딥러닝과 강화학습의 융합
-
강화학습(RL): 에이전트가 환경과 상호작용하며 최적의 행동을 학습하는 과정.
- 핵심 요소:
- 상태(State): 현재 환경의 상태.
- 행동(Action): 에이전트가 취할 수 있는 행동.
- 보상(Reward): 행동의 결과로 환경이 에이전트에 제공하는 피드백.
- 정책(Policy): 상태에 따라 행동을 결정하는 함수.
- 목표: 보상을 최대로 만드는 정책 학습.
- 핵심 요소:
-
딥러닝(DL): 심층 신경망을 사용하여 복잡한 패턴이나 함수를 모델링.
- 강화학습의 비선형 함수 근사를 위해 딥러닝이 사용됨.
-
심층 강화학습(DRL): 딥러닝과 강화학습의 융합.
- Q-값, 정책 함수 등을 심층 신경망으로 근사.
- 복잡한 환경에서도 학습 가능.
DQN (Deep Q-Network) 소개
- 전통적인 Q-Learning은 상태 공간이 클 경우 Q-테이블을 저장하기 어렵고, 일반화가 어려움.
- DQN은 심층 신경망(Deep Neural Network)을 사용하여 Q-값을 근사:
- 입력: 상태(state).
- 출력: 행동(action)에 대한 Q-값.
주요 특징
-
경험 재생(Experience Replay):
- 에이전트가 경험한 데이터를 저장하여 랜덤 샘플링으로 학습.
- 데이터 간 상관성을 줄이고 학습 효율 향상.
-
타겟 네트워크(Target Network):
- Q-값 업데이트 안정성을 위해 메인 네트워크와 별도로 고정된 타겟 네트워크 사용.
- 일정 간격으로 타겟 네트워크를 메인 네트워크의 가중치로 갱신.
1. Q-Learning 업데이트 수식
기존 Q-Learning에서는 다음과 같은 수식을 사용합니다:
- : 상태 $( s $)에서 행동 $( a $)를 했을 때의 Q-값 (예상 보상)
- $r $: 현재 행동 $( a $)를 통해 받은 보상
- : 할인율 (미래 보상을 현재 가치로 반영할 비율)
- : 학습률 (새로운 값과 기존 값의 반영 비율)
- $\max_{a'} Q(s', a') $: 다음 상태 $( s' $)에서 가능한 행동 중 가장 큰 Q-값
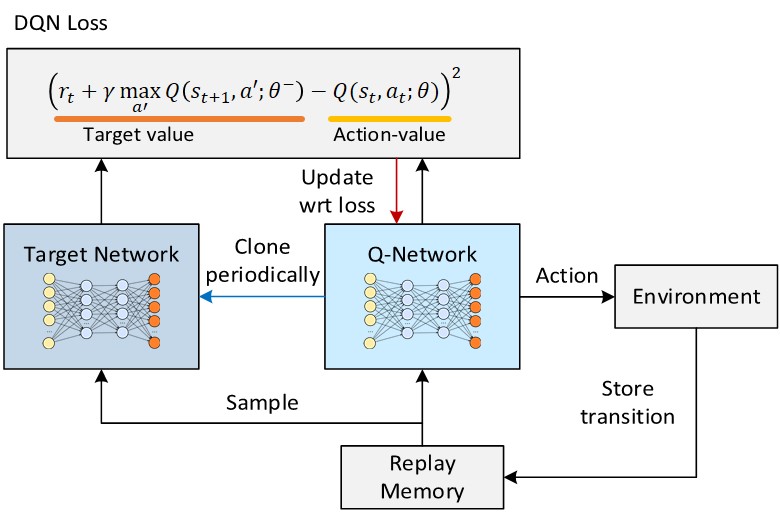
2. DQN의 업데이트 수식
DQN의 손실 함수는 "현재 시점에서의 Q값"과 "미래의 기대 보상으로 계산된 목표 Q값" 간의 차이를 줄이는 것을 목표로 합니다. 이를 통해 Q함수가 점점 더 정확하게 미래의 보상을 반영하게 되고, 에이전트가 최적의 행동을 학습할 수 있습니다.
DQN은 심층 신경망(Deep Neural Network)을 사용하여 $Q$값을 근사합니다. 업데이트를 위해 다음 손실 함수(Loss Function)를 사용합니다:
- : 메인 네트워크에서 예측한 Q-값
- : 타겟 네트워크에서 계산한 Q-값 (고정된 값 사용)
- : 현재 보상
- : 미래 보상의 예상치
이 손실 함수를 최소화하도록 메인 네트워크가 학습됩니다.
3. 경험 재생 (Experience Replay)
경험 재생은 DQN의 중요한 구성 요소 중 하나입니다. 이를 통해 신경망 학습의 안정성을 높입니다.
개념 설명:
-
에이전트는 환경과 상호작용하면서 경험을 만듭니다. 각 경험은 다음과 같은 형태로 저장됩니다:
- $ s $: 현재 상태
- $ a $: 행동
- $ r $: 보상
- $ s' $: 다음 상태
- : 에피소드 종료 여부 (True/False)
-
이러한 경험을 모두 메모리 버퍼(Replay Buffer)순차적으로 저장됩니다. 학습 시, 이 버퍼에서 랜덤 샘플링 을 통해 데이터를 추출해 신경망을 학습시킵니다.
왜 경험 재생이 필요한가?
- 데이터 상관성 제거:
에이전트가 연속된 데이터를 사용하면 매우 비슷한 상태-행동 쌍이 반복적으로 등장하여, 모델이 특정 패턴에 편향될 가능성을 높입니다. 랜덤 샘플링을 통해 이를 방지합니다. - 데이터 재사용:
- 경험 재생은 한 번의 경험을 여러 번 학습에 사용합니다.
이로 인해 새로운 데이터를 계속 생성하지 않아도 효율적으로 학습할 수 있습니다. - 이를 통해 더 적은 데이터로도 신경망을 효과적으로 학습시킬 수 있습니다.
쉽게 비유하면:
- 경험 재생은 과거의 학습 기록(노트)을 모아두고 복습하는 것과 같습니다.
- 즉, 에이전트가 과거 경험을 "기록"해두었다가 중요한 순간에 다시 꺼내 학습하는 방식입니다.
- 이를 통해 학습 과정에서 데이터가 부족하거나 연속된 데이터의 영향을 최소화할 수 있습니다.
4. 타겟 네트워크 (Target Network)
타겟 네트워크는 DQN 학습의 안정성을 높이는 기술입니다.
동작 원리:
- 메인 네트워크:
- 에이전트가 현재 상태에서 최적의 행동을 선택하도록 학습합니다.
- Q-값을 계산해 행동의 가치를 예측합니다.
- 타겟 네트워크:
- 메인 네트워크의 가중치를 일정 주기마다 복사해 고정된 상태로 유지합니다.
- 학습 중 목표값(Target Q-value)을 계산하는 데 사용됩니다.
왜 타겟 네트워크가 필요한가?
- DQN에서는 목표 Q-값(Target Q-value)을 예측하기 위해 메인 네트워크의 Q-값을 사용합니다. 하지만 이 값이 학습 중 계속 변한다면 목표값 자체가 흔들리며 학습이 불안정해질 수 있습니다.
- 타겟 네트워크는 일정 기간 동안 고정된 값을 제공하여 목표 Q-값을 안정적으로 유지하도록 돕습니다.
- 일정 주기마다 타겟 네트워크를 메인 네트워크로 업데이트하면서 최신 정보를 반영합니다.
쉽게 비유하면:
타겟 네트워크는 참고서와 같습니다. 참고서는 일정 시간 동안 바뀌지 않으므로 학습 목표가 흔들리지 않습니다. 대신 시간이 지나면 최신 정보를 반영해 갱신됩니다.
5. 전체 구조 정리
DQN의 학습 과정은 다음과 같습니다:
1. 환경과 상호작용하며 경험)를 저장.
2. 메모리 버퍼에서 랜덤 샘플링을 통해 학습 데이터를 추출.
3. 메인 네트워크에서 현재 상태의 Q-값)를 예측.
4. 타겟 네트워크에서 목표 Q-값를 계산.
5. 손실 함수(Loss)를 계산하고 메인 네트워크를 업데이트.
6. 일정 주기마다 타겟 네트워크를 메인 네트워크로 동기화.
DQN 실습
간단한 OpenAI Gym 환경에서 DQN 모델을 구현하여 학습하는 과정을 실습합니다.
- 환경:
CartPole-v1. - 목표: 막대가 쓰러지지 않고 균형을 유지하도록 에이전트를 학습.
- 주요 구성 요소:
- 경험 재생(Experience Replay)을 위한 메모리 버퍼.
- 메인 네트워크와 타겟 네트워크.
- DQN 학습 루프.
- 종료 조건 :
- 막대의 각도가 일정 한계를 벗어나는 경우
- 정해진 일정 시간을 초과하는 경우
# 필요한 라이브러리 임포트
import numpy as np # 수학적 계산 및 배열 처리
import tensorflow as tf # 딥러닝 프레임워크
from tensorflow.keras import Sequential # 순차 모델
from tensorflow.keras.layers import Dense # 신경망 층
from collections import deque # 경험 재생 버퍼 구현을 위한 큐
import gym # 강화학습 환경 제공 라이브러리
# CartPole-v1 환경을 생성하고 초기화
# render_mode="human"을 통해 환경 시각화
env = gym.make("CartPole-v1", render_mode="human")
state = env.reset() # 초기 상태 가져오기
# 상태 공간의 크기와 행동 공간의 크기 정의
state_size = env.observation_space.shape[0] # 상태의 차원 (카트의 위치, 속도, 막대의 각도, 각속도)
action_size = env.action_space.n # 가능한 행동의 수 (왼쪽, 오른쪽)
# 경험 재생(Experience Replay)을 위한 버퍼 클래스
class ReplayBuffer:
def __init__(self, max_size=50000):
# 버퍼를 deque로 생성 (최대 크기 50000)
self.buffer = deque(maxlen=max_size)
def add(self, experience):
# 새로운 경험 (state, action, reward, next_state, done)을 버퍼에 추가
self.buffer.append(experience)
def sample(self, batch_size):
# 버퍼에서 무작위로 batch_size개의 샘플을 추출
indices = np.random.choice(len(self.buffer), batch_size, replace=False)
return [self.buffer[idx] for idx in indices]
def size(self):
# 현재 버퍼의 크기를 반환
return len(self.buffer)
# Q값을 예측할 신경망 모델을 생성하는 함수
def build_model():
# 순차 모델 생성
model = Sequential([
Dense(24, input_dim=state_size, activation='relu'), # 첫 번째 은닉층 (입력: 상태 크기)
Dense(24, activation='relu'), # 두 번째 은닉층
Dense(action_size, activation='linear') # 출력층 (출력: 각 행동의 Q값)
])
# 모델 컴파일 (Adam 옵티마이저, 손실 함수: MSE)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss='mse')
return model
# DQN 에이전트 클래스
class DQNAgent:
def __init__(self):
# 주 신경망 (Main Network) 생성
self.main_model = build_model()
# 타겟 신경망 (Target Network) 생성
self.target_model = build_model()
# 타겟 신경망의 가중치를 주 신경망과 동일하게 초기화
self.target_model.set_weights(self.main_model.get_weights())
# 경험 재생 버퍼 초기화
self.replay_buffer = ReplayBuffer()
# 하이퍼파라미터 설정
self.gamma = 0.99 # 할인 계수 (미래 보상의 중요도)
self.epsilon = 1.0 # 탐험률 초기값
self.epsilon_decay = 0.995 # 탐험률 감소 비율
self.epsilon_min = 0.01 # 최소 탐험률
self.batch_size = 64 # 학습 배치 크기
def update_target_network(self):
# 타겟 신경망의 가중치를 주 신경망의 가중치로 업데이트
self.target_model.set_weights(self.main_model.get_weights())
def select_action(self, state):
# 입실론-그리디 정책에 따라 행동 선택
if np.random.rand() <= self.epsilon:
# 무작위 행동 선택 (탐험)
return env.action_space.sample()
# 주 신경망을 통해 Q값 예측
q_values = self.main_model.predict(state)
# 가장 큰 Q값을 가진 행동 선택 (활용)
return np.argmax(q_values[0])
def train(self):
# 경험 재생 버퍼에서 배치를 샘플링하여 학습
if self.replay_buffer.size() < self.batch_size:
return # 버퍼 크기가 배치 크기보다 작으면 학습하지 않음
# 배치 샘플링
batch = self.replay_buffer.sample(self.batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
states = np.array(states).squeeze(axis=1) # 현재 상태
next_states = np.array(next_states).squeeze(axis=1) # 다음 상태
# 현재 상태에 대한 Q값 예측
target_qs = self.main_model.predict(states)
# 다음 상태에 대한 Q값 예측 (타겟 네트워크 사용)
next_qs = self.target_model.predict(next_states)
# Q-Learning 업데이트 규칙 적용
for i in range(self.batch_size):
if dones[i]: # 종료 상태에서는 보상만 반영
target_qs[i][actions[i]] = rewards[i]
else: # 비종료 상태에서는 보상 + 할인된 미래 보상 반영
target_qs[i][actions[i]] = rewards[i] + self.gamma * np.max(next_qs[i])
# 주 신경망 학습
self.main_model.fit(states, target_qs, epochs=1, verbose=0, batch_size=32)
# DQN 에이전트 생성
agent = DQNAgent()
episodes = 500 # 학습할 에피소드 수
# 학습 루프
for episode in range(episodes):
state = env.reset() # 환경 초기화 및 상태 가져오기
state = state[0] if isinstance(state, tuple) else state # 상태가 튜플이면 첫 번째 요소 사용
state = np.reshape(state, [1, state_size]) # 상태를 2D 배열로 변환
total_reward = 0
done = False
while not done:
# 행동 선택
action = agent.select_action(state)
# 환경에서 한 스텝 진행
step_result = env.step(action)
if len(step_result) == 4: # Gym 반환값 처리
next_state, reward, done, info = step_result
elif len(step_result) == 5: # 일부 버전에서 반환값 추가 처리
next_state, reward, done, truncated, info = step_result
done = done or truncated # truncated를 종료 조건으로 처리
else:
raise ValueError(f"Unexpected step result length: {len(step_result)}")
next_state = next_state[0] if isinstance(next_state, tuple) else next_state
next_state = np.reshape(next_state, [1, state_size]) # 다음 상태 변환
# 경험을 리플레이 버퍼에 저장
agent.replay_buffer.add((state, action, reward, next_state, done))
state = next_state # 상태 업데이트
total_reward += reward # 총 보상 업데이트
# 에이전트 학습
agent.train()
# 10 에피소드마다 타겟 네트워크 업데이트
if episode % 10 == 0:
agent.update_target_network()
# 탐험률 감소
if agent.epsilon > agent.epsilon_min:
agent.epsilon *= agent.epsilon_decay
# 에피소드 정보 출력
if episode % 10 == 0:
print(f"Episode: {episode}, Total Reward: {total_reward}, Epsilon: {agent.epsilon:.2f}")
# 환경 종료
env.close()학습 결과를 비디오로 저장
import os
from gym.wrappers import RecordVideo
# 비디오 저장 경로 설정
video_save_path = "./cartpole_videos"
os.makedirs(video_save_path, exist_ok=True)
# CartPole 환경을 생성하고 비디오 저장 설정
env = gym.make("CartPole-v1", render_mode="rgb_array") # 비디오 저장용 환경 생성
env = RecordVideo(env, video_save_path, episode_trigger=lambda x: True) # 모든 에피소드 비디오 저장
def play_and_record(agent, env, episodes=5):
"""
학습된 에이전트가 환경을 플레이하며 비디오를 저장하는 함수.
Args:
agent: 학습된 DQN 에이전트.
env: 비디오를 기록할 Gym 환경.
episodes: 에이전트가 플레이할 에피소드 수.
"""
for episode in range(episodes):
state = env.reset()
state = state[0] if isinstance(state, tuple) else state # 상태가 튜플이면 첫 번째 요소 사용
state = np.reshape(state, [1, state_size]) # 상태를 2D 배열로 변환
total_reward = 0
done = False
while not done:
# 학습된 네트워크로 행동 선택 (탐험 없이 활용만 수행)
q_values = agent.main_model.predict(state)
action = np.argmax(q_values[0]) # 가장 높은 Q값을 가진 행동 선택
# 환경에서 한 스텝 진행
step_result = env.step(action)
if len(step_result) == 4: # Gym 반환값 처리
next_state, reward, done, info = step_result
elif len(step_result) == 5: # 일부 버전에서 반환값 추가 처리
next_state, reward, done, truncated, info = step_result
done = done or truncated # truncated를 종료 조건으로 처리
else:
raise ValueError(f"Unexpected step result length: {len(step_result)}")
next_state = next_state[0] if isinstance(next_state, tuple) else next_state
next_state = np.reshape(next_state, [1, state_size]) # 다음 상태 변환
state = next_state # 상태 업데이트
total_reward += reward # 총 보상 업데이트
print(f"Episode: {episode + 1}, Total Reward: {total_reward}")
# 학습된 에이전트로 플레이하며 비디오 저장
play_and_record(agent, env, episodes=5)
# 비디오 저장 완료 후 환경 종료
env.close()
print(f"비디오가 '{video_save_path}'에 저장되었습니다.")생성된 비디오 재생
from IPython.display import HTML
import base64
def display_video(video_path):
"""저장된 비디오를 Jupyter Notebook에서 재생"""
with open(video_path, "rb") as video_file:
video_data = video_file.read()
encoded_video = base64.b64encode(video_data).decode("utf-8")
return HTML(f"""
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{encoded_video}" type="video/mp4">
</video>
""")
# 비디오 파일 경로
video_file_path = f"{video_save_path}/rl-video-episode-4.mp4"
display_video(video_file_path)