
Jetpack Compose Internals를 읽고 내용을 정리하는 시리즈입니다.
이번 포스팅에서는 2장 Compose 컴파일러(The Compose compiler)를 다룹니다.
들어가며
이 책에서는 Jetpack Compose의 아래 세 구성 요소를 다룹니다.
- Compose 컴파일러
- Compose 런타임
- Compose UI
이 중 컴파일러와 런타임이 Compose의 핵심 엔진이며 UI는 엄밀히 말하면 Compose 아키텍처에 포함되지 않습니다.
컴파일러와 런타임은 UI뿐 아니라 어떤 클라이언트 라이브러리에서도 사용할 수 있도록 범용적으로 설계된 반면, Compose UI는 이 기술을 활용한 하나의 구현체일 뿐입니다.
또 다른 구현체 예시로는 JetBrains에서 개발 중인 데스크톱 및 웹용 라이브러리가 있습니다.
하지만 Compose UI를 분석해보면 Compose가 내부적으로 컴포저블 트리를 어떻게 메모리에 표현하고 이를 실제 화면으로 구체화하는지 이해하는 데 도움이 됩니다.
📍 Compose 컴파일러
개발자가 작성한 코드를 내부적으로 변형하기 위한 방법에는 여러가지가 있습니다.
보통 코틀린이나 자바에서는 KAPT(어노테이션 프로세서)를 주로 사용하지만,
이와 다르게 Jetpack Compose는 코틀린 컴파일러 플러그인 방식을 채택했습니다.
- KAPT : 컴파일이 시작되기 전에 별도로 실행
- 컴파일러 플러그인 : 컴파일 과정 한복판에서 직접 동작
컴파일러 플러그인의 장점
1. 더 빠른 에러 검출 (프론트엔드 단계)
컴파일러 플러그인을 사용하면 컴파일의 앞단인 프론트엔드 단계에서 오류를 검사할 수 있습니다.
이는 빌드 버튼을 누르자마자 매우 빠른 정적 분석으로 문제를 리포트해줄 수 있음을 의미합니다.
참고로, 안드로이드 스튜디오에서 코드를 치는 도중에 빨간 줄이 뜨는 건 IDE 전용 플러그인이 따로 처리하는 기능입니다. 하지만 실제 빌드를 돌렸을 때 수행되는 정밀한 검사는 이 컴파일러 플러그인이 담당합니다.
2. 소스 코드 변형 (IR 변환)
컴파일러 플러그인의 가장 강력한 무기는 소스 코드를 마음대로 수정할 수 있다는 점입니다.
기존 KAPT 방식은 새로운 파일을 생성할 수는 있어도, 개발자가 이미 작성한 코드를 건드릴 수는 없었습니다.
하지만 Compose 컴파일러는 IR(Intermediate Representation, 중간 표현) 단계에 개입합니다.
IR은 소스 코드가 기계어로 번역되기 전의 중간 단계인데 Compose는 이 단계에서 코드를 가로채서 수정합니다.
(e.g. Composable 함수에 Compose 런타임이 필요로 하는 정보(Composer 등)를 추가하는 작업)
+ ) KSP와 컴파일러 플러그인
코틀린 생태계는 KAPT에서 컴파일러 플러그인 방식으로 이동하고 있습니다.
다만, Compose처럼 코드를 직접 수정하는 방식(IR 변환)은 너무 강력해서 남용하면 언어 자체가 불안정해질 위험이 있습니다.
그래서 구글은 일반적인 라이브러리 개발자들에게는 KSP(Kotlin Symbol Processing) 사용을 권장합니다. KSP는 컴파일러 플러그인처럼 빠르지만, 코드를 수정하지는 못하고 새로운 코드를 생성하는 데 최적화된 안전하고 가벼운 방식입니다.
📍 Compose 어노테이션들 (Compose annotations)
Compose 어노테이션은 Compose 컴파일러가 소스 코드를 읽고 적절한 작업을 수행하도록 합니다.
1. 정적 분석을 통한 검증
컴파일러 플러그인은 어노테이션 프로세서(KAPT)보다 훨씬 강력하지만 시작점은 비슷합니다.
바로 정적 분석이라 불리는 검증 단계입니다.
Compose 컴파일러는 코틀린 컴파일러의 가장 앞단인 프론트엔드 단계에 개입해,
코드가 기계어로 변환되기 전에 문법적으로나 Compose의 규칙상으로 올바른지 검사합니다.
- 개발자가 작성한 코드가 Compose의 제약 사항을 잘 지키고 있는지 확인
- 일반 함수와 @Composable 함수를 명확히 구분하여 처리
- 타입 시스템이 올바르게 작동하는지 검증
2. 런타임 최적화
검증 외에도 어노테이션은 런타임 최적화를 위한 도구로 쓰입니다.
특정 어노테이션을 붙이면 런타임 성능을 높이거나 불필요한 계산을 건너뛰는 숏컷 기능을 활성화할 수 있습니다.
3. 어노테이션의 위치
모든 어노테이션은 Compose 컴파일러가 아닌 Compose Runtime 라이브러리에 정의되어 있습니다.
컴파일러는 코드를 변환하는 도구이고, 런타임은 실제 앱이 돌아갈 때 작동하는 엔진입니다.
@Composable
@Composable이 붙은 함수는 Compose 컴파일러에 의해 IR 변환 과정을 거치며 아래 특성들을 갖게 됩니다.
- 함수에 메모리 부여
타입이 변경된다는 것은 함수가 메모리(Memory)를 갖게 된다는 뜻입니다.
일반 함수는 실행되고 나면 모든 데이터가 사라지지만, Composable 함수는 Composer와 Slot Table이라는 구조를 통해 실행이 끝난 후에도 데이터를 기억할 수 있습니다.
이것이 바로 우리가 remember 같은 API를 사용할 수 있는 이유입니다.
- 생명주기를 갖고 식별 가능한 함수
메모리가 생긴 덕분에 Composable 함수는 생명주기(Lifecycle)를 가집니다.
또한 컴파일러가 부여한 고유 ID와 위치 정보를 통해 여러 번 재실행되더라도 트리 안에서 식별될 수 있습니다.
덕분에 이전 상태를 유지하거나 사이드 이펙트 작업을 이어서 수행할 수 있습니다.
- 함수의 실행 결과는 노드 방출
결국 Composable 함수의 최종 목표는 트리 구조에 들어갈 노드를 만드는 것입니다.
덕분에 이러한 트리 구조를 타고 전해져 내려오는 데이터(CompositionLocal)를 활용할 수도 있습니다.
일반적으로 ‘노드’는 UI를 그리기 위한 요소이지만 Compose 런타임은 범용적으로 설계되었기 때문에,
사용하는 라이브러리에 따라 UI가 아닌 다른 성격의 데이터 노드를 만들 수도 있습니다.
@ComposableCompilerApi
이 어노테이션은 사람을 위한 것이 아니라 컴파일러를 위한 것입니다.
개발자가 이 API를 직접 사용하면 예상치 못한 문제가 발생할 수 있으니 건드리지 말라는 경고 표시와 같습니다.
@InternalComposeApi
공개(public)되어 있어 코드상 접근할 수 있지만, 실제로는 내부용(internal)으로만 쓰여야 하는 API입니다.
코틀린의 internal 키워드는 같은 모듈 내에서만 접근을 허용합니다.
하지만 Compose는 여러 모듈로 쪼개져 있어서, 모듈 간에 데이터를 주고받으려면 어쩔 수 없이 public으로 열어둬야 하는 경우가 생깁니다.
이렇게 기술적으로는 열려있지만 언제든 내용이 바뀔 수 있으니 일반 개발자는 쓰지 말라고 표시해둔 것입니다.
@DisallowComposableCalls
이 어노테이션은 특정 람다 안에서 Composable 함수를 호출하지 못하게 막는 역할을 합니다.
이러한 어노테이션은 언제 유용할까요?
인라인 함수의 특성과 전염성
코틀린의 인라인 함수는 코드를 붙여넣는 방식으로 작동하므로 상위 컨텍스트의 능력을 그대로 물려받습니다.
그래서 ‘Composable 함수 안에서 호출된 인라인 함수’의 람다 안에서는 Composable 함수를 자유롭게 호출할 수 있습니다. (e.g. forEach)
하지만 remember처럼 특수한 경우에는 이를 차단해야 합니다.
remember 함수 안에서 Composable 호출 막기
remember { ... } 안에 있는 계산 블록은 처음에 딱 한 번만 실행되고, 그 결과를 저장합니다.
그 이후 화면이 다시 그려질 때(리컴포지션)는 이 블록을 다시 실행하지 않고 저장된 값을 꺼내 씁니다.
그런데 만약 이 블록 안에 UI를 그리는 Composable 함수가 들어있다면 어떻게 될까요?
- 첫 실행 때는 UI가 그려집니다.
- 화면이 갱신될 때는 블록이 실행되지 않으므로, 해당 UI는 갱신되지 않거나 사라져 버립니다.
- 결과적으로 트리의 구조가 꼬이고 오류가 발생합니다.
@Composable
inline fun <T> remember(calculation: @DisallowComposableCalls () ‑> T): T =
currentComposer.cache(false, calculation)그래서 위 remember의 calculation 블록처럼 한 번만 실행되거나 조건부로 실행되는 인라인 람다 안에는 @DisallowComposableCalls를 붙여 Composable 함수를 넣지 못하도록 막아야 합니다.
또한, 이 제약은 전염성이 있어서 이 람다 안에서 또 다른 인라인 람다를 호출한다면 그 람다 역시 똑같은 제약을 가집니다.
@ReadOnlyComposable
‘이 컴포저블 함수는 데이터를 읽기만하고 메모리의 UI 트리에 기록을 남기지 않는다’고 알립니다.
기록(Group)을 남기지 않음
Compose는 기본적으로 Composable 함수가 실행될 때마다 슬롯 테이블이라는 메모리 공간에 그룹(Group)이라는 영역을 만듭니다. 이 그룹은 ‘함수가 어디에 위치했는지’, ‘나중에 다시 그려야 할지’ 등을 추적합니다.
하지만 단순히 어떤 값을 계산해서 반환만 하는 함수라면, 이러한 과정을 생략해 비용을 줄일 수 있습니다.
@ReadOnlyComposable을 붙이면 컴파일러가 이 그룹 생성 코드를 생략하여 성능을 높입니다.
언제 사용하는가?
주로 값을 읽어오는 유틸리티 함수에 사용됩니다.
이러한 함수로 가져오는 값들은 프로그램을 실행할 때 단 한 번 설정된 이후로 쭉 유지되기 때문입니다.
Compose 라이브러리에서 읽기 전용으로 제공되는 Composable의 예시로는 LocalContext.current, isSystemInDarkTheme(), MaterialTheme.colors 등이 있습니다.
위 함수들은 모두 UI를 그리는 것이 목적이 아니라 이미 정해진 값을 가져오는 것이 목적입니다.
@NonRestartableComposable
이 어노테이션은 함수의 리컴포지션 능력을 제거해 코드를 가볍게 만드는 역할을 합니다.
대부분의 Composable 함수는 자신의 입력값이 바뀌면 부모가 시키지 않아도 알아서 리컴포지션됩니다.
이를 위해 컴파일러는 함수 내부에 변화를 감지하고 스스로를 재호출하는 코드를 심어놓습니다.
하지만 @NonRestartableComposable을 붙이면 컴파일러는 해당 함수에 리컴포지션을 위한 코드를 생성하지 않으며, 이 경우 함수는 자신을 호출하는 부모 함수가 다시 그려질 때만 리컴포지션됩니다.
이 어노테이션은 아주 드물게 사용되며 약간의 성능 최적화를 위한 수단으로 이해하면 됩니다.
일반적인 경우에는 굳이 사용할 필요가 없습니다.
@StableMarker
@StableMarker는 개발자가 직접 쓰는 어노테이션이 아니라,
다른 어노테이션(@Immutable, @Stable)을 만들기 위한 기반(Meta-annotation)입니다.
이 마커가 붙은 어노테이션을 사용한다는 것은 컴파일러에게 다음 세 가지 약속을 하는 것과 같습니다.
- 결과 보장:
equals()결과가 같다면 두 인스턴스는 완전히 똑같은 상태여야 합니다. - 변경 알림: 만약 내부 값이 바뀌면 Compose에게 이를 즉시 알려줘야 합니다.
- 속성 안정성: 이 객체가 가진 모든 공개(public) 속성들 또한 안정적이어야 합니다.
컴파일러는 기본적으로 코드를 분석해서 데이터의 안정성을 스스로 판단하려고 노력합니다.
하지만 컴파일러가 이를 판단하기 어려운 경우, 개발자가 안정적인 데이터임을 명시적으로 알려주기 위해 사용하는 것이 바로 아래 두 어노테이션입니다.
- @Immutable: 내용물이 절대 안 바뀜 (완전 불변)
- @Stable: 바뀌긴 하는데, 바뀌면 티를 냄 (관찰 가능한 가변성)
이를 적절히 사용하면 리컴포지션을 건너 뛰어(Skipping) 성능 최적화 혜택을 얻을 수 있습니다.
@Immutable
해당 데이터의 내용이 절대 바뀌지 않음을 명시적으로 알리는 어노테이션입니다.
왜 필요한가요?
Kotlin의 val 키워드만으로는 Compose 컴파일러에게 불변성을 완전히 보장할 수 없습니다.
val list = mutableListOf(...) 처럼 변수 자체는 재할당이 안 되어도 내용물은 바뀔 수 있기 때문입니다.
@Immutable을 붙이면 Compose는 값이 똑같다면 다시 그릴 필요 없다고 판단하여 리컴포지션을 생략합니다.
사용 조건
- 모든 속성이
val이어야 한다. - 커스텀
getter가 없어야 한다. (호출마다 다른 값을 반환할 수 있음) - 모든 프로퍼티가 원시 타입이거나
@Immutable이어야 한다.
@Stable
@Stable은 바뀔 수 있지만, 변경되면 반드시 알려주겠다는 조금 더 유연한 약속입니다.
함수의 파라미터가 모두 @Stable하다면 입력값이 같을 때 함수 실행을 건너뛰어 리컴포지션을 최적화 합니다.
언제 사용하는가?
- 클래스에 붙일 때
내부에MutableState처럼 변하는 값을 갖지만, 값이 변할 때 Compose에게 확실히 알리는 구조에서 사용 - 함수나 프로퍼티
같은 값을 넣으면 무조건 같은 결과가 나온다는 것을 보장
📍 Compose Compiler Plugin의 작동 방식
지금까지 Compose의 주요 어노테이션에 대해 살펴보았습니다.
이제는 Compose 컴파일러 플러그인이 실제로 어떻게 작동하는지, 또 앞서 배운 어노테이션들을 어떻게 처리하는지 알아볼 차례입니다.
1. 컴파일러 확장 등록 (Registering Compiler extensions)
Compose 컴파일러 플러그인은 가장 먼저 자기 자신을 Kotlin 컴파일러 파이프라인에 등록합니다.
구체적으로는 ComponentRegistrar의 일종인 ComposeComponentRegistrar가 여러 컴파일러 익스텐션을 등록하는데, 이들은 라이브러리 사용을 돕거나 런타임 구동에 필요한 코드를 생성하는 역할을 합니다.
이렇게 등록된 익스텐션들은 Kotlin 컴파일러가 돌 때 함께 실행됩니다.
또한 개발자가 직접 설정한 컴파일러 옵션에 따라 아래 기능들을 지원하는 익스텐션이 추가로 등록되기도 합니다.
- 라이브 리터럴(Live Literals) 기능 활성화
- 안드로이드 스튜디오 등 도구에서 컴포지션을 검사할 수 있도록 소스 정보 포함
- remember 함수에 대한 최적화 수행
- Kotlin 버전 호환성 검사 무시
- IR 변환 과정에서 미끼(decoy) 메서드 생성
컴파일러 익스텐션이 등록되는 구체적인 구현 코드가 궁금하다면 cs.android.com에서 오픈 소스 코드를 찾아볼 수 있습니다.
Kotlin 컴파일러 버전 (Kotlin Compiler version)
Compose 컴파일러는 특정 Kotlin 버전과 정확히 일치해야 작동합니다.
버전이 맞지 않으면 개발 자체가 불가능하므로, 가장 먼저 확인해야 할 필수 사항입니다.
suppressKotlinVersionCompatibilityCheck라는 옵션을 사용해 이 검사를 강제로 건너뛸 수도 있습니다.
하지만 이는 온전히 개발자가 위험을 감수해야 하는 방법입니다.
Kotlin 컴파일러의 백엔드는 빠르게 변화하고 있어, 버전이 맞지 않으면 알 수 없는 컴파일 오류가 발생할 확률이 매우 높기 때문입니다. 아마도 이 옵션은 정식 출시 전의 실험적인 Kotlin 버전을 미리 테스트해보려는 목적으로 만들어졌을 것입니다.
2. 정적 분석 (Static analysis)
컴파일러 플러그인이 등록된 뒤 수행하는 작업은 바로 린팅(Linting), 즉 정적 분석입니다.
이 단계에서는 소스 코드를 스캔해 Compose 관련 어노테이션이 런타임에서 기대하는 방식대로 올바르게 사용되었는지 검사합니다.
이때 발견된 경고나 오류는 IDE 플러그인과 연동되어 코드를 작성하는 즉시 인라인으로 표시됩니다.
중요한 점은 이 모든 검증 과정이 컴파일러의 프론트엔드(frontend) 단계에서 처리된다는 것입니다.
덕분에 개발자는 문제가 발생했을 때 매우 빠르게 피드백을 받을 수 있습니다.
+ 정적 검사기 (Static Checkers)
Compose는 코드 작성 시 개발자의 실수를 바로잡아 주는 정적 검사기들을 익스텐션 형태로 등록합니다.
이들은 함수 호출, 타입, 선언 등을 감시하며 라이브러리를 올바르게 사용하고 있는지 확인합니다.
예를 들면, 1장에서 다룬 Composable 함수의 제약 사항들을 어겼을 때 이를 즉시 감지하고 IDE에 오류를 띄우는 것입니다.
Kotlin 컴파일러는 클래스 생성, 타입, 함수 호출, 클로저 캡처, 코루틴, 연산자 호출 등 다양한 요소를 검사할 수 있는 분석 도구들을 제공합니다. 컴파일러 플러그인은 이를 활용해 소스 코드를 정밀하게 분석하고 경고나 오류를 보고합니다.
이 모든 검사기는 컴파일러의 프론트엔드 단계에서 실행되므로 속도가 매우 빠릅니다.
개발자가 코드를 타이핑하는 도중에 실시간으로 확인해야 하므로 CPU를 많이 소모하지 않도록 가볍게 설계되어 있습니다. 만약 검사 과정이 무겁다면 코드를 입력할 때마다 IDE가 버벅거리는 좋지 않은 사용자 경험을 주게 될 것입니다.
이어서 정적 분석 단계에서 수행되는 주요 정적 검사 기능들을 소개합니다.
호출 검사 (Call checks)
Compose 컴파일러는 Composable 함수가 잘못된 위치에서 호출되지 않도록 검사하는 역할도 합니다.
이를 호출 검사라고 합니다.
1. Visitor Pattern
컴파일러는 PSI라고 불리는 코드의 구조 트리(나무)를 하나하나 방문하면서 검사를 수행합니다.
쉽게 말해, 소스 코드의 모든 줄과 모든 요소를 빠짐없이 훑어본다는 뜻입니다.
2. Context Trace
단순히 현재 줄만 봐서는 이 코드가 유효한지 알 수 없을 때가 많습니다.
예를 들어 Text("Hello")라는 코드는 그 자체로는 문제없지만,
만약 이 코드가 try-catch 블록 안에 있거나, 일반 함수 안에 있다면 에러입니다.
그래서 컴파일러는 전체적인 맥락을 파악하기 위해 컨텍스트 추적(Context Trace) 기술을 사용합니다.
(e.g. 지금은 try 블록 안에 들어왔음, 지금은 @DisallowComposableCalls 람다 안에 있음)
덕분에 특정 위치에서 Composable 함수를 만났을 때 기록해 둔 문맥을 확인하고 여기서는 Composable을 호출하면 안된다는 에러를 띄울 수 있습니다.
아래는 @DisallowComposableCalls로 마킹된 컨텍스트에서 Composable 함수가 호출될 때 관련
정보를 컨텐스트 추적을 통해 기록하고, 이를 사용하여 오류를 보고하는 컴파일러 호출의 예시입니다.
if (arg?.type?.hasDisallowComposableCallsAnnotation() == true) {
// 이 함수(descriptor)는 Composer를 캡처할 수 있나(LAMBDA_CAPABLE...)? -> 아니오(false)
context.trace.record(
// 1. 어떤 종류의 정보인가? (Slice/Key)
ComposeWritableSlices.LAMBDA_CAPABLE_OF_COMPOSER_CAPTURE,
// 2. 어떤 코드 요소에 붙일 것인가? (Key가 되는 대상)
descriptor,
// 3. 값은 무엇인가? (Value)
false
)
context.trace.report(
ComposeErrors.CAPTURED_COMPOSABLE_INVOCATION.on(
reportOn,
arg,
arg.containingDeclaration
)
)
return
}3. 주요 검사 항목들
컴파일러는 이 기술을 활용해 다음과 같은 상황들을 잡아냅니다.
- 금지 구역
try-catch나@DisallowComposableCalls가 붙은 람다에서는 Composable을 호출할 수 없습니다. - 인라인 함수
인라인 람다의 경우 자신을 감싸는 부모 함수가 Composable인지 확인하여 호출 가능 여부를 판단합니다. - 어노테이션 누락
만약 람다 안에서 Composable 함수를 호출했는데 람다 자체에는@Composable이 없다면,
개발자에게 @Composable을 붙일 것을 제안합니다. - 읽기 전용 규칙
@ReadOnlyComposable함수 안에서는 또 다른@ReadOnlyComposable함수만 호출할 수 있습니다.
데이터를 쓰지 않는다는 약속 안에서 데이터를 쓰는 일반 Composable 함수를 부르면 안 되기 때문입니다. - 참조(Reference) 검사
Composable 함수를 직접 호출하지 않고 함수 참조(::functionName) 형태로 사용할 때도
Compose가 지원하지 않는 방식이면 차단합니다.
타입 검사 (Type checks)
Compose 컴파일러는 함수 호출뿐만 아니라 데이터의 타입(Type) 자체에 대해서도 검사를 수행합니다. 이를 타입 추론 검사라고 합니다.
컴파일러는 코드를 분석할 때 @Composable 어노테이션이 붙은 타입을 예상했는데 실제로는 일반 타입이 들어오거나, 그 반대의 경우를 찾아내어 오류를 보고합니다.
이때 오류 메시지에 추론된 타입과 예상되는 타입을 명확히 보여주어 개발자가 차이점을 쉽게 파악할 수 있게 돕습니다.
선언 검사 (Declaration checks)
뿐만 아니라 Compose 컴파일러는 요소가 어디에 선언되었는지도 검사합니다.
검사 대상은 프로퍼티, 접근자(Getter/Setter), 함수 선언, 매개변수 등 코드베이스 전반에 걸쳐 있습니다.
주요 검사 항목은 다음과 같습니다.
- 재정의(Override) 일관성
상속 관계에서 부모 클래스의 함수나 프로퍼티가@Composable이라면, 이를 재정의(Override)하는 자식 클래스의 요소도 반드시@Composable이어야 합니다. - Suspend 호환 불가
@Composable함수는 suspend 키워드와 함께 사용할 수 없습니다.
두 개념의 동작 방식과 목적이 완전히 다르기 때문에 현재 기술적으로 함께 지원되지 않습니다. - Main 함수 금지
프로그램의 시작점인 main 함수는@Composable이 될 수 없습니다. - Backing Field 금지
@Composable프로퍼티는 내부적으로 상태를 저장하는 Backing Field를 가질 수 없습니다.
진단 억제 (Diagnostic Suppression)
컴파일러 플러그인은 코틀린 컴파일러가 에러라고 표시할 상황을 에러가 아닌 것으로 처리하는 권한을 가집니다.
이를 진단 억제(Diagnostic Suppression)라고 합니다.
Compose 컴파일러는 ComposeDiagnosticSuppressor로 언어적 제약을 우회하여 Compose만의 특별한 기능을 활성화합니다.
1. 인라인 람다의 어노테이션 허용
코틀린은 인라인 람다에 런타임/바이너리용 어노테이션을 붙이면 저장할 곳이 없다는 에러를 냅니다.
코틀린에서 인라인 람다는 컴파일 시 호출하는 곳의 코드로 그대로 복사되어 들어가므로,
런타임이나 바이너리 단계에서 어노테이션을 저장할 대상(객체) 자체가 사라지기 때문입니다.
@Target(AnnotationTarget.FUNCTION)
annotation class FunAnn
inline fun myFun(a: Int, f: (Int) -> String): String = f(a)
fun main() {
// 에러 발생: 해당 람다식은 인라인 된 매개변수이므로, 이 어노테이션은 어디에도 저장할 수 없습니다.
myFun(1) @FunAnn { it.toString() }
}하지만 Compose 컴파일러는 이 에러를 억제할 수 있습니다.
덕분에 개발자는 함수를 호출하는 시점(Call site)에 람다에 @Composable을 붙일 수 있습니다.
이렇게 하면 함수를 정의할 때가 아니라 사용할 때 유동적으로 람다를 Composable로 만들 수 있어 API 설계가 훨씬 유연해집니다.
@Composable
inline fun MyComposable(@StringRes nameResId: Int, resolver: (Int) -> String) {
val name = resolver(nameResId)
Text(name)
}
@Composable
fun Screen() {
// Compose 컴파일러 덕분에 호출 시점에 @Composable을 붙이는 것이 허용됩니다.
MyComposable(nameResId = R.string.app_name) @Composable {
LocalContext.current.resources.getString(it)
}
}2. 함수 타입의 매개변수 이름 사용 (Named Arguments)
코틀린에서는 함수 타입을 사용할 때 인자에 이름을 붙여서 호출하는 것을 허용하지 않습니다.
예를 들어 func(value = 1)처럼 호출하는 것이 일반 함수에서는 되지만, 람다 변수 호출 시에는 제한됩니다.
하지만 Compose 컴파일러는 해당 함수 타입이 @Composable로 지정되어 있다면 이 제약을 풉니다.
덕분에 아래처럼 path = path처럼 매개변수 이름을 명시하여 가독성 좋게 호출할 수 있습니다.
interface FileReaderScope {
fun onFileOpen(): Unit
fun onFileClosed(): Unit
fun onLineRead(line: String): Unit
}
object Scope : FileReaderScope {
override fun onFileOpen() = TODO()
override fun onFileClosed() = TODO()
override fun onLineRead(line: String) = TODO()
}
@Composable
fun FileReader(path: String, content: @Composable FileReaderScope.(path: String) -> Unit) {
Column {
//...
// 일반 코틀린이라면 "함수 유형에는 매개변수에 명명하는 것이 허용되지 않습니다"라는 에러가 뜹니다.
// 하지만 @Composable 함수 타입이므로 허용됩니다.
Scope.content(path = path)
}
}- 멀티플랫폼 지원 (Expect/Actual)
Jetpack Compose는 멀티플랫폼을 지향하므로, 코틀린 멀티플랫폼의 expect 키워드가 붙은 함수나 프로퍼티에도 @Composable을 붙일 수 있도록 관련 제약을 해제하여 허용합니다.
런타임 버전 검사 (Runtime version check)
코드 생성 직전에 사용된 Compose 런타임(Runtime)의 버전을 확인합니다.
Compose 컴파일러는 자신이 지원하는 런타임의 최소 버전 요구사항을 가지고 있습니다.
따라서 현재 사용 중인 런타임이 너무 오래된 버전은 아닌지, 런타임 자체가 누락되지는 않았는지 확인합니다.
이 버전 검사는 컴파일 과정에서 두 번째로 수행되는 검사입니다.
첫 번째는 코틀린 컴파일러 자체의 버전을 검사하는 것이고, 그 다음으로 이 Compose 런타임 버전 검사가 수행됩니다.
3. 코드 생성 (Code generation)
검사가 끝나면 Compose 컴파일러는 코드 생성 단계로 진입합니다.
이는 어노테이션 프로세서와 컴파일러 플러그인의 공통된 특징이기도 한데, 둘 다 런타임 라이브러리가 가져다 쓸 수 있도록 편리한 코드를 생성하거나 합성하는 데 자주 활용되기 때문입니다.
코틀린 IR (The Kotlin IR)
1장에서 앞서 살펴보았듯 컴파일러 플러그인은 언어의 중간 표현(IR)에 접근할 수 있습니다.
Compose 컴파일러는 기존 IR을 가로채서 변경을 가한 뒤, 변형된 IR 기반으로 최종 코드를 생성합니다.
Composable 함수에 암시적 매개변수 Composer를 주입하는 등의 변형이 바로 이 IR 단계에서 수행됩니다.
만약 JVM만 목표로 한다면 자바 호환 바이트코드만 생성해도 충분하지만, 최근 코틀린 팀은 모든 플랫폼을 위한 백엔드를 하나로 통합하고 IR 백엔드를 안정화하는 방향으로 나아가고 있습니다.
IR은 목표 플랫폼이 무엇이든 상관없이 언어 요소를 표현하는 중간 표현으로 존재합니다.
즉, IR 생성은 Jetpack Compose가 만들어내는 코드가 멀티플랫폼으로 확장될 가능성을 의미합니다.
실제로 Compose 컴파일러 플러그인은 코틀린 컴파일러의 공통 IR 백엔드에서 제공하는 IrGenerationExtension의 구현체를 등록하는 방식으로 IR을 생성합니다.
코틀린 IR을 깊이 있게 공부하는 것은 이 책의 범위를 벗어나며 추가 학습을 원한다면 코틀린 IR과 컴파일러 플러그인 생성 전반을 다루는 Brian Norman의 글을 확인해 보시길 권장합니다.
낮추기 (Lowering)
Lowering은 컴파일러에서 흔히 사용되는 용어입니다.
이는 복잡한 고수준 프로그래밍 개념을 단순한 저수준 원자적 개념 조합으로 변환하는 작업을 말합니다.
코틀린 컴파일러도 이 방식을 사용합니다. 코틀린 IR은 매우 고수준의 개념을 담고 있습니다.
따라서 JVM 바이트코드, 자바스크립트, LLVM의 IR 등으로 변환하려면 일종의 코드 정규화 과정을 거쳐 저수준 형태로 변환되어야 합니다.
Compose 컴파일러 플러그인도 코드 생성 단계에서 Lowering을 수행합니다.
Compose 라이브러리의 개념을 런타임이 이해할 수 있는 형태로 변환하고 정규화하는 것입니다.
이 과정에서 컴파일러는 IR 트리의 모든 엘리먼트를 순회하며 런타임의 요구 사항에 맞게 코드를 조정합니다.
Lowering 단계에서 수행하는 주요 작업
- 클래스 안정성(Stability) 추론 : 런타임이 이해할 수 있도록 안정성 관련 메타데이터 추가
- 라이브 리터럴(Live Literals) : 소스 코드의 리터럴 표현식을 가변 상태(State) 인스턴스에 접근하도록 변환, 이를 통해 재컴파일 없이도 코드 변경 사항을 런타임에 반영 가능
- composer 주입 : Composable 함수에 암시적 매개변수 Composer를 추가하고 모든 호출에 전달
- Composable 함수의 본문을 래핑해 아래 작업 수행
- 상태 변경 정보를 트리 하위로 전파해 상태가 변할 때 자동으로 재구성이 일어나도록 처리
- 코틀린의 기본 매개변수 기능을 대신해 생성된 그룹 내에서 동작하는 별도의 기본 매개변수 지원
- 제어 흐름 처리를 위한 다양한 그룹 생성(교체 가능한 그룹, 이동 가능한 그룹 등)
- 함수가 스스로 리컴포지션을 건너뛸 수 있도록 처리
클래스 안정성 추론 (Inferring class stability)
스마트 리컴포지션은 아래 두 경우를 만족한다고 판단될 때 리컴포지션을 건너뛰는 기능입니다.
- Composable의 입력값이 변경되지 않음
- 모든 입력값이 안정적(Stable)임
여기서 입력값이 안정적이라는 것은 런타임이 해당 값을 안전하게 읽고 비교할 수 있다는 뜻입니다.
즉, 안정성의 궁극적인 목적은 런타임의 최적화를 돕는 것입니다.
안정적인 타입이 되기 위해서는 아래 조건들을 충족해야 합니다.
- 두 인스턴스에 대해 equals 함수를 호출했을 때 동일한 인스턴스라면 항상 동일한 결과를 반환해야 합니다.
런타임은 이 일관성에 의존합니다. - 특정 타입의 공개 프로퍼티가 변경되면 Composition이 그 변경 사항을 항상 통지받아야 합니다.
그렇지 않으면 Composable의 입력값과 실제 화면에 반영되는 상태 사이에 불일치가 발생할 수 있습니다.
스마트 리컴포지션은 이런 불확실한 입력값에 의존할 수 없으므로, 통지 기능이 없다면 무조건 재구성을 수행합니다. - 모든 공개 프로퍼티가 원시 타입이거나 안정적인 타입이어야 합니다.
String을 포함한 모든 원시 타입과 함수형 타입은 기본적으로 안정적인 타입으로 간주됩니다.
이들은 정의상 불변(Immutable)이므로 값이 변하지 않기 때문에 변경 사실을 알릴 필요가 없습니다.
안정성 어노테이션과 추론 메커니즘
불변 타입이 아니더라도 Compose가 안정적이라고 가정하는 타입이 있습니다.
대표적으로 MutableState가 있으며, 이런 타입에는 @Stable 어노테이션을 붙일 수 있습니다.
MutableState는 값이 바뀔 때마다 Compose에 알림을 보내므로 스마트 리컴포지션을 사용하기에 안전합니다.
개발자가 만든 커스텀 타입의 경우, 앞서 언급한 조건들을 준수한다면 수동으로 @Immutable이나 @Stable 어노테이션을 붙여 안정적인 타입으로 표시할 수 있습니다. 하지만 개발자가 이 규칙을 완벽하게 지키는 것은 어렵고 실수하기 쉽습니다. 그래서 Compose는 개발자의 판단에 맡기기보다 컴파일러가 직접 클래스의 안정성을 추론하는 방식을 사용합니다.
Compose 컴파일러는 모든 클래스를 순회하며 안정성을 분석하고, 그 결과로 @StabilityInferred라는 어노테이션을 합성해 넣습니다. 또한 클래스 내부에 static final int $stable이라는 합성 필드를 추가하여 안정성 정보를 인코딩합니다. 이 값은 런타임에 클래스의 안정성을 판단하는 근거가 되며, 이를 통해 Compose는 재구성을 건너뛸지 말지를 결정합니다.
단, 모든 클래스가 추론 대상이 되는 것은 아닙니다. 열거형(Enum), 인터페이스, 어노테이션, 익명 객체, expect 요소, 이너 클래스, 컴패니언 클래스, 인라인 클래스 등은 제외됩니다.
또한 이미 @Stable이나 @Immutable 어노테이션이 붙은 클래스도 추론하지 않습니다.
즉, 주로 데이터 모델로 사용되는 일반 클래스나 데이터 클래스가 추론의 대상이 됩니다.
안정성 추론의 기준
Compose는 여러 요소를 고려해 안정성을 추론합니다. 기본적으로 클래스의 모든 필드가 읽기 전용(val)이고 그 필드들의 타입이 안정적이라면, 해당 클래스는 안정적인 것으로 추론됩니다.
여기서 필드는 JVM 바이트코드 관점의 필드를 말합니다.
예를 들어 class Foo나 class Foo(val value: Int)는 필드가 없거나 안정적인 필드만 있으므로 안정적인 타입입니다. 반면 class Foo(var value: Int)는 변수(var)가 있으므로 불안정한 타입으로 추론됩니다.
제네릭 타입 매개변수도 안정성 추론에 영향을 줍니다. 아래 예시를 보겠습니다.
class Foo<T>(val value: T)여기서 T는 클래스 매개변수로 사용되므로, Foo의 안정성은 T에 들어오는 실제 타입의 안정성에 따라 달라집니다. 하지만 컴파일 시점에는 T가 무엇인지 알 수 없습니다. 그래서 Compose 컴파일러는 런타임에 T의 안정성을 확인하여 Foo의 안정성을 결정하도록, StabilityInferred 어노테이션에 비트마스크를 계산해 넣습니다.
하지만 제네릭이 있다고 해서 무조건 불안정한 것은 아닙니다.
예를 들어 class Foo<T>(val a: Int, b: T) { val c: Int = b.hashCode() }의 경우, b가 프로퍼티로 저장되지 않고 생성 시점에만 사용된다면 컴파일러는 이를 안정적이라고 판단할 수 있습니다.
Foo(val bar: Bar, val bazz: Bazz)처럼 다른 클래스를 포함하는 복합 클래스의 경우,
모든 매개변수의 안정성을 재귀적으로 확인하여 전체 안정성을 결정합니다.
내부 상태와 안정성
클래스 내부에서만 사용하는 가변 상태가 있어도 클래스는 불안정해집니다.
class Counter {
private var count: Int = 0
fun getCount(): Int = count
fun increment() { count++ }
}count는 private 변수지만 시간이 지남에 따라 값이 변합니다. 이는 Compose 런타임 입장에서 getCount()의 결과가 일관되지 않음을 의미하므로, 이 클래스는 불안정한 타입이 됩니다.
인터페이스와 컬렉션의 안정성 문제
Compose 컴파일러는 확실하게 증명된 것만 안정적이라고 간주합니다.
인터페이스는 어떤 구현체가 들어올지 알 수 없으므로 기본적으로 불안정하다고 가정합니다.
@Composable
fun <T> MyListOfItems(items: List<T>) {
// ...
}위 코드에서 List는 인터페이스이며 실제로는 가변적인 ArrayList가 들어올 수도 있습니다.
컴파일러 입장에서는 불변 리스트만 들어온다고 보장할 수 없기 때문에 List 타입을 불안정하다고 판단합니다.
또한 클래스의 프로퍼티가 인터페이스 타입인 경우,
컴파일러는 실제 구현체가 항상 불변임을 확신할 수 없어 불안정한 타입으로 처리합니다.
이 경우 개발자가 해당 타입이 안전함을 확신한다면 @Stable을 붙여 컴파일러의 추론을 덮어쓸 수 있습니다.
아래는 공식 문서의 예시입니다.
// Marking the type as stable to favor skipping and smart recompositions.
@Stable
interface UiState<T : Result<T>> {
val value: T?
val exception: Throwable?
val hasError: Boolean
get() = exception != null
}이 외에도 안정성 추론 알고리즘은 다양한 케이스를 다룹니다.
더 깊이 알고 싶다면 Compose 컴파일러 라이브러리의 ClassStabilityTransform 유닛 테스트를 살펴보세요.
라이브 리터럴 활성화 (Enabling live literals)
*주의: 이 섹션은 내부 구현에 대한 내용으로, 향후 더 효율적인 방식이 발견되면 변경될 수 있습니다.*
라이브 리터럴이란?
코드를 다시 컴파일하지 않고도 Preview에서 변경 사항을 즉시 확인할 수 있게 해주는 기능입니다.
원리는, Compose 컴파일러가 코드 내의 상수(리터럴) 표현식을 MutableState에서 값을 읽어오는 형태로 변환하는 것입니다. 덕분에 런타임은 값이 바뀌어도 전체를 다시 빌드할 필요 없이 즉시 변경을 감지할 수 있습니다.
단, 라이브러리 문서(KDoc)는 다음과 같이 경고합니다.
이 변환은 오직 개발 편의성을 위한 것입니다. 성능에 민감한 코드의 실행 속도를 크게 떨어뜨릴 수 있으므로 릴리스 빌드에서는 절대로 활성화해서는 안 됩니다.
라이브 리터럴의 작동 방식
Compose 컴파일러는 상수가 사용된 파일마다 LiveLiterals$클래스명 형태의 싱글톤 클래스를 만듭니다.
이 클래스 안에 각 상수에 대한 고유 ID를 부여하고, getter를 통해 값을 가져오도록 코드를 바꿉니다.
다음 예시를 통해 일반적인 Composable 함수가 어떻게 변환되는지 살펴보겠습니다.
@Composable
fun Foo() {
print("Hello World")
}위의 코드는 컴파일러를 거치면 아래와 같이 변형됩니다.
@Composable
fun Foo() {
print(LiveLiterals$FooKt.getString$arg-0$call-print$fun-Foo())
}
object LiveLiterals$FooKt {
var String$arg-0$call-print$fun-Foo: String = "Hello World"
var State$String$arg-0$call-print$fun-Foo: MutableState<String>? = null
fun getString$arg-0$call-print$fun-Foo(): String {
val field = this.String$arg-0$call-print$fun-Foo
val state = if (field == null) {
val tmp = liveLiteral(
"String$arg-0$call-print$fun-Foo",
this.String$arg-0$call-print$fun-Foo
)
this.String$arg-0$call-print$fun-Foo = tmp
tmp
} else field
return field.value
}
}컴파일러가 생성한 LiveLiterals 싱글톤 클래스와 그 내부의 MutableState 프로퍼티가 가진 getter 함수를 보면, 단순했던 문자열 상수가 복잡한 상태 읽기 로직으로 바뀐 것을 확인할 수 있습니다.
Compose 람다식 기억법 (Compose lambda memoization)
컴파일러는 Composable 함수에 매개변수로 전달되는 람다식의 실행을 최적화하기 위해 IR을 생성합니다.
이 최적화의 목적은 전달된 람다식을 매번 새로 생성하지 않고 재사용하기 위함입니다.
대상이 되는 람다식은 크게 두 종류입니다.
- Composable이 아닌 람다 (Non-composable lambdas)
일반적인 콜백 함수를 의미합니다. 컴파일러는 이 람다식을 remember로 감싸 슬롯 테이블(Slot Table)에 저장하고 재사용할 수 있는 IR을 생성합니다. - Composable 람다 (Composable lambdas)
Compose UI 노드에 전달되는 Composable 람다식의 본문이 여기에 해당됩니다.
이 람다식 또한 최적화를 위해 IR이 생성되며, remember를 사용하지는 않지만 결과적으로 remember를 사용하는 것과 비슷한 효과를 냅니다.
1. Composable이 아닌 람다식 (Non‑composable lambdas)
Kotlin 컴파일러는 기본적으로 외부 변수를 캡처(capture)하지 않는 람다식은 싱글톤으로 만들어 앱 전체에서 재사용합니다. 하지만 람다식이 외부 변수를 캡처하는 경우에는 이 최적화가 불가능합니다.
캡처된 변수 값이 호출 때마다 달라질 수 있으므로 매번 새로운 객체를 생성해야 하기 때문입니다.
Compose는 이런 상황을 더 효율적으로 처리합니다. 아래 예시를 보겠습니다.
@Composable
fun NamePlate(name: String, onClick: () -> Unit) {
// ...
// onClick()
// ...
}여기서 onClick은 일반적인 Kotlin 람다입니다.
만약 이 람다가 외부 변수를 캡처한다면, Compose 컴파일러는 런타임에 이 람다를 기억(memoization)하라고 지시합니다. 즉, remember 함수로 람다식을 감싸는 코드를 생성합니다.
이때 캡처된 변수들이 stable하다면, 이 값들을 키(key)로 사용하여 람다를 캐싱합니다.
입력받은 키 값이 이전과 같다면 기존 람다를 재사용하고, 키 값이 바뀌면 그때 새로운 람다를 생성합니다.
따라서 캡처된 값은 비교 가능하고 신뢰할 수 있어야 합니다.
참고로 이렇게 기억된 람다는 인라인(inline)될 수 없습니다.
인라인은 컴파일 타임에 코드가 복사되는 것이므로 런타임에 기억할 대상이 없어지기 때문입니다.
이 최적화는 외부 변수를 캡처하는 람다식에만 적용됩니다.
캡처하지 않는 람다는 앞서 말한 Kotlin의 기본 최적화(싱글톤)만으로도 충분하기 때문입니다.
정리하자면,
컴파일러는 람다식이 캡처한 변수들의 타입과 개수에 맞춰 적절한 remember 호출 코드를 생성합니다.
- 캡처된 값들을 remember의 인자(키)로 전달합니다.
- 마지막 인자로 람다식 본문을 전달합니다.
- 결과적으로
remember(arg1, arg2...) { lambda }형태가 되어
캡처된 값이 변경될 때만 람다가 갱신됩니다.
이렇게 람다식을 자동으로 기억해 두면,
불필요한 객체 생성을 막고 리컴포지션이 발생할 때 해당 람다를 효율적으로 재사용할 수 있습니다.
2. Composable 람다식 (Composable lambdas)
Compose 컴파일러는 Composable 람다식도 기억(Memoization)합니다.
내부 구현 방식에 약간의 차이는 있지만, 람다식을 슬롯 테이블에 저장하고 필요할 때 읽어온다는 근본적인 목표는 Composable이 아닌 람다식과 동일합니다.
다음은 기억되는 Composable 람다식의 예시입니다.
@Composable
fun Container(content: @Composable () -> Unit) {
// ...
// content()
// ...
}이 코드를 처리하기 위해 컴파일러는 람다식의 IR(중간 표현)을 수정해 composableLambda(...)라는 팩토리 함수를 호출하도록 변경합니다. 이 함수에는 다음과 같은 특수한 매개변수들이 전달됩니다.
$composer
현재 컴포지션 컨텍스트입니다.$key
람다식의 고유성을 보장하기 위한 키입니다. 람다의 해시코드와 소스 코드상의 위치를 조합해 생성하며, 위치 기억법(Positional Memoization)에 사용됩니다.$shouldBeTracked
변경 추적 여부를 결정하는 Boolean 값입니다.
캡처하는 값이 없는 람다식은 변경될 일이 없으므로 추적할 필요가 없습니다.$arity(선택)
매개변수가 22개를 넘을 때만 사용됩니다.- expression
마지막으로 람다식 본문 자체가 전달됩니다.
결과는 composableLambda($composer, $key, $shouldBeTracked, $arity, expression) 형태가 됩니다.
이 팩토리 함수의 목적은 생성된 키를 사용해 컴포지션 내에 교체 가능한 그룹(Replaceable Group)을 추가하는 것입니다. 이를 통해 런타임은 Composable 람다식을 저장하고 검색할 수 있게 됩니다.
최적화 과정
1. 싱글톤 최적화 (ComposableSingletons)
’캡처하는 값이 없는 Composable 람다식’은 일반 Kotlin 람다처럼 싱글톤으로 최적화됩니다.
컴파일러는 파일마다 ComposableSingletons라는 내부 객체를 만들고, 여기에 람다식에 대한 정적 참조를 보관하여 재사용합니다.
2. 상태 객체 변환과 도넛 홀 건너뛰기 (Donut-hole skipping)
가장 중요한 최적화는 Composable 람다식을 내부적으로 MutableState와 유사하게 취급한다는 점입니다.
예를 들어 @Composable (A, B) -> C 타입의 람다는 State<@Composable (A, B) -> C>와 동등하게 구현된 것으로 볼 수 있습니다.
즉, 람다를 호출하는 것은 사실상 해당 상태 값을 읽어서 실행(invoke)하는 것과 같습니다.
이 구조 덕분에 도넛 홀 건너뛰기(Donut-hole skipping)라는 최적화가 가능해집니다.
보통 람다식은 상위 컴포넌트에서 정의되어 하위 컴포넌트로 전달됩니다. 이때 람다식 자체가 변경되면 이를 전달받는 모든 중간 컴포넌트가 리컴포지션 되어야 할 것 같지만, Compose는 그렇지 않습니다.
람다식은 상태 객체로 래핑되어 있기 때문에, 람다의 내용이 바뀌더라도 이를 전달만 하는 중간 컴포넌트들은 영향을 받지 않습니다. 오직 그 람다를 실제로 호출하여 값을 읽는 최하위 노드에서만 리컴포지션이 발생합니다.
이는 데이터가 계층 구조의 깊은 곳까지 전달되지만 중간 단계에서는 사용되지 않는 패턴에서 불필요한 렌더링을 막아주는 매우 효율적인 최적화입니다.
$composer 주입하기 (Injecting the Composer)
Compose 컴파일러는 모든 Composable 함수에 Composer라는 매개변수를 추가합니다.
이 매개변수는 트리의 모든 지점에서 접근할 수 있어야 하므로 Composable 람다식을 포함해 모든 Composable 함수에 전달됩니다.
컴파일러 플러그인이 Composer 매개변수를 추가하면 함수의 형태(signature)가 바뀌기 때문에,
이에 맞춰 타입을 재정의하는 작업도 함께 이루어집니다.
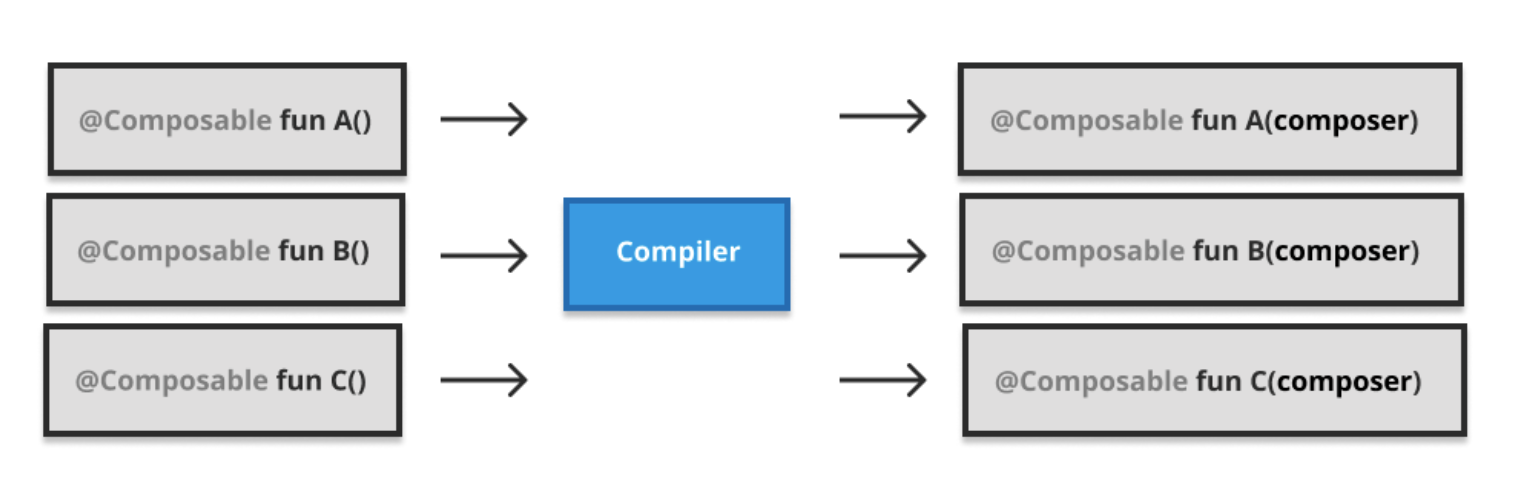
이렇게 주입된 Composer는 트리를 구성하고 상태를 최신으로 유지하는 데 필요한 정보를 제공하며 모든 하위 트리에서 사용됩니다.
코드가 어떻게 변하는지는 아래 예시를 통해 확인할 수 있습니다.
// 그림 22. NamePlate.kt
fun NamePlate(name: String, lastname: String, **$composer: Composer**) {
$composer.start(123)
Column(modifier = Modifier.padding(16.dp), $composer) {
Text(
text = name,
$composer
)
Text(
text = lastname,
style = MaterialTheme.typography.subtitle1,
$composer
)
}
$composer.end()
}참고로 Composable이 아닌 인라인(inline) 람다는 변환되지 않습니다.
인라인 람다는 컴파일 타임에 호출하는 쪽의 코드로 복사되어 들어가기 때문에 굳이 변환할 필요가 없기 때문입니다. 또한 KMP의 expect 함수들도 변환되지 않으며, 실제 구현체인 actual 함수가 타입 해결 과정에서 처리되어 변환됩니다.
$changed : 비교 전파 (Comparison propagation)
컴파일러는 $composer 외에도 최적화를 위한 메타데이터를 추가합니다.
이중 $changed는 컴포저블 함수의 각 매개변수들의 ‘변경 여부’를 요약한 비트마스크입니다.
런타임은 이 정보를 바탕으로 입력값이 변경되었는지 확인하고 불필요한 리컴포지션을 건너뛸 수 있습니다.
@Composable
fun Header(text: String, $composer: Composer<*>, **$changed: Int**)$changed는 각 입력 매개변수의 상태 정보를 비트(bit) 단위로 합성해 담는 형태입니다.
컴퓨터에게 비트 연산(AND, OR 등)은 가장 빠르고 비용이 적게 드는 계산 중 하나이기 때문입니다.
Compose 컴파일러는 Int가 가진 32비트의 공간을 쪼개 각 매개변수의 상태를 기록합니다.
따라서 하나의 $changed 매개변수는 약 10개 정도의 매개변수 상태를 표현할 수 있습니다.
매개변수 개수가 이를 초과하면, $changed1, $changed2와 같이 추가 매개변수가 생성됩니다.
이러한 메타데이터를 통해 런타임은 다음과 같은 부분 최적화를 수행합니다.
- 비교 생략
입력값이 정적(static)인 경우 컴파일 타임에 값이 변하지 않음을 알 수 있습니다.
이때$changed비트는 런타임에게 값을 비교할 필요가 없다고 알려줍니다. - 검증된 변경 없음
상위 트리에서 이미 비교를 마치는 등 값이 확실히 변경되지 않았음이 보장되는 경우입니다. - 불확실
값이 변경되었을 수도 있는 경우입니다(비트 값은 기본값인 0).
이때는 런타임이equals()로 값을 비교하고 슬롯 테이블에 결과를 저장하여 최신 상태를 유지합니다.$changed가 0이면 런타임은 최적화(숏컷) 없이 모든 매개변수를 비교합니다.
아래 예시는 Composable 함수 본문에 $changed를 처리하는 로직이 주입된 모습입니다.
@Composable
fun Header(text: String, $composer: Composer<*>, $changed: Int) {
var $dirty = $changed
if ($changed and 0b0110 === 0) {
$dirty = $dirty or if ($composer.changed(text)) 0b0010 else 0b0100
}
if ($dirty and 0b1011 xor 0b1010 !== 0 || !$composer.skipping) {
f(text) // executes body
} else {
$composer.skipToGroupEnd()
}
}코드를 보면 $dirty라는 로컬 변수를 사용해 상태를 추적합니다.
$changed의 비트마스크 정보와 슬롯 테이블의 이전 값을 조합해 현재 매개변수가 변경되었는지 판단합니다.
값이 변경되어 dirty(더러운) 상태라면 함수 본문을 실행하여 리컴포지션을 수행하고,
그렇지 않다면 skipToGroupEnd()를 호출하여 실행을 건너뜁니다.
리컴포지션이 매우 자주 일어날 수 있음을 고려하면 이러한 최적화는 계산 시간과 메모리를 크게 절약해 줍니다.
특히 매개변수가 여러 함수를 거쳐 전달될 때, 매번 불필요하게 값을 저장하고 비교하는 비용을 줄일 수 있습니다.
비교 전파(Comparison propagation)란 바로 이 책임을 의미합니다.
Composable 함수는 자신이 받은 $changed 정보를 분석하고, 이를 바탕으로 하위 Composable 함수를 호출할 때 다시 적절한 $changed 정보를 생성해 전달해야 합니다.
즉, 상위에서 이미 값이 정적이거나 변경되지 않았음을 알았다면 하위 함수에게도 이 사실을 알려주어 불필요한 재확인을 막는 것입니다.
또한 $changed 비트마스크는 매개변수가 안정적(stable)인지 불안정(unstable)인지에 대한 정보도 포함합니다. 이를 통해 List<T>와 같이 내용물이 바뀔 수 있는 타입이라도 listOf(1, 2)처럼 고정된 값이라면 안정적인 것으로 추론하여 리컴포지션을 생략할 수 있습니다.
$default : 디폴트 매개변수 (Default parameters)
이 외에도 Composable 함수는 컴파일 타임에 $default라는 메타데이터 매개변수가 추가됩니다.
사실 Composable 함수는 Kotlin의 표준 디폴트 매개변수 기능을 그대로 사용할 수 없습니다.
왜냐하면 매개변수의 기본값을 계산하는 표현식이 해당 Composable 함수의 범위(생성된 그룹) 내부에서 실행되어야 하기 때문입니다.
이 문제를 해결하기 위해 Compose는 $default라는 매개변수를 도입했습니다.
앞서 살펴본 $changed와 마찬가지로 비트마스크 방식을 사용하며, 각 입력 매개변수의 인덱스에 매핑됩니다.
$default의 역할은 단순합니다.
호출자가 특정 매개변수의 값을 전달했는지 생략했는지를 표시하는 것입니다.
런타임은 이 정보를 확인해 호출자가 넘겨준 값을 사용할지 함수 내부에 정의된 디폴트 값을 사용할지 결정합니다.
입력 매개변수가 많아지면 $default 매개변수도 그에 맞춰 여러 개가 추가됩니다.
아래 예시는 컴파일러가 코드를 변환하기 전과 후를 비교해 $default 비트마스크가 어떻게 활용되는지 보여줍니다.
// Before compiler (sources)
@Composable fun A(x: Int = 0) {
f(x)
}
// After compiler
@Composable fun A(x: Int, $changed: Int, $default: Int) {
// ...
val x = if ($default and 0b1 != 0) 0 else x
f(x)
// ...
}변환된 코드를 보면, $changed와 마찬가지로 비트 연산을 수행함을 알 수 있습니다.
로직은 $default 매개변수의 특정 비트를 확인했을 때 0이 아니라면(매개변수 값을 생략했다면) 변수 x에 디폴트 값인 0을 할당합니다. 반대로 비트가 0이라면 호출 시 전달된 값을 그대로 사용합니다.
컨트롤 플로우 그룹 생성 (Control flow group generation)
Compose 컴파일러는 각 Composable 함수의 본문을 분석해 제어 흐름(Control Flow) 구조에 따라 적절한 그룹 코드를 삽입합니다. 그룹은 크게 세 가지 유형으로 나뉩니다.
- 교체 가능한 그룹 (Replaceable groups)
- 이동 가능한 그룹 (Movable groups)
- 재시작 가능한 그룹 (Restartable groups)
Composable 함수는 런타임에 이 그룹들을 생성해 현재 상태에 대한 정보를 저장하고 보존합니다.
이를 통해 런타임은 구조가 완전히 바뀔 때(교체), 데이터의 위치가 바뀔 때(이동), 혹은 상태 변경으로 인해 함수를 다시 실행해야 할 때(재시작) 메모리에 저장된 데이터를 어떻게 처리해야 할지 알 수 있습니다.
또한 그룹은 소스 코드상의 위치 정보를 기반으로 생성된 키를 가지고 있습니다.
이는 1장에서 다룬 위치 기억법(Positional Memoization)을 가능하게 하는 핵심 요소입니다.
Compose 컴파일러 그룹 생성 규칙 요약
- 블록이 항상 1번만 실행된다면 - 그룹을 생성하지 않음
- 조건부 로직(if, when)의 분기 중 하나라면 - 교체 가능한 그룹(Replaceable group) 생성
- key 함수의 본문이라면 - 이동 가능한 그룹(Movable group) 생성
- 상태를 읽고 리컴포지션이 필요한 함수라면 - 재시작 가능한 그룹(Restartable group) 생성
1. 교체 가능한 그룹 (Replaceable groups)
앞서 Composable 람다식을 다룰 때, 컴파일러가 팩토리 함수를 통해 람다식을 감싼다는 것을 확인했습니다.
실제 이 팩토리 함수의 내부 구현을 보면 교체 가능한 그룹이 어떻게 생성되는지 알 수 있습니다.
fun composableLambda(
composer: Composer,
key: Int,
tracked: Boolean,
block: Any
): ComposableLambda {
composer.startReplaceableGroup(key) // 그룹 시작!
val slot = composer.rememberedValue()
val result = if (slot === Composer.Empty) {
val value = ComposableLambdaImpl(key, tracked)
composer.updateRememberedValue(value)
value
} else {
slot as ComposableLambdaImpl
}
result.update(block)
composer.endReplaceableGroup() // 그룹 끝
return result
}코드를 보면 startReplaceableGroup(key)으로 그룹을 시작하고, 필요한 정보를 업데이트한 뒤 endReplaceableGroup()으로 그룹을 닫습니다.
이것이 바로 컴포지션 내에서 해당 람다식의 영역을 표시하는 방법입니다.
이 방식은 람다식뿐만 아니라 일반적인 Composable 함수 호출에도 적용됩니다.
아래는 @NonRestartableComposable 어노테이션이 붙어 리컴포지션이 필요 없는 함수의 변환 예시입니다.
// Before compiler (sources)
@NonRestartableComposable
@Composable
fun Foo(x: Int) {
Wat()
}
// After compiler
@NonRestartableComposable
@Composable
fun Foo(x: Int, %composer: Composer?, %changed: Int) {
%composer.startReplaceableGroup(<>)
Wat(%composer, 0)
%composer.endReplaceableGroup()
}Foo 함수는 내부적으로 교체 가능한 그룹을 생성합니다.
그룹은 트리 구조를 형성하므로 내부에의 Wat() 함수가 Composable이라면 마찬가지로 자신의 그룹을 자식으로 생성합니다.
교체 가능한 그룹은 조건부 로직(if/else)에서 특히 중요합니다.
if (condition) {
Text("Hello")
} else {
Text("World")
}런타임은 condition이 변경되어 실행 경로가 바뀌면, 슬롯 테이블에 저장된 기존 그룹을 새로운 그룹으로 교체해야 함을 인지합니다. 이때 startReplaceableGroup이 생성하는 키와 구조 정보를 통해 서로 다른 Text 호출임을 구분할 수 있습니다.
2. 이동 가능한 그룹 (Movable groups)
이동 가능한 그룹은 컴포저블 함수의 위치가 바뀌어도 정체성을 유지해야 할 때 사용됩니다.
현재 이 그룹은 key 함수를 사용할 때 생성됩니다.
@Composable
fun TalksScreen(talks: List<Talk>) {
Column {
for (talk in talks) {
key(talk.id) { // Unique key
Talk(talk)
}
}
}
}위 코드처럼 목록의 아이템을 key로 감싸면 아이템의 순서가 바뀌어도 Talk 컴포저블의 상태가 유지됩니다.
컴파일러는 이를 다음과 같이 변환합니다.
// Before compiler (sources)
@Composable
fun Test(value: Int) {
key(value) {
Wrapper {
Leaf("Value ${'$'}value")
}
}
}
// After
@Composable
fun Test(value: Int, %composer: Composer?, %changed: Int) {
// ...
%composer.startMovableGroup(<>, value)
Wrapper(composableLambda(%composer, <>, true) { %composer: Composer?, %changed: Int ->
Leaf("Value %value", %composer, 0)
}, %composer, 0b0110)
%composer.endMovableGroup()
// ...
}startMovableGroup을 사용함으로써 런타임은 해당 그룹의 데이터가 메모리 상에서 이동하더라도 폐기하지 않고 보존해야 함을 알 수 있습니다.
3. 재시작 가능한 그룹 (Restartable groups)
재시작 가능한 그룹은 상태(State)를 읽는 Composable 함수에 삽입되는 그룹입니다.
이 그룹은 함수가 리컴포지션될 수 있도록 재시작 로직을 포함합니다.
// Before compiler (sources)
@Composable fun A(x: Int) {
f(x)
}
// After compiler
@Composable
fun A(x: Int, $composer: Composer<*>, $changed: Int) {
$composer.startRestartGroup()
// ...
f(x)
$composer.endRestartGroup()?.updateScope { next ->
A(x, next, $changed or 0b1)
}
}여기서 주목할 점은 endRestartGroup()의 반환 값입니다.
함수가 상태를 읽지 않았다면 반환 값은 null이며, 리컴포지션이 필요 없으므로 런타임에 아무것도 등록하지 않습니다.
하지만 함수가 상태를 읽었다면 null이 아닌 Scope 객체가 반환됩니다.
컴파일러는 여기에 updateScope 람다를 등록해 상태가 변했을 때 함수 A를 어떻게 리컴포지션해야 하는지 런타임에 알려줍니다.
Klib과 미끼 생성 (Klib and decoy generation)
Compose 컴파일러는 Klib(멀티플랫폼)과 Kotlin/JS 환경을 지원하기 위해 특별한 방식을 사용합니다.
이는 Kotlin/JS가 라이브러리의 IR(중간 표현)을 불러오는(역직렬화) 독특한 방식 때문입니다.
앞서 우리는 Compose 컴파일러가 Composable 함수에 $composer 같은 합성 매개변수를 추가하여 함수의 Signature을 바꾼다는 것을 배웠습니다. 하지만 Kotlin/JS 환경에서는 컴파일된 IR의 타입 서명이 바뀌면 의존성을 제대로 연결하지 못하는 문제가 발생합니다.
이 문제를 해결하기 위해 Compose는 JVM에서처럼 원본 함수의 IR을 직접 수정하는 대신 복사본을 생성하는 전략을 취합니다.
- 원본 함수 유지 (미끼, Decoy)
기존 함수 선언은 그대로 둡니다. 덕분에 외부 코드에서의 참조나 메타데이터 연결이 끊어지지 않고 유지됩니다. 하지만 이 함수는 껍데기일 뿐이며, 실제로 호출되면 예외를 발생시킵니다. - 복사본 생성 (구현체)
실제 로직은 복사된 새로운 함수로 옮겨집니다. 이 함수는 Compose가 필요한 매개변수($composer등)를 주입하여 변환한 버전입니다. 런타임에서 구분하기 위해 함수 이름 뒤에$composable이라는 접미사가 붙습니다.
코드를 통해 이 구조를 명확히 확인할 수 있습니다.
// Before compiler (sources)
@Composable
fun Counter() {
// ...
}
// Transformed
@Decoy(...)
fun Counter() { // 서명(Signature)이 기존과 동일하게 유지됨
illegalDecoyCallException("Counter")
}
@DecoyImplementation(...)
fun Counter$composable( // 서명이 변경됨 ($composer 등이 추가됨)
$composer: Composer,
$changed: Int
) {
// ...transformed code...
}변환된 코드를 보면 원본 Counter 함수는 @Decoy(미끼) 어노테이션이 붙어 있고, 본문에서는 illegalDecoyCallException을 던집니다. 즉, 누군가 이 원본 함수를 직접 호출하려 하면 에러가 발생합니다.
대신 실제 구현은 @DecoyImplementation이 붙은 Counter$composable 함수로 옮겨졌으며, 이곳에 컴파일러가 주입한 $composer와 $changed 매개변수가 존재하는 것을 볼 수 있습니다.
이 주제에 대해 더 깊이 알고 싶다면 Andrei Shikov가 작성한 게시물을 참고하시기 바랍니다.
