책 <Real MySQL 8.0>을 읽고 정리한 내용입니다.
InnoDB
레코드 기반 잠금 제공, 높은 동시성 처리가 가능하고 안정적이며 성능이 뛰어남.
PK에 의한 클러스터링
- 레코드를 PK 순으로 정렬하여 disk에 저장
- InnoDB에서는 PK를 통해 데이터 파일(disk)에 접근
- PK 인덱스 자동 생성 (사용자가 직접 사용 불가 --> 사용자가 직접 PK를 설정해주는 것이 좋다.)
- PK를 통한 범위 검색이 매우 빠름
- 단점 : 클러스터링 때문에 쓰기 성능 저하 (PK값이 바뀌면 레코드의 물리적 순서도 바꿔줘야 하기 때문)
- 일반적인 웹 서비스에서는 읽기 성능이 쓰기 성능보다 중요하기 때문에 쓰기 성능을 희생하고 읽기 성능을 얻는 클러스터링 하는 것이 합리적.
트랜잭션 지원 (MVCC, redo log & undo log, 레코드 단위 lock)
MVCC (Multi Version Concurrency Control) : 레코드에 대해 다양한 버전이 동시에 관리된다.
레코드에 잠금을 걸지 않고도 트랜잭션 격리 수준에 따라 일관된 읽기를 할 수 있다.
<- undo log를 이용하여 이 기능을 구현한다.
트랜잭션 격리 수준에 따라 조회되는 데이터가 다름.
(READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE)
데이터가 변경될 때?
InnoDB 버퍼풀 : 변경된 데이터를 디스크에 반영하기 전까지 잠시 버퍼링 하는 곳, 즉시 새로운 데이터로 변경됨. (COMMIT 명령이 실행되면 변경된 데이터를 디스크에 반영)
Undo log : INSERT, UPDATE, DELTE 같은 문장으로 데이터를 변경할 때 변경되기 이전 데이터를 백업 해두는 공간, 트랜잭션 롤백할 때 언두 로그를 사용하여 이전 버전의 데이터로 복구, 트랜잭션 격리 수준에 맞게 언두 로그에 백업해둔 데이터를 읽어 반환.
잠금 없는 일관된 읽기
MVCC기술을 이용하여 잠금을 걸지 않고 일관된 읽기 작업이 가능하다.
자동 데드락 감지
Undo log & Redo log
- Undo log
- 변경되기 이전 데이터를 백업
- 트랜잭션 보장 (Rollback시 undo log에 백업된 데이터 복원)
- 트랜잭션 격리 수준 보장
(트랜잭션 격리 수준에 맞게, 백업된 데이터 반환)
트랜잭션 격리 수준 : 동시에 여러 트랜잭션이 데이터를 변경하거나 조회할 때 한 트랜잭션의 작업 내용이 다른 트랜잭션에 어떻게 보일지를 결정하는 기준.
- Redo log
- 변경된 데이터를 백업 (Commit 완료된 데이터)
- 영속성 보장
- 서버 비정상 종료시, 리두 로그에 백업된 데이터 복원
레코드 단위 잠금
-
레코드 단위로 잠금을 걸기 때문에 동시 처리 성능이 좋다.
-
사실 레코드 자체를 잠그는 것이 아닌, 인덱스를 잠금.
- 인덱스 어떻게 설정 했냐에 따라 레코드 잠금 범위가 달라짐.
- 예시1.
가정
테이블의 총 레코드 개수 : 5000개
성씨 컬럼이 '박'인 레코드 : 300개
성씨 컬럼이 '박'이고 이름 컬럼이 '병욱'인 레코드 : 1개
성씨 컬럼에는 idx_성씨 index가 생성되어 있음.
이 상태에서
성씨가 '박'이고 이름이 '병욱'인 user의 취미를 '축구'로 바꾸는 update 쿼리를 실행하게되면?
이 테이블은 성씨 컬럼에 대해 index가 존재하므로 성이 '박'인 레코드 300개가 모두 lock이 걸리게 된다.- 예시 2.
가정
테이블의 총 레코드 개수 : 5000개
성씨 컬럼이 '박'인 레코드 : 300개
성씨 컬럼이 '박'이고 이름 컬럼이 '병욱'인 레코드 : 1개
index 존재 X (자동으로 생성된 PK 인덱스만 존재)
이 상태에서 성씨가 '박'이고 이름이 '병욱'인 user의 취미를 '축구'로 바꾸는 update 쿼리를 실행하게되면?
이 테이블은 성씨 컬럼에 대한 index가 존재하지 않고 대신에 자동으로 생성된 PK 인덱스만 존재하므로 테이블 full scan을 하게된다. 따라서 검색에 사용된 모든 PK 인덱스가 lock이 걸리게 됨. 즉 5000개 레코드 모두 lock이 걸린다.
- 예시 3.
가정
테이블의 총 레코드 개수 : 5000개
성씨 컬럼이 '박'인 레코드 : 300개
성씨 컬럼이 '박'이고 이름 컬럼이 '병욱'인 레코드 : 1개
성씨 컬럼과 이름 컬럼에 대한 복합 index 존재
이 상태에서 성씨가 '박'이고 이름이 '병욱'인 user의 취미를 '축구'로 바꾸는 update 쿼리를 실행하게되면?
이 테이블은 성씨 컬럼과 이름 컬럼에 대해 복합 index가 존재하므로 성이 '박'이고 이름이 '병욱'인 레코드 1개만 lock이 걸리게 된다.
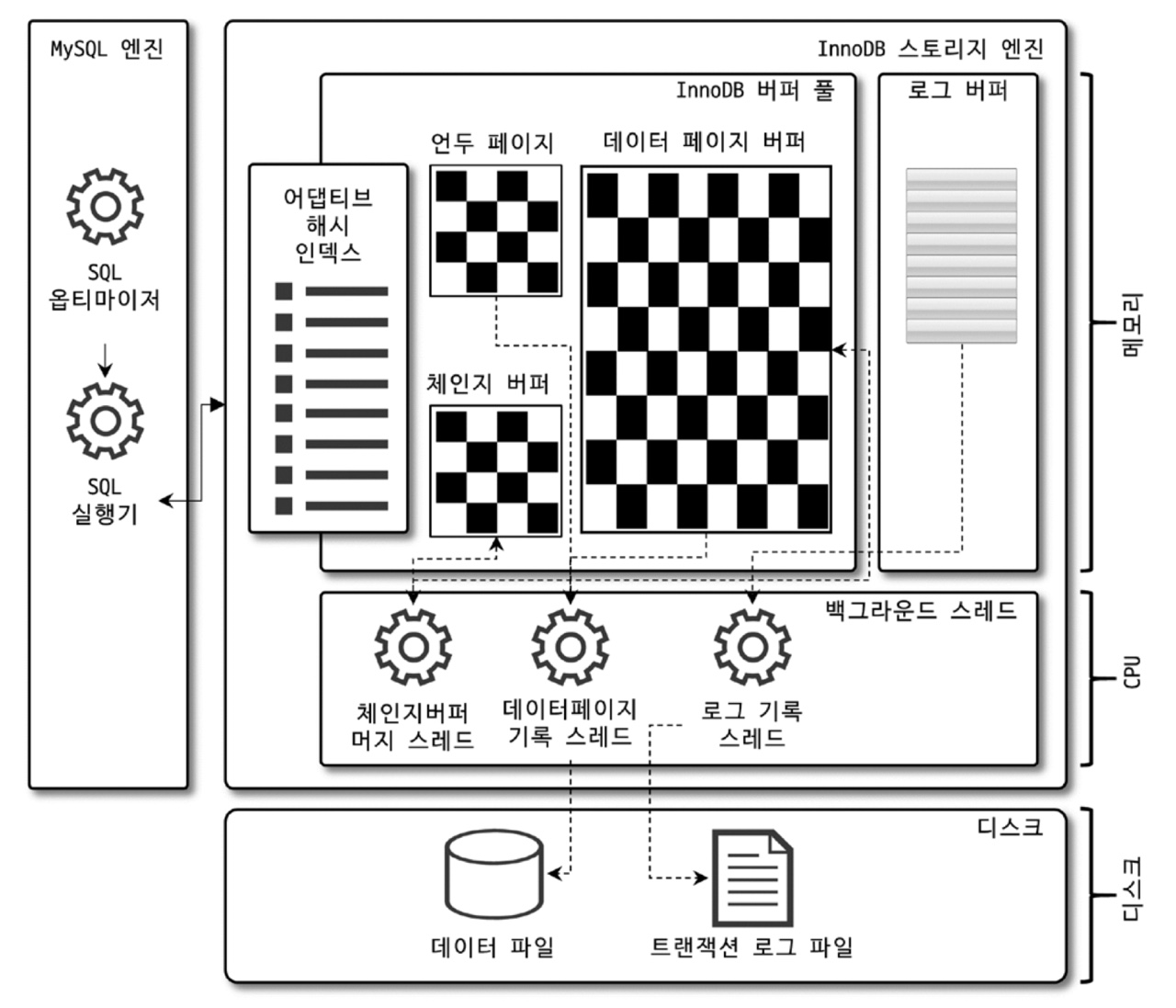
InnoDB 버퍼풀
- 데이터 캐싱
- 인덱스 정보와 데이터 파일을 메모리에 캐싱
- 페이지 단위로 테이블 데이터 관리
- 페이지 교체 알고리즘으로 LRU 사용
- 쓰기 지연 버퍼
- 변경된 데이터(더티 페이지)를 버퍼풀에 모았다가, 한번에 디스크에 기록
- 더티 페이지 : insert, update, delete 명령어로 변경된 페이지
- 변경된 데이터(더티 페이지)를 버퍼풀에 모았다가, 한번에 디스크에 기록
어댑티브 해시 인덱스
- B-tree 검색 시간을 줄여주기 위해 도입된 기능
- 페이지에 빠르게 접근하기 위한 해시 자료구조 기반 인덱스
- <인덱스 키, 페이지 주소 값> 쌍으로 구성됨
- 자주 요청되는 페이지에 대해 InnoDB가 자동으로 생성하는 인덱스
MyISAM
- 클러스터링 지원 X
- 트랜잭션 지원 X
- 외래키 지원 X
- 테이블 단위로 잠금
- 키 캐시 사용
