인덱스 : 원하는 데이터를 빨리 찾기 위해 투플의 키 값에 대한 물리적 위치를 기록해 둔 자료 구조
(RDBMS의 인덱스는 대부분 B-tree 구조)
search key : 한 파일에서 레코드를 찾는 데 사용되는 속성이나 속성들의 집합
인덱스 파일은 index entry가 여러개 모인 형태
- 이때 index entry : search key와 레코드를 가리키는 pointer로 이뤄짐.
PK나 unique key 대해서는 자동적으로 인덱스가 생성됨.
이렇게 인덱스는 데이터베이스의 성능 향상 수단으로 가장 일반적인 방법이다.
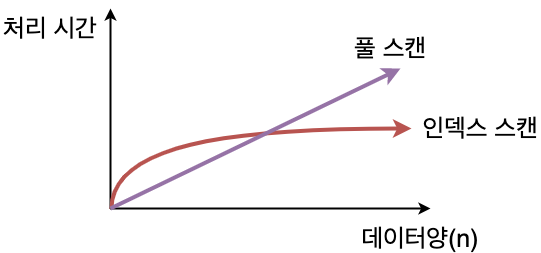
?? 궁금증 : 그렇다면 어떤 경우 인덱스 스캔보다 풀 스캔을 사용하는 것이 좋을까??
레코드 수가 작은 테이블인 경우 풀 스캔이 더 좋음.
이 경우, 만일 인덱스 스캔을 하면 인덱스를 참조하는 오버헤드 연산도 생기므로 성능이 풀스캔보다 안 좋음.
인덱스 종류
1. 순서 인덱스 (Ordered indices)
ex) 인덱스-순차 구조, B+ tree 구조
인덱스 파일에 search key들이 정렬된 순서로 되어 있다.
- Clustering Index(Primary index, 주 인덱스)
- 인덱스 파일 순서 == 데이터 파일 순서
- Nonclustering Index(Secondary index, 보조 인덱스)
- 인덱스 파일 순서 != 데이터 파일 순서
- 무조건 dense index 이어야 한다. (데이터 파일에 레코드들이 무작위로 순서로 존재하므로)
- index entry의 pointer는 데이터 파일의 레코드를 직접 가리켜서는 안됨.
대신 레코드의 위치를 담고 있는 버켓을 가리켜야함. (간접참조)
why? search key가 PK가 아닌 경우 중복값이 존재할 수도 있기 때문. 중복된 레코드들이 뿔뿔이 흩어져 있으므로 이것들의 위치를 담는 별도의 버켓을 만들어야 함.
index - sequential organization
레코드들은 검색 키(search key)값에 따라 연속적인 순서로 저장됨.
(linked list 자료구조와 비슷하게 link를 사용하여 레코드들을 연결)
정렬 기준 : search key (반드시 PK일 필요 없다.)
즉 search key에 대해 clustering index를 가지는 구조
밀집과 희소 인덱스
- Dense index : 데이터 파일에 search key의 값들이 모두 index 파일에 존재하는 경우
- Sparse index : 데이터 파일에 search key 일부 값들만 index 파일에 존재하는 경우
- 이때 데이터 파일은 search key를 중심으로 정렬되어 있어야 함. 즉 clustering index이어야 한다.
인덱스 특징
- 테이블의 한 개 이상의 속성을 이용하여 생성
- 빠른 검색과 함께 효율적인 레코드 접근 가능
- 순서대로 정렬된 속성과 데이터의 위치 보유하므로 테이블보다 작은 공간 차지
- 데이터의 수정, 삭제 등의 변경이 발생하면 인덱스 재구성 필요.
Multilevel Index
인덱스 파일이 너무 큰 경우 -> 인덱스에 대한 인덱스도 만들자.
대표적인 multilevel Index : B+ tree index
이러한 index 형태를 가진 파일 구조를 B+ tree file organization이라고 함.
B+ tree index
- 인덱스가 여러개 (multileve lindex) → 루트노드, 내부노드, 리프노드로 구성된 트리 자료구조
- 이진 탐색 트리와 비슷한 형태
- 디스크 기반의 탐색트리
- 각 노드들은 디스크의 한 블록 → 각 노드를 접근하려면 디스크 I/O를 통해 버퍼로 불러온다.
- 성능을 좌우하는 것은 바로 트리의 높이
- Log(n/2)K
- 장 : 파일 재구성 필요X, 검색 성능 향상
- 단 : 데이터 삽입, 삭제, 갱신 작업시 성능. 공간 부하, 인덱스 유지 비용이 듦,
- 리프 노드에 연속된 키 값의 레코드에 대한 rowid를 저장. 실제 데이터는 rowid를 통해 데이터의 저장 위치를 찾아감.

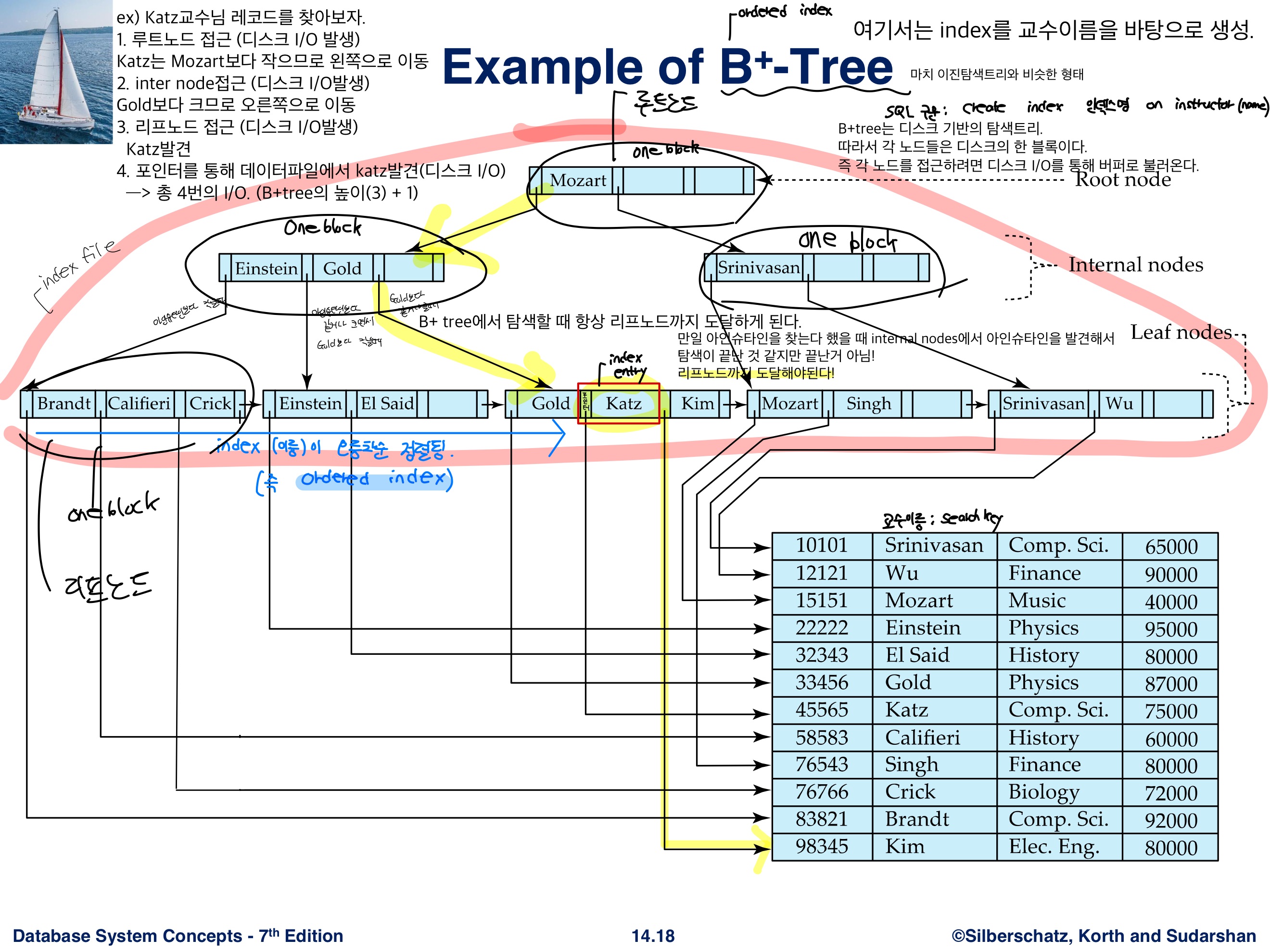
B+ tree file organization
- B+ tree file 구조에서 실제 리프노트에는 포인터가 아닌 레코드가 저장된다. --> 따로 데이터 파일이 없어도 된다.
--> 따라서 레코드들은 cluster 되어있다. (즉 search key값을 중심으로 순서대로 정렬되어 있다.)
Multiple Key Access : 합성 키 인덱스
여러 컬럼을 search key로 지정.
- 언제 사용할까?
여러 컬럼을 질의에 사용할 때 유용.
하지만 첫번째 속성에 대한 조건이 동등 조건이 아니라 비교 조건인 경우에는 합성 키 인덱스를 사용 안하는 것이 좋다.
단점
Index를 생성하고 사용하다보면 시간이 지나면 index 성능이 저하될 수 있음
Why? 데이터의 삽입 삭제가 계속 되면서 노드의 분할, 병합등이 자주 일어남 혹은 단편화 현상 발생(삭제된 레코드의 인덱스 값 자리가 비게 되는 상태) → seek time이 증가하면서 성능 저하됨. → 이때 index rebuild 작업을 해줘야한다. (인덱스를 다시 생성하여 기존의 단편화가 많은 인덱스를 버리는 작업)
2. Hash indices
버켓의 범위 안에서 값이 일정하게 분배되어 있다. 이때 값이 할당되는 버켓은 hash function을 사용하여 결정한다.
이때 하나의 버켓은 하나의 디스크 블록이다.
Hash index를 사용하는 파일 구조 : Hash File Organization
- 발생하는 문제점? 버켓 공간이 꽉차는 경우!
-> 해결방법- overflow chaining : 특정 bucket이 꽉 차면 새로운 bucket을 생성하여 linked list로 연결
- open hashing : 특정 bucket이 꽉 차면 비어있는 다른 bucket에 삽입.
- 위에서 배운 방법들은 모두 static hashing (정적 해싱)방법이다.
static hashing은 데이터베이스가 계속 변하는 경우 적합하지 않음 (파일을 다시 재구성해야하는 문제 발생)
이 경우에는 dynamic hashing (동적 해싱) 방법을 사용한다.
ordered index와 hash index 중 뭐가 더 좋을까?
어떤 질의냐에 따라 달라진다.
- hash index가 더 좋은 경우
select A, B, C
FROM R
WHERE A = 20192643위 질의 처럼 동등 조건에서는 hash index를 사용하는 것이 좋음.
hash index는 평균 검색 시간이 DB 크기와 상관없이 상수 시간이 걸리기 때문
- ordered index가 더 좋은 경우
select A, B, C
FROM R
WHERE B <= 3000 AND B >= 6000위 질의 처럼 값의 범위를 구해야 하는 경우에는 ORDERED INDEX가 더 좋다.
3. Bitmap Indices
- array of bits
- designed for efficient querying on multiple keys.
- distinct value의 개수가 적을 경우 적용됨.
- ex : gender, country, state ...
- 테이블에 레코드는 0부터 시작해서 연속적으로 번호가 매겨져야함.
(특히 레코드가 고정 크기일 경우 쉽게 적용) - 릴레이션을 바탕으로 비트맵 인덱스를 생성.
- 장점 : 작은 공간 사용
인덱스 생성 및 삭제 in SQL
create index <index-name> on <relation-name>(<attribute-list>)
ex : create index std_index on school(student_id) : school 릴레이션의 student_id 컬럼을 index로 생성 (이때 index 이름은 std_index)
-
인덱스가 잘 생성되었는지 확인 방법
SHOW INDEX FROM 테이블
여기서 인덱스 타입(B-TREE)도 확인할 수 있다. -
인덱스 삭제 방법
DROP INDEX 인덱스 명 on 테이블 -
인덱스 재구성 방법 : 인덱스를 재구성 하면 기존의 단편화가 많은 인덱스를 버리게 된다.
ALTER INDEX 인덱스 명 REBUILD
인덱스 만드는 기준?
-
크기가 큰 테이블에 만들자. (크기가 작은 테이블에는 인덱스 X)
-
Cardinality가 높은 열에 만든다.
cardinality : 값의 분산도, 즉 특정 열에 대한 distinct한 값의 개수
ex) 운전면허증 번호 : 사람 마다 각기 다르게 부여 --> 높은 cardinality
성별 : 2개의 값 --> 낮은 cardinality
cardinality가 낮은 컬럼에 대해서는 인덱스 효과가 적다. -
Where절에 자주 사용되는 속성
-
조인에 자주 사용되는 속성
인덱스 작성이 역효과가 나는 때는?
인덱스를 사용한다고 무조건 좋은 것은 아니다.
1. 인덱스 갱신의 오버헤드로 갱신 처리의 성능이 떨어진다.
테이블에 새로운 데이터를 추가하거나(INSERT) 기존의 데이터에 대해 갱신(UPDATE) 및 제거(DELETE)가 실행되면 자동으로 인덱스 자신도 갱신되어야 한다. 이것 또한 오버헤드의 일종
2. 의도한 것과 다른 인덱스가 사용된다.
한 테이블에 인덱스가 많아지는 경우 옵티마이저도 수 많은 실행계획으로 해매게 된다.
즉 옵티마이저의 실행계획이 항상 만능은 아니라는 것이다.
+저장소 용량 소비 문제
요약
- 인덱스 순차 파일은 데이터베이스 시스템에 사용된 가장 오래된 인덱스 구조 중 하나. 검색 키 순서로 레코드를 빨리 검색하기 위해 레코드를 연속적으로 저장하고, 순서에 벗어나는 레코드는 link로 연결한다. 임의 액세스를 빨리하기 위해 인덱스 구조를 사용
- 검색 키의 정렬 순서가 릴레이션의 정렬 순서와 일치한다면, 그 검색 키에 대한 인덱스를 클러스터링 인덱스라고 한다.
일치 하지 않은 경우는 비클러스터링 인덱스 혹은 2차 인덱스라고 한다. 2차 인덱스는 클러스터링 인덱스의 검색 키가 아닌 검색 키를 사용하는 질의의 성능을 향상시킨다. 하지만 DB를 변경할 때 2차 인덱스도 같이 변경되어야 한다는 부담이 존재. - 인덱스 순차 파일 구조의 주요 단점은 파일이 증가함에 따라 성능이 감소하는 것. 이 문제를 해결하고자 B+ tree 인덱스 사용.
- 순차 파일 구조는 데이터를 위치시키기 위해 인덱스 구조를 요구한다. 하지만 해싱을 기초한 파일 구조는 원하는 레코드의 검색 키 값으로 함수를 계산함으로써 직접 데이터 항목의 주소를 찾게 해준다. 검색 키 값이 파일에 저장되는 시간을 정확히 모르기 때문에 검색 키 값을 버켓에 균등하고 임의적으로 할당하는 좋은 해시 함수를 선택해야 한다.
- 비트맵 인덱스는 distinct value 값을 매우 적게 가지는 속성에 대해 인덱스를 만들기 위한 매우 조밀한 표현을 제공함. 비트맵 상에서 교집합 연산은 매우 빠름. 이것은 다중 속성에 대한 질의 처리에 아주 유용
cf) MySQL과 오라클의 인덱스는 B-tree 형태로 관리한다.
