대소문자 변환
: upper(), lower(), initcap()
: varcher2 upper(컬럼명)
: varcher2 lower(컬럼명)
: varcher2 initcap(컬럼명) : 첫글자만 대문자, 나머지 소문자
- 실습 코드
select
first_name,
upper(first_name), -- Ellen ELLEN ellen Ellen
lower(first_name),
initcap(first_name)
from employees;-- 이름(first_name) 'an' 포함된 직원? > 대소문자 구분없이
select
first_name
from employees
where first_name like '%an%'; --Anthony없음 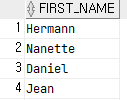
=> Anthony가 없기 때문에 다 대문자나 소문자로 바꾸고 검색!
select
first_name
from employees
where upper(first_name) like '%AN%';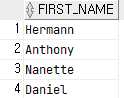
문자열 추출 함수
: substr()
: varchar2 substr(컬럼명, 시작위치, 가져올 문자 개수)
: varchar2 substr(컬럼명, 시작위치)
- 실습 코드
select
substr(name, 1,3), -- 세 글자만 가져옴
substr(name,1) -- 끝을 지정 하지 않으면 끝까지 다 가져옴
from tblCountry;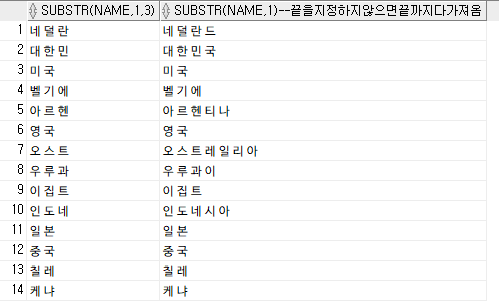
--tblInsa > 김, 이, 박, 최, 정 > 각각 몇명?
select
count(case
when substr(name,1,1) ='김' then 1
end) as 김씨,
count(case
when substr(name,1,1) ='이' then 1
end) as 이씨,
count(case
when substr(name,1,1) ='박' then 1
end) as 박씨,
count(case
when substr(name,1,1) ='최' then 1
end) as 최씨,
count(case
when substr(name,1,1) ='정' then 1
end) as 정씨,
count(case
when substr(name,1,1) not in ('김', '이', '박', '최', '정') then 1
end) as 다른성씨
from tblInsa;

문자열 길이
: length()
: number length(컬럼명)
- 실습코드
-- 컬럼 리스트에서 사용
select name, length(name) from tblcountry;
-- 조건절에서 사용
select name, length(name) from tblCountry
where length(name) > 3;
-- 정렬에서 사용
select name, length(name) as length from tblCountry
order by length;📌 순서 중요!!
-- 순서가 맞지 않기 때문에 length가 안됨
select name, length(name) as length --3
from tblCountry --1
where length > 3; --2
-- order by는 마지막 순서이기 때문에 가능
select name, length(name) as length --3
from tblCountry --1
where length(name) > 3 --2
order by length desc;
문자열 검색
: instr() == Java의 indexOf
: 검색어의 위치를 반환
: number instr(컬럼명, 검색어)
: number instr(컬럼명, 검색어, 시작위치)
: number instr(컬럼명, 검색어, 시작위치, -1) -- lastIndexOf
: 못 찾으면 0을 반환
- 실습코드
select
'안녕하세요. 홍길동님',
instr('안녕하세요. 홍길동님', '홍길동') as r1, --8
instr('안녕하세요. 홍길동님', '아무개') as r2, --0
instr('안녕하세요. 홍길동님. 홍길동님', '홍길동', 11) as r4, --14
instr('안녕하세요. 홍길동님. 홍길동님', '홍길동', instr('안녕하세요. 홍길동님. 홍길동님', '홍길동') + length('홍길동')) as r5, --14
instr('안녕하세요. 홍길동님. 홍길동님', '홍길동' , -1) as r6 --14패딩
: lpad(), rpad()
: left padding, right padding
: varchar2 lpad(컬럼명, 개수, 문자)
: varchar2 rpad(컬럼명, 개수, 문자)
select
lpad('a',5), --" a" == Java %5s 자릿수 == %05d와 같은 경우에 가장 많이 쓰임
lpad('a',5 ,'b'), -- 여백을 b로 채움
lpad('1', 3, '0'), --001
rpad('1', 3, '0') --100
from dual;
공백 제거
: trim(), ltrim(), rtrim()
: varchar2 trim(컬럼명)
: varchar2 ltrim(컬럼명)
: varchar2 rtrim(컬럼명)
💡 가운데 공백은 제거하지 못함!
- 실습 코드
select
trim(' 하나 둘 셋 '),
ltrim(' 하나 둘 셋 '),
rtrim(' 하나 둘 셋 ')
from dual;

문자열 치환 1
: replace()
: varchar2 replace(컬럼명, 찾을 문자열, 바꿀 문자열)
: regexp_replace() : 정규표현식 지원
- 실습 코드
select
replace('홍길동', '홍','김'), --김길동
replace('홍길동', '이','김'), -- 아무것도 안 바꾸고 넘어감
replace('홍길홍', '홍','김') --김길김
from dual;select
name,
regexp_replace(name,'김[가-힣]{2}','김OO') as 정규표현식,
tel,
regexp_replace(tel,'(\d{3})-(\d{4})-\d{4}','\1-\2-XXXX') as 모자이크, --\1 : 첫번째 소괄호
regexp_replace(tel,'(\d{3}-\d{4})-\d{4}','\1-XXXX') as 모자이크
from tblInsa;
문자열 치환 2
: decode()
: replace()와 유사
: varchar2 decode(컬럼명, 찾을 문자열, 바꿀 문자열)
: varchar2 decode(컬럼명, 찾을 문자열, 바꿀 문자열, 찾을 문자열, 바꿀 문자열)
: varchar2 decode(컬럼명, 찾을 문자열, 바꿀 문자열, 찾을 문자열, 바꿀 문자열[, 찾을 문자열, 바꿀 문자열]x N)
select
gender,
case
when gender = 'f' then '여자'
when gender = 'm' then '남자'
end as g1,
replace(gender, 'm', '남자') as g2,
replace(replace(gender, 'm', '남자'),'f','여자')as g2,
decode(gender, 'm', '남자', 'f', '여자') as g3
from tblComedian;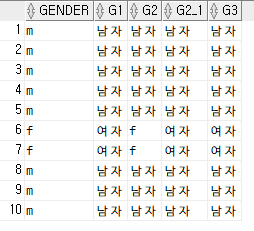
select
replace('자바 코드', '자바', 'Java') as 자바코드, --Java 코드
decode('자바 코드', '자바', 'Java') as 글자수, --null(원본을 못 찾으면)
decode('자바 코드', '자바 코드', 'Java') as 자바--Java
from dual;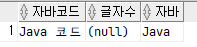
📌 case로 수를 구하는 것보다 가독성이 좋음!!
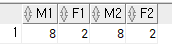
select
count(case
when gender = 'm' then 1
end) as m1,
count(case
when gender = 'f' then 1
end) as f1,
count(decode(gender, 'm', 1)) as m2, --m1과 동일한 값
count(decode(gender, 'f', 1)) as f2
from tblComedian;