들어가며
안드로이드 스튜디오에서 Run 버튼을 누르면 짠 하고 앱이 켜진다.
이렇게 소스 코드를 실행 가능한 애플리케이션으로 변환하는 과정을 빌드라고 한다.
그동안 안드로이드 앱을 개발하며 빌드 속도가 느려 고생했던 적이 없었는데
최근에 빌드가 10분 이상 걸리는 프로젝트에서 느낀 답답함을 계기로 빌드 과정을 더 깊게 살펴보게 되었다.
역시 사람은 불편해야 공부한다…
안드로이드 빌드
Gradle
안드로이드에서 빌드는 Gradle이라는 빌드 자동화 도구를 통해 수행된다.
Gradle은 Task라는 최소 작업 단위를 가진다.
Task는 입력을 변환해 출력하는 과정의 추상화라고 생각하면 된다.
또한, 어떤 목적을 위해 필요한 Task들을 묶음으로 제공하는 기능을 Plugin이라고 한다.
Plugin을 적용하면 수많은 Task가 자동으로 실행된다.
아래처럼 build.gradle.kts에서 설정했던 것을 떠올리면 이해가 빠를 것이다.
AGP (Android Gradle Plugin)
AGP는 안드로이드 애플리케이션 빌드를 위한 공식 플러그인이다.
Kotlin, JAVA, 리소스 파일 등 앱을 구성할 때 필요한 다양한 유형의 소스를 컴파일하고
안드로이드 디바이스나 에뮬레이터에서 실행할 수 있는 APK나 AAB로 패키징한다.
참고로 이 글을 작성하는 현재, AGP의 가장 최신 버전은 9.0.0이다.
공식문서에 따르면 AGP 9.0.0 버전부터 Kotlin 지원이 AGP에 내장되므로 org.jetbrains.kotlin.android 설정을 생략할 수 있다.
plugins {
// 안드로이드 앱(APK/AAB) 빌드 플러그인
id("com.android.application") version "9.0" apply false
// 안드로이드 라이브러리(AAR) 빌드 플러그인
id("com.android.library") version "9.0" apply false
// Kotlin 컴파일을 위한 플러그인 (AGP 9.0.0 이후부터 생략 가능)
id("org.jetbrains.kotlin.android") version "2.2.21" apply false
}안드로이드 앱의 빌드 과정을 요약하면 아래와 같다.
이번 글에서는 첫번째 단계인 코드 컴파일에 대해 알아보자.
| 단계 | 주요 도구 | 결과물 |
|---|---|---|
| 코드 컴파일 | kotlinc / javac | .class (Bytecode) |
| 리소스 컴파일 | AAPT2 | R.java / Compiled Resources |
| DEX 변환 | D8 / R8 | .dex (Dalvik Executable) |
| 패키징 | ZIP / APK Signer | .apk 또는 .aab |
Kotlin 컴파일
Kotlin은 자바의 복잡성을 개선하면서도 상호 호환을 지원하는 JVM 기반 언어로서 등장했다.
따라서 2016년 처음 출시되었을 당시 코틀린의 유일한 사용처는 JVM 생태계였다.
하지만 오늘날 코틀린은 JVM 외에도 네이티브나 웹 등 여러 플랫폼을 지원하는 멀티 플랫폼 언어로, 아래처럼 각 플랫폼에 맞는 형태로 변환되어 다양한 환경에서 실행될 수 있다.
- JVM:
바이트코드로 컴파일되어 JVM 환경에서 동작한다. (안드로이드, 서버) - 네이티브:
기계어로 직접 컴파일되어 JVM이 없는 환경에서 동작한다. - 웹:
JS,Wasm으로 컴파일되어 브라우저 엔진에서 돌아간다.
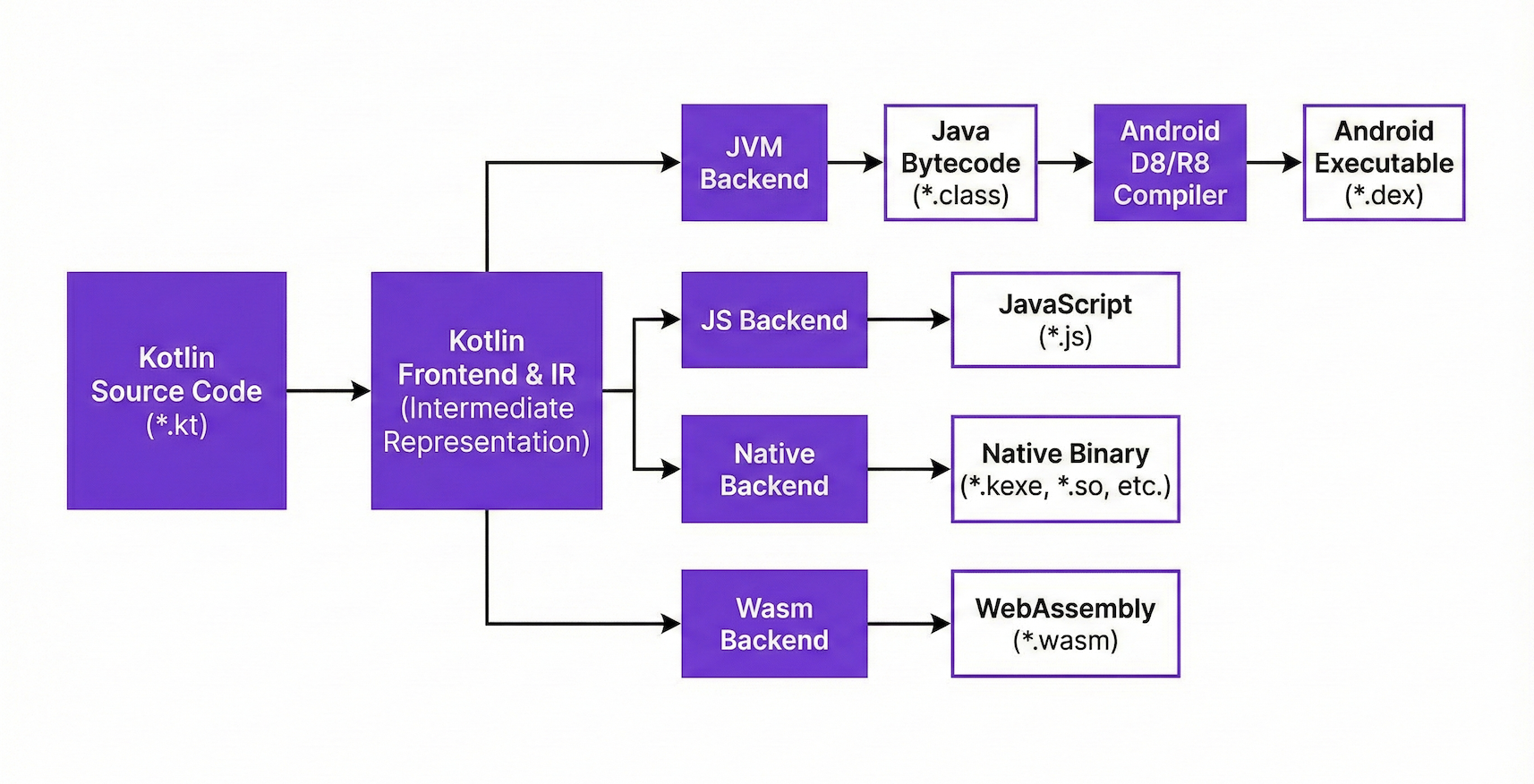
해당 글에서는 코틀린 코드(.kt)가 바이트코드(.class)로 변환되는 과정만 다룬다.
+ 컴파일이란?
컴파일이란, 넓은 의미에서 프로그래밍 언어의 형태를 바꾸는 모든 변환 과정이다.
일반적으로는 인간이 읽을 수 있는 고수준 언어에서 컴퓨터가 실행할 수 있는 저수준 언어로의 변환을 의미한다.
Kotlin 컴파일러
코틀린 컴파일은 kotlinc라는 컴파일러 툴에 의해 수행된다.
코틀린 소스 코드는 아래 단계를 거쳐 JVM 바이트코드로 변환된다.
- 프론트엔드 단계 : 소스 코드를 분석해 오류를 잡거나 중간 표현(IR)을 생성하는 단계
ㅤㅤㅤ↓
중간 표현(IR) : 모든 플랫폼에서 통용되는 중간 표현
ㅤㅤㅤ↓- 백엔드 단계 : 생성된 IR을 플랫폼에 맞게 Lowering하는 단계
프론트엔드 단계
프론트엔드 단계는 개발자가 작성한 소스 코드를 분석하는 단계이다.
소스 코드-구문 분석→PSI-의미 분석→BindingContext/FIR
구문 분석(Parsing)
소스 코드의 외형적 구조를 분석해 PSI(Program Structure Interface) 트리를 생성하는 단계이다.
PSI는 들여쓰기, 공백, 주석 등 소스 코드의 물리적 구조 정보를 담는 IntelliJ IDE의 라이브러리이다.
구문 분석 과정에서는 오타나 괄호 누락 등 구조적인 문법 오류를 검사할 수 있다.
예를 들어 a + b라는 코드에서 생성된 PSI에는 a와 b에 대한 덧셈 연산이라는 정보가 담긴다.
하지만 a와 b의 타입이 Int인지 Long인지는 아직 알 수 없다.
- 어휘 분석
- 의미 없는 문자열을 의미 있는 최소 단위인 토큰으로 쪼갠다.
val x = 1→[val (키워드)],[x (식별자)],[= (연산자)],[1 (리터럴)].
- 의미 없는 문자열을 의미 있는 최소 단위인 토큰으로 쪼갠다.
- 구문 분석
- 토큰들을 코틀린 문법 규칙에 따라 조립해 PSI 트리를 만든다.
의미 분석(Syntaxing)
PSI를 참고해 심볼을 해석하고 그 결과로 플랫폼 공통 중간 표현(IR)을 생성하는 단계이다.
타입 불일치나 존재하지 않는 함수 호출 등 논리 오류를 검사할 수 있다.
또한, 기존 코틀린 컴파일러와 K2 컴파일러의 핵심적인 차이는 이 단계에서 나타난다.
기존 컴파일러
PSI에 의미 정보를 더하기 위해 별도의 거대한 Map 구조인 BindingContext를 생성한다.
이 과정에서 특정 PSI 노드의 타입을 알려면 매번 Map을 검색해야 했고,
프로젝트가 커질수록 Map이 비대해지며 메모리 부하가 심해졌다.
또한, 여러 스레드에서 동시에 접근하기 어려워 병렬 처리가 사실상 불가능했다.
K2 컴파일러
Kotlin 2.0부터 적용되는 방식으로, PSI의 참조를 갖는 FIR(Frontend IR)이라는 가변 트리를 만든다.
의미 분석 결과를 FIR 노드 내부에 직접 기록하므로, 별도의 Map을 검색할 필요가 없다.
데이터가 분산되어 있어 병렬 분석에 용이하고 기존 컴파일러에 비해 메모리 효율 측면에서 대폭 개선되었다.
자세한 과정은 아래와 같다.
-
심볼 해석
코드에 적힌 이름들이 실제로 무엇을 가리키는지 연결한다.
예를 들어,println가kotlin.io에 정의된 함수인지 개발자가 직접 정의한 것인지 확인한다. -
타입 추론
val x = 10에서x가Int임을 확정한다.
특히, 조건문 안에서 변수의 타입 변화를 정확히 추적하는 등 한층 더 정교한 스마트 캐스트를 지원한다. -
FIR (Frontend IR) 생성
PSI 트리에서 불필요한 정보(공백, 주석 등)를 걷어내고 타입 정보와 심볼 정보가 추가된 FIR을 만든다.
(심볼 정보를 바탕으로 KAPT나 KSP가 실행되며 새로운 소스 코드를 생성할 수 있다.)
중간 표현(IR, Intermediate Representation)
Kotlin IR은 플랫폼 공통 중간 표현으로, 컴파일러 플러그인이 코드를 변형할 수 있는 단계이다.
특히 코루틴 Continuation을 추가하는 등 코틀린 언어 차원에서 제공하는 편리한 기능 중 상당수가 IR 단계에서 구현된다.
코틀린 공식 컴파일러 플러그인
- Kotlin Serialization:
@Serializable어노테이션이 붙은 클래스에serializer()함수를 자동으로 구현하고, JSON 변환 로직을 주입한다. - Parcelize: 안드로이드의
Parcelable구현을 위한 보일러플레이트 코드를 IR 단계에서 자동 생성한다. - All-open / No-arg: 주로 Spring이나 JPA와의 호환성을 위해 사용된다.
코틀린의 기본final제약을 풀거나, 기본 생성자 없는 클래스에 인자 없는 생성자를 강제로 추가한다.
백엔드 단계
IR이 플랫폼에 맞는 코드로 변환된다.
안드로이드의 경우 JVM 백엔드를 거쳐 바이트코드로 변환된다.
JVM의 철학과 JVM 바이트코드
JVM은 플랫폼 종속성 없이 어디서나 같은 실행을 보장하는 ‘Write Once, Run Anywhere’ 철학을 따른다.
따라서 JVM만 설치되어 있다면 하나의 코드를 맥, 윈도우, 리눅스 등 다양한 환경에서 동일하게 실행할 수 있다.
이는 소스 코드와 기계어 사이에 중간 단계인 JVM 바이트코드가 존재하기 때문이다.
소스 코드가 바이트코드로 컴파일되면 JVM은 이를 각 환경에 맞는 기계어로 변환해 실행한다.
JVM 바이트코드는 .class 확장자를 가진다.
따라서 Kotlin과 JAVA 등 JVM 기반 언어들은 컴파일 시 모두 .class로 변환된다.
바이트코드란?
가상머신을 기반으로 하는 고수준 언어들은 가상머신이 이해할 수 있도록 중간 코드로 컴파일되어야 한다.
바이트코드는 이러한 중간 코드의 일종으로, 각 명령어 크기가 1바이트(8비트)라는 뜻에서 이름 지어졌다.
바이트코드의 전체 명령어 종류는 256개(2^8)를 넘지 않도록 설계됐다.
예를 들어 두 숫자를 더하는 명령어는 0x60이라는 1바이트 숫자로 약속되어 있다.
이렇게 작고 가볍게 설계된 덕분에 JVM은 바이트코드를 빠르게 읽고 처리할 수 있다.
JAVA랑은 어떻게 통합될까?
자바와 코틀린이 섞여 있는 프로젝트에서 두 언어는 서로를 참조한다.
이러한 순환 참조 문제를 해결하기 위해 코틀린은 자바보다 항상 먼저 컴파일된다.
자바 컴파일러인 javac는 코틀린 소스 .kt를 전혀 읽을 수 없는 반면
코틀린 컴파일러인 kotlinc는 자바 소스 .java도 함께 분석할 수 있기 때문이다.
따라서 자바 컴파일 시점에 코틀린은 .kt가 아닌 .class의 바이트코드 형태여야 한다.
좀 더 구체적인 순서는 다음과 같다.
1. Kotlin 컴파일 단계 (kotlinc)
.kt -> .class 변환
이때, 참조하고 있는 Java 소스의 시그니처 정보를 파악한다.
2. Java 컴파일 단계 (javac)
.java -> .class 변환
1단계에서 생성된 Kotlin의 .class를 활용한다.
