1. RMSProp
RMSProp 개요
RMSProp(Root Mean Square Propagation)은 Adagrad의 단점을 보완하기 위해 등장했다. Adagrad는 학습이 진행될수록 학습률이 점점 작아져 학습이 멈추는 문제가 있는데, RMSProp은 이를 해결하려고 고안된 알고리즘이다.
RMSProp 동작 방식
RMSProp의 핵심 아이디어는 최근 기울기를 지수 이동 평균(Exponential Moving Average, EMA)으로 계산하여 학습률을 조정하는 것이다. 이는 학습률이 너무 작아지는 문제를 방지해준다.
구체적인 수식은 이러하다.
- 여기서 ""는 decay rate로 보통 0.9로 설정한다.
- Adagrad식의 ""와 squared gradient에 각각 "", ""의 decay rate가 붙는다. 보통 "" 정도로 설정되는데, 이렇게 되면 이전 스텝의 기울기를 더 크게 반영하여 "" 값이 단순 누적되는 것을 방지할 수 있다.
RMSProp의 장점
- 적응형 학습률: Adagrad처럼 매개변수마다 다른 학습률을 적용하지만, 학습률이 지나치게 작아지는 문제를 방지한다.
- 효율적 계산: 지수 이동 평균을 사용해 최근 기울기의 평균을 계산하여 안정적인 학습이 가능하다.
2. Adam
Adam 개요
Adam(Adaptive Moment Estimation)은 RMSProp과 모멘텀의 장점을 결합한 알고리즘으로 딥러닝에서 가장 많이 사용되는 옵티마이저이다.
Adam은 1차 모멘트(gradient를 중심으로 하는 모멘텀 계열)와 2차 모멘트(gradient 제곱에 반비례하는 ada, rmsprop 계열)를 동시에 고려하여 학습을 진행한다.
Adam 동작 방식
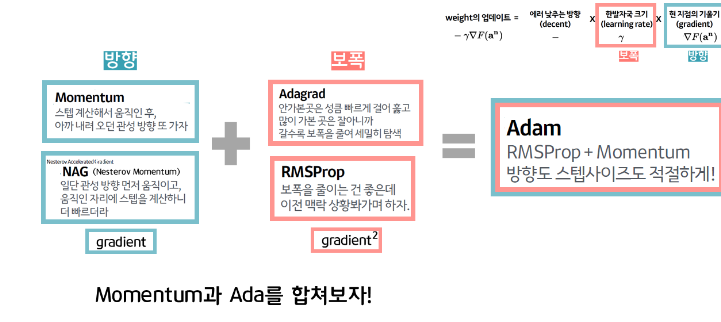
Adam은 Momentum 방식과 유사하게 지금까지 계산해온 기울기의 지수 평균을 저장하며, RMSProp과 유사하게 기울기의 제곱값에 지수평균을 저장한다. 이를 통해 기울기 값과 기울기의 제곱값의 지수이동평균을 활용하여 step 변화량을 조절한다. 또한, 초기 몇 번의 업데이트에서 0으로 편향되어 출발 지점에서 멀리 떨어진 곳으로 이동하는, 초기 경로의 편향 문제가 있는 RMSProp의 단점을 보정하는 매커니즘이 반영된다.
Adam의 구체적인 수식은 다음과 같다.
- 1차 모멘트 추정값 (기울기의 평균)
- 2차 모멘트 추정값 (기울기의 분산)
- 편향 보정
- 매개변수 업데이트
여기서, ""과 ""는 각각 1차 모멘트와 2차 모멘트의 decay rate로, 보통 0.9와 0.999로 설정합니다. ""은 수치적 안정성을 위한 아주 작은 값입니다.
1차 모멘트와 2차 모멘트
Adam은 1차 모멘트와 2차 모멘트를 사용하는데, 여기서 모멘트는 수리통계학에서 사용되는 적률(moments) 개념을 말한다
- 1차 모멘트는 데이터의 평균을 나타냅니다. 수식으로는 기울기 ""의 평균을 의미한다.
- 2차 모멘트는 데이터의 분산을 나타내며, 기울기 제곱 ""의 평균을 의미한다.
Adam에서의 1차 모멘트 추정치는 기울기의 지수 이동 평균으로, 2차 모멘트 추정치는 기울기 제곱의 지수 이동 평균으로 계산됩니다. 이 추정치들은 각각 기울기의 방향과 크기를 조절하는 데 사용된다.
불편 추정치
초기 몇 번의 업데이트에서 모멘트 값이 0에 가까워지는 편향 문제가 발생할 수 있다. 이를 해결하기 위해 Adam은 편향 보정을 사용한다. 이는 불편 추정치를 계산하여 초기 편향 문제를 해결한다.
- 1차 모멘트 불편 추정치
- 2차 모멘트 불편 추정치
Adam의 강점
- 빠른 수렴: RMSProp과 모멘텀의 장점을 결합하여 빠른 수렴 속도를 자랑한다.
- 적응형 학습률: 매개변수마다 다른 학습률을 적용하므로, 학습이 안정적이다.
- 편향 보정: 초기 단계에서의 편향 문제를 보정하여 학습이 더욱 안정적으로 진행된다.
- 넓은 범위에서 효과적: Adam은 매우 다양한 신경망 구조에서 잘 작동하며, 현재 가장 많이 사용되는 알고리즘 중 하나이다.
Adam의 하이퍼파라미터 설정
Adam의 하이퍼파라미터로는 "", "", "", 그리고 학습률 ""가 있다. 일반적으로 "", "", ""로 설정하고, 학습률 ""는 여러 값을 시도하여 최적의 값을 찾는 것이 좋다.
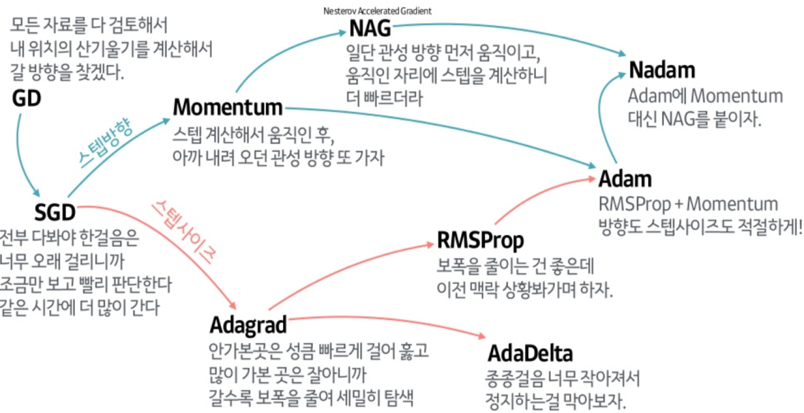
옵티마이저 정리