Shape Context
1. Theory
- 모양의 유사도 측정 & 점의 일치도 복원 방법
- basic idea : shape 윤곽에서 n개 점 뽑음
- shape에서 각 점 는 이 점을 다른모든 점에 연결해서 n-1개의 벡터를 얻는다. 이 벡터의 집합은 너무 자세하다.
- key idea : 상대적 위치 분포 - robust, compact, and higly discriminative descriptor
- 점 에 대해 남은 점 n-1개의 점의 relative coordinate의 coarse histogram은 다음과 같다.
-
위의 식은 의 shape context로 정의된다.
-
bin : log-polar space에 유일하게 얻어진다.
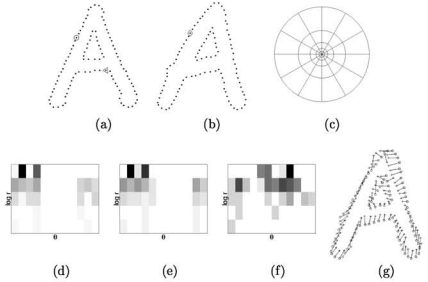
-
(a) & (b) : 두 shape의 edge point의 샘플
-
(c) : shape context를 계산하는데 사용된 log-polar bins의 diagram
-
(d) : (a)의 원에 표시된 점의 shape context
-
(e) : (b)에 다이아몬드로 표시된 점
-
(f) : (b)에서 삼각형 점
-
(d)-(e) : 유사, (f) : 다름
-
(g) histogram 사이의 거리의 cost를 이분매칭을 통한 일치
-
feature descriptor : translation, scaling, small perturbations에 invariance, application, rotation에 영향을 받는다.
-
translational invariance : 자명
-
scale invariance : shape에서 모든 점 쌍 사이의 평균거리 에의해 모든 radial distance를 정규화해서 얻어진다.
-
maching experiment 에서 만들어진 점 집합을 사용하면 경험적으로 deformation, noise, outliers에 robust하다.
-
Rotational invariance 방법 : 각 점에서 그 지점의 접선의 상대적 방향의 각도를 측정방법 ⇒ 회전에 완벽히 불변
-
같은 프레임에 상대적으로 측정되지 않으면 몇몇의 local features는 구별이 힘들어짐 ⇒ 항상 만족스럽진 x
-
ex) 6-9 구별
2. Details of implementation
Step 1: Finding a list of points on shape edges
- 가정 : 물체의 모양을 내외부의 윤곽의 점의 유한 부분집합을 통해 나타냄
- canny edge detector 와 edge 에서 점의 랜덤집합을 선택해 얻는다
- 이런 점은 최대곡률이나 변곡점 같은 키포인트와 일치하지 않는다
Step 2: Computing the shape context
- theory에 묘사된 방식
Step 3: Computing the cost matrix
- K-bin histogram의 g(k) & h(k) 를 정규화한 p & q 두 점을 고려한다.
- shape context는 히스토그램으로 분포를 표현한다. ⇒ Chi-squared test를 두 점을 매칭하는데 사용한다.
-
0~1 사이의 값
-
apperance를 기반으로한 extra cost가 더해질 수 있다.
-
위의 값은 & 의 단위벡터 사이의 단위원의 현의길이의 반이다. (0~1 값)
-
첫 번째 shape의 점 와 두 번째 shape의 점 에 대해 cost를 로 나타내고 이것을 cost matrix라 한다.
Step 4: Finding the matching that minimizes total cost
- 매칭의 cost를 최소화하는 와 를 1:1 매칭한다
- Hungarian algorithm 을 사용하면 시간이 걸린다.
Step 5: Modeling transformation
- 두 shape의 점의 유한집합 사이에서 일치집합에서 변형 는 임의의 한 점을 shape에서 다른 shape으로 매핑하는것이 추정가능하다. 아래의 변형 방법들이 있다.
- affine model의 표준 선택은 이다. 최소자승법의 행렬 A와 translational offset vector o는 다음의 과정을 통해 구한다.
Thin Plate Spline(TPS)
- 자주 사용되는 모델, 2D변형은 다음의 TPS함수로 나뉜다.
-
TPS는 두 shape의 정확한 대응 쌍을 요구한다. noisy data에 대해 정확성을 완화하는것이 좋다. 를 = 에 일치하는 목표함수값 이라 나타내면 를 최소화하는 요구량을 낮출 수 있다. ( 에 대해 는 에 대응하는 x축의 에 대응하고 는 마찬가지로 에 대응한다.
where, is the bending energy and is 정규화 매개변수,
-
는 scale에 불변이다. 정규화 매개변수는 정규화 되어야한다.
-
일치발견 & 추정변형을 반복하면(2~5단계) 문제점을 보완 가능하다.
Step 6: Computing the shape distance
- 두 모양 P와 Q 사이의 shape distance : 3potential term의 가중치의 합
- Shape context distance : 최적 매칭점을 넘는 shape context 매칭 cost의 symmetric sum, Tsms Q의 점을 P의 점에 매핑하는 estimated TPS 이다.
- Appearance cost : 이미지 일치와 1 image → 1 image의 적절한 warping 후 일치하는 이미지 포인트 주변의 가우시안 윈도우 에서 밝기제곱의 차의 합으로 apperance cost를 정의
-
where : grey-level image, : warping 후 이미지, G : 가우시안 윈도우 함수
-
Transformation cost : final cost 는 변형이 두 이미지를 배열하는데 얼마나 필요한가를 나타낸다. ex) TPS에서 bending energy
-
두 shape사이의 거리를 계산하는 방법에는 (k-NN)에서 정의된 거리를 사용한다
3. Results
- Digit recognition
- Silhouette similarity-based retrieval
- 3D object recognition
- Trademark retrieval
등에 사용
