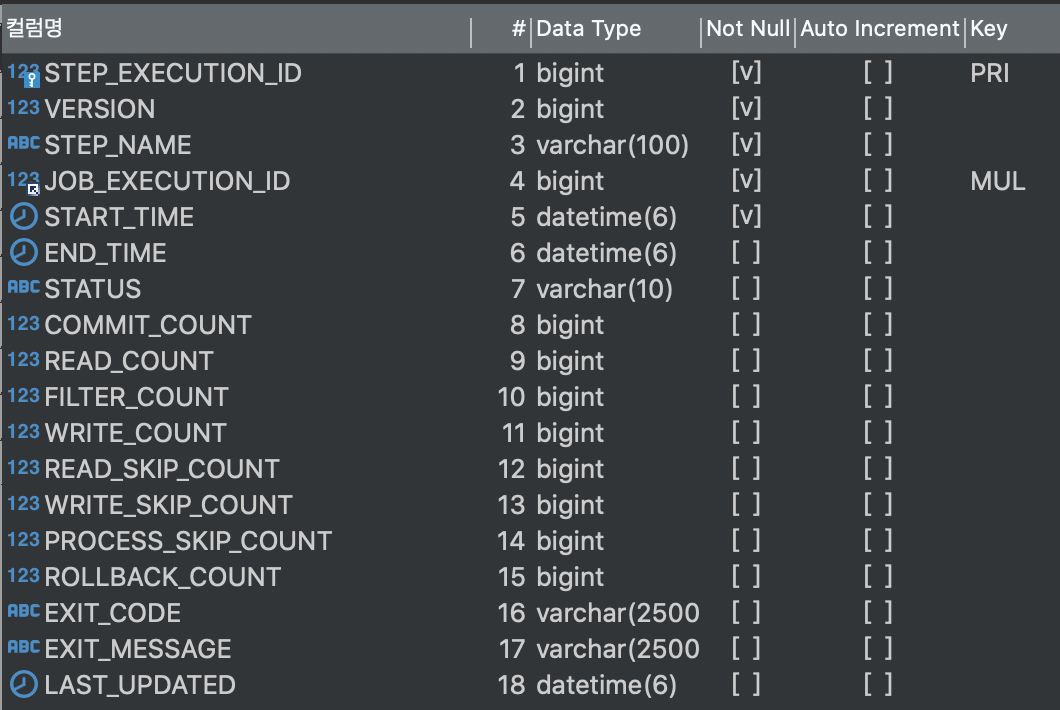
테이블의 PK
optimistic locking에 사용되는 레코드의 버전
스텝 이름
BATCH_JOB_EXECUTION FK
스텝 실행 시작 시간
스텝 실행 완료 시간
스텝 배치 상태
스텝 실행 중 커밋된 트랜잭션 수
읽은 아이템 수
ItemProcessor가 null을 반환해 필터링된 아이템 수
기록된 아이템 수
ItemReader, ItemProcessor, ItemWriter 내에서 예외가 던져졌을 때 건너뛴 아이템 수
스텝에서 롤백된 트랜잭션 수
스텝의 종료 코드
스텝 실행에서 반환된 메시지나 스택 트레이스
레코드가 마지막으로 업데이트된 시간
BATCH_STEP_EXECUTION_CONTEXT
Step execution의 execution context에 대한 테이블이다.

테이블의 PK
trimmed SERIALIZED_CONTEXT
직렬화된 ExecutionContext
인메모리 Job Repository
따로 rdbms를 관리하고 싶지 않은 상황에서는 인메모리를 사용할 수 있다. 이 때 Map 객체를 사용하여 데이터를 저장한다. 하지만 실제 운영에서는 Map 객체를 이용한 데이터 저장은 거의 사용하지 않고 멀티 스레딩, 트랜잭션같은 기능들을 더 잘 지원하는 H2, HSQLDB와 같은 인메모리 데이터베이스를 사용한다.
배치 인프라스트럭처 구성하기
@EnableBatchProcessing 적용 시 별도의 작업을 하지 않고 Job Repository를 사용할 수 있다. 이 과정에서 Job Repository를 커스텀할 수 있다.
BatchConfigurer 인터페이스
@EnableBatchProcessing 적용 후 -> BatchConfigurer 구현체에서 빈 생성 -> SimpleBatchConfiguration에서 ApplicationContext에 생성한 빈 등록
이 과정에서 보통 노출되는 컴포넌트를 커스텀하기 위해서 BatchConfigurer을 커스텀한다.
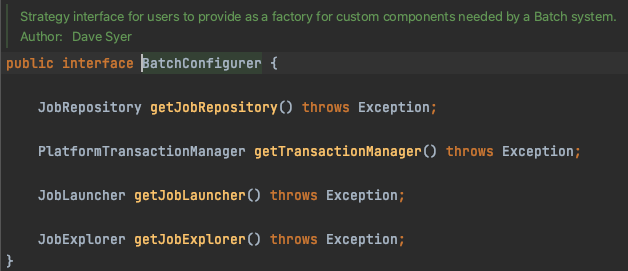
- PlatformTransactionManager : 프레임 워크가 제공하는 모든 트랜잭션 관리 시에 스프링 배치가 사용하는 컴포넌트
- JobExplorer : JobRepository의 데이터를 읽기 전용으로 볼 수 있는 기능
이 때 BatchConfigurer을 상속받아 모든 메서드를 재정의하기보다는 DefaultBatchConfigurer을 상속해 필요한 메서드만 재정의하는 것이 더 쉽다.
JobRepository 커스텀
JobRepository는 JobRepositoryFactoryBean이라는 빈을 통해 생성된다.
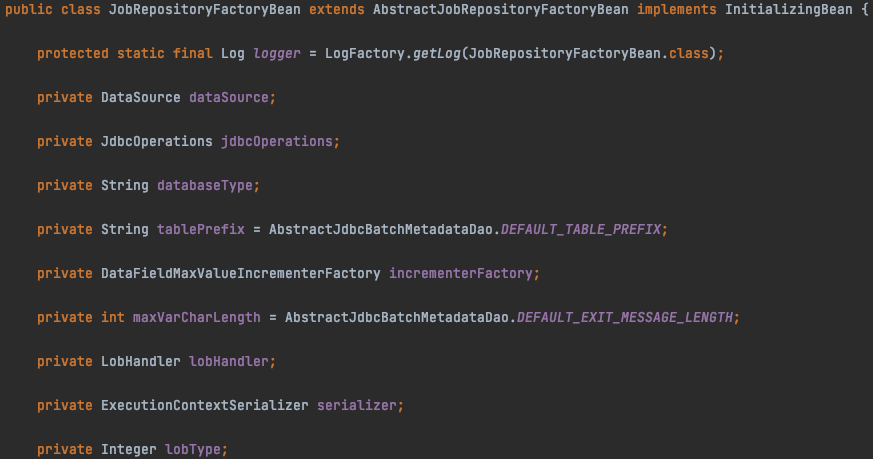
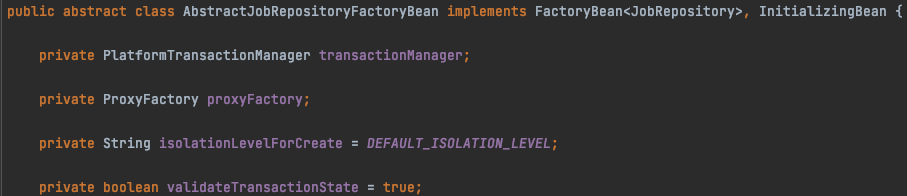
위의 있는 필드들을 수정하여 커스텀할 수 있다.
DefaultBatchConfigurer를 상속해 createJobRepository() 를 재정의해야 하는 가장 일반적인 경우는 ApplicationContext에 두 개 이상의 데이터 소스가 존재한느 경우이다.
@Override
protected JobRepository createJobRepository() throws Exception
{
JobRepositoryFactoryBean factoryBean = new JobRepositoryFactoryBean();
factoryBean.setDatabaseType(DatabaseType.MYSQL.getProductName());
// 테이블 접두어 기본 값을 BSATCH_가 아닌 FOO_로 설정
factoryBean.setTablePrefix("FOO_");
// 데이터 생성 시 트랜잭션 격리 레벨 설정 factoryBean.setIsolcationLevelForCreate("ISOLATION_REPEATABLE_READ");
factoryBean.setDataSource(dataSource);
// 스프링 컨테이너가 빈 정의로 직접 호출하지 않음. 개발자가 직접 호출해야 한다.
factoryBean.afterPropertiesSet();
return factoryBean.getObject();
}TransactionManager 커스텀
DefaultBatchConfigurer의 getTransactionManager를 호출하면 배치 처리에 사용할 목적으로 정의해둔 PlatformTransactionManager가 리턴된다. 이 때 정의해둔 TransactionManager가 없을 경우 DefaultConfigurer가 자동으로 생성한다.
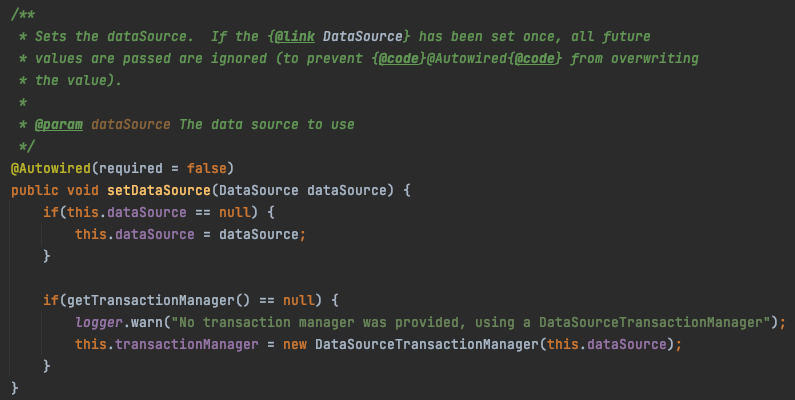
getTransactionManager 메서드를 오버라이드하여 재정의하면 어떤 TransactionManager를 리턴할지 커스텀할 수 있다.
JobExplorer 커스텀
JobExplorer는 JobRepository가 다루는 데이터를 읽기 전용으로 보는 뷰
-> 기본적 데이터 접근 계층은 JobRepository, JobExplorer 가 공유하는 공통 DAO 집합
-> 데이터를 읽을 때 사용하는 애트리뷰트 JobRepository와 동일
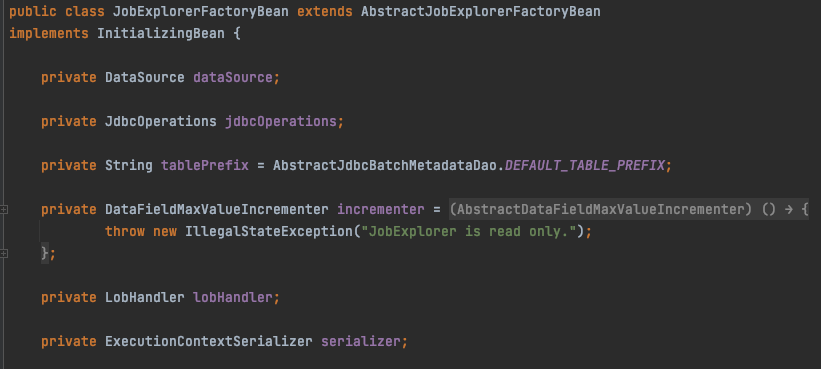
@Override
protected JobExplorer createJobExplorer() throws Exception
{
JobExplorerFactoryBean factory = new JobExplorerFactoryBean();
factory.setDataSource(this.dataSource);
factory.setTablePrefix("FOO_");
// BatchConfigurer 메소드는 스프링 컨테이너에 직접 노출되지 않으므로 직접 호출
factory.afterPropertiesSet();
return factory.getObject();
}JobLauncher 커스텀
JobLauncher는 스프링 배치 잡을 실행하는 진입점으로 대부분 SimpleJobLauncher를 사용한다. 그렇기에 커스터마이징할 일이 거의 없지만 어떤 잡이 MVC 애플리케이션의 일부분으로 존재하며 컨트롤러를 통해 해당 잡을 실행할 때 별도의 방식으로 잡을 구동하는 방법을 외부에 공개하고 싶을 수 있다. 이 때 SimpleJobLauncher의 구동 방식을 조정한다.
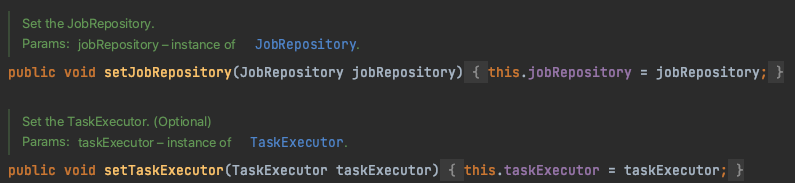
SimpleJobLauncher 클래스에서 job repository, task executor(보통 SyncTaskExecutor)를 커스텀할 수 있는 메서드를 확인할 수 있다.
잡 메타 데이터 사용하기
보통 JobExplorer를 사용해서 JobRepository의 데이터를 가져온다.
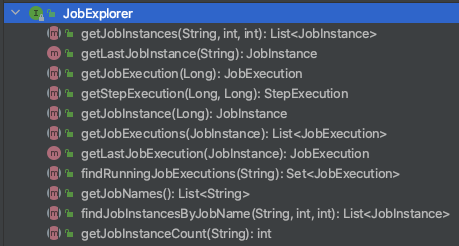
jobExplorer 인터페이스에 선언된 메소드들이다. 위의 메소드들을 이용하여 메타 데이터를 읽어올 수 있다.
public class ExploringTasklet implements Tasklet {
private JobExplorer explorer;
public ExploringTasklet(JobExplorer explorer) {
this.explorer = explorer;
}
public RepeatStatus execute(StepContribution stepContribution,
ChunkContext chunkContext) {
// 현재 job의 이름을 가져온다.
String jobName = chunkContext.getStepContext().getJobName();
// jobName인 job의 첫번째 인덱스부터 MAX_VALUE만큼 가져온다.
List<JobInstance> instances =
explorer.getJobInstances(jobName,
0,
Integer.MAX_VALUE);
System.out.println(
String.format("There are %d job instances for the job %s",
instances.size(),
jobName));
System.out.println("They have had the following results");
System.out.println("************************************");
for (JobInstance instance : instances) {
// instance의 job execution 리스트를 가져온다.
List<JobExecution> jobExecutions =
this.explorer.getJobExecutions(instance);
System.out.println(
String.format("Instance %d had %d executions",
instance.getInstanceId(),
jobExecutions.size()));
for (JobExecution jobExecution : jobExecutions) {
// job execution 정보를 가져온다.
System.out.println(
String.format("\tExecution %d resulted in Exit Status %s",
jobExecution.getId(),
jobExecution.getExitStatus()));
}
}
return RepeatStatus.FINISHED;
}
}