공부하면서 알게된, LLM/VLM을 실제로 쓰는 개발자가 자주 마주치는 파라미터와 구조 뒤에 어떤 메커니즘이 있는지를 정리해 봤습니다.
개요
VLM(Vision-Language Model)으로 영상 행동 분류 PoC를 만들면서 모델 호출 옵션과 JSON 출력 안정화 코드를 직접 손대게 됐습니다.
에이전트로 컨트롤 하더라도 그 과정에서 코드에 자주 등장한 단어나, 개념들을 알아두어야 적절한 조정이 가능하기 때문에 직접 학습에 들어갔습니다.
처음 보면 당황할 만한 단어들이 많으니, 기본 개념을 공부해봅시다.
- temperature : 모델이 다음 토큰을 뽑을 때 확률 분포를 얼마나 뾰족하게 만들지 조절하는 파라미터
- topP(Top-P, Nucleus Sampling): 후보 토큰을 누적 확률 P까지만 남기고 자르는 규칙
- JSON 출력 방어: 모델 응답을 JSON 형식으로 안정적으로 받기 위한 다층 설계
이 단어들의 정확한 의미를 알고, 각 결정의 근거가 명확히 있어야 파라미터 선택이 추측이 아니게 됩니다.
어디에 쓰고, 어디에 도움이 될까?
메커니즘을 알면 LLM 도구 결정이 추측에서 근거로 바뀝니다.
VLM으로 영상을 분류시킬 때 겪을 수 있는 다음 상황에서 의사결정의 근거가 됩니다.
- "프롬프트 이렇게 쓰면 좋다" 류 팁이 어떤 건 통하고 어떤 건 안 통하는지 안 보일 때. 표층 팁 뒤의 메커니즘이 보이면 그 팁이 통하는 조건과 안 통하는 조건이 분리됩니다.
- 같은 입력에 호출마다 다른 답이 나올 때. "왜 결과가 흔들리지?"를 "다양성이 너무 높아서"라는 일반론으로 넘기지 않고, 분포가 어떻게 만들어지고 어떻게 가공되는지를 알면 temperature 같은 파라미터를 손대는 근거가 생깁니다.
- 파라미터 추천값을 그냥 따라 썼는데 효과를 설명하기 어려울 때. topP 0.95가 후보 토큰을 어떻게 자르는지 메커니즘을 알면 0.95냐 0.5냐 결정이 추측이 아닌 계산이 됩니다.
- JSON 출력이 가끔 깨져서 후처리가 멈출 때. 프롬프트만 바꾸다가 안 풀리는 이유, 그리고 SDK 설정·정규식 fallback이 왜 따로 필요한지가 보입니다. 3단 설계로 갈 근거가 명확해집니다.
- VLM이 confidence 값을 같이 주는데 그걸로 뭘 해야 할지 막막할 때. 모델 자체 점수와 우리가 정하는 cutoff 룰이 어떻게 다른지 구분이 되면, "낮으면 재호출"이 아니라 "낮으면 사람 큐"라는 설계 결정이 자연스럽게 따라옵니다.
메커니즘 5가지
1. 어휘집(vocabulary)과 토큰 분포
개념:
- 모델이 아는 모든 토큰의 사전을 어휘집(vocabulary)이라 합니다(Gemini 2.5 Flash 기준 약 25만 개)
- 한 토큰을 생성할 때마다 이 25만 개 전체에 확률 분포가 만들어집니다.
즉, 매 스텝마다 25만 개 전체에 새 분포가 생기고 그 중 1개가 뽑힙니다.
비유:
- 날씨 예보와 같습니다. 내일 날씨 예보는 "비 70%, 흐림 15%, 맑음 10%, 눈 3%, 안개 2%"처럼 모든 가능성에 확률을 부여합니다. 비만 후보인 게 아니라 눈에도 작은 확률이 있습니다. 토큰 분포도 마찬가지입니다.
실전:
- 이 구조를 모르면 이후 공부할 temperature를 바꿔도 무슨 일이 벌어지는지 알 수 없습니다. 분포 가공 방법(temperature·topP)은 다음 항목에서 다룹니다.
2. Autoregressive 생성
개념:
- LLM은 토큰을 한 번에 다 만들지 않습니다. 직전까지 생성한 모든 토큰을 입력으로 받아 다음 토큰 하나를 예측하고, 그 토큰을 다시 입력에 추가해 다음을 예측하는 방식으로 순서대로 이어갑니다. 매 스텝마다 어휘집 전체 확률 분포를 새로 계산합니다.
- 끝말잇기와 같습니다. 이전에 나온 단어를 받아 다음 단어를 고르고, 그 단어가 또 다음 사람의 입력이 됩니다. 단어를 미리 다 정해두지 않습니다.
- 차이가 있다면, 끝말잇기는 직전 단어 하나에만 의존하지만, LLM은 처음 입력부터 직전 토큰까지 전체 문맥을 참조합니다.
- 그러다보니 응답 앞부분에서 잘못된 방향이 잡히면 뒷부분도 그 방향으로 이어집니다. 출력 형식을 초반에 명확히 유도하는 것이 중요한 이유입니다.
3. Temperature와 topP(Top-P, Nucleus Sampling)
개념:
- Temperature는 확률 분포 자체의 뾰족함을 조절하고, topP는 그 분포에서 후보 토큰 집합을 잘라냅니다.
- 즉, 같은 분포에 다른 방식으로 작용하는 두 파라미터 입니다.
예시 이미지를 보며 공부해보죠
위 이미지 상, topP 0.5에서 후보 토큰 집합이 "0개"가 아니라 1개인 이유는, 1등 토큰(0.70)이 cutoff(0.50)를 단독으로 이미 넘기 때문입니다.
비유:
- topP는 정원이 정해진 엘리베이터입니다. 누적 확률이 P에 닿으면 그 뒤 후보는 들이지 않습니다. 1등 토큰 혼자 cutoff를 단독으로 넘으면 그 토큰만 후보로 남습니다.
실전:
- 분류 task에서는 temperature 0.1 + topP 0.95 조합이 재현성과 꼬리 토큰 차단을 동시에 처리합니다.
- temperature를 기본값(1.0)으로 두면 같은 입력에 다른 라벨이 나와 평가 자체가 noisy해집니다.
4. Confidence value(신뢰도)와 threshold(임계값)
개념:
- 신뢰도(Confidence value)는 AI가 스스로 "내가 고른 이 답이 정답일 거야!"라고 확신하는 정도를 뜻하며, 앞서 우리가 이야기했던 '이 단어가 다음에 올 확률(Probability)'과 아주 밀접한 개념입니다.
VLM이 자기 답에 매기는 점수(0.0~1.0)로, 출력 JSON에 직접 포함됩니다. - 임계값(Confidence threshold)은 어떤 변화가 일어나거나 통과시키기 위해 반드시 넘어야 하는 '최소한의 기준선'을 말하며, 우리가 일상에서 흔히 말하는 시험의 '커트라인'이나, 방에 들어가기 위해 넘어야 하는 '문턱'이라고 생각하면 아주 쉽습니다.
즉, "value가 N 미만이면 자동 라벨로 채택하지 않는다"는 판단을 하게 만들어주는 값으로 우리 코드에서 지정합니다. - 만일 분석 결과 신뢰도가 임계값 미만일 때, 정석 처리는 재호출이 아니라 사람이 재라벨하는 큐(human re-label queue)로 보내는 것입니다.
왜냐하면 temperature 0.1에서 같은 클립을 다시 호출해도 거의 같은 답이 나와서 사람이 직접 손을 대봐야 하는 단계기 때문입니다. - 즉, confidence 후처리를 설계할 때 "낮으면 재호출" 대신 "낮으면 사람 큐"로 라우팅 설계를 잡아야 비용 낭비와 오답 반복을 막을 수 있습니다.
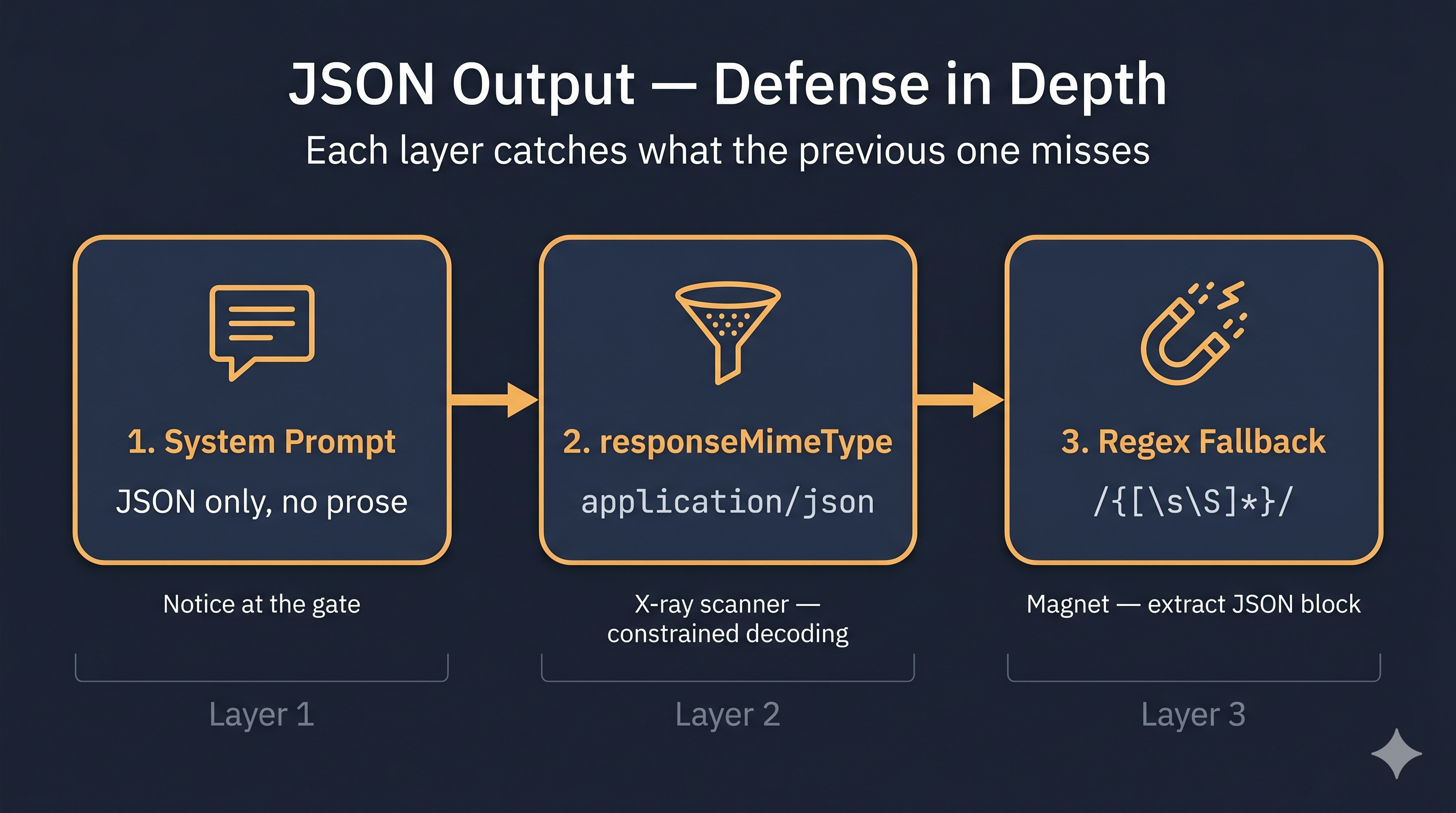
5. JSON 출력 3단 방어
왜 JSON 출력을 하는가요?
- LLM은 언어 모델이기 때문에(VLM도!) 출력 형식이 정해져있지 않습니다.
출력 형식을 통일하면 해석하는데 비용도 줄고, 속도도 빨라져요!
개념
-
LLM의 JSON 출력을 안정적으로 받으려면 단일 방어선으로는 부족합니다.
각 층의 실패 모드가 다르기 때문입니다. -
3층 레이어 구조로 방어해줘야 안정적으로 JSON을 받아낼 수 있습니다.
-
해당 레이어 구조는 아래와 같습니다.
(1) 시스템 프롬프트에 "JSON only, no prose, no markdown fences" 명시
(2) SDK의generationConfig.responseMimeType: 'application/json'으로 constrained decoding을 강제// Gemini SDK generationConfig에 명시 const result = await model.generateContent({ contents: [{ role: 'user', parts: [{ text: userPrompt }] }], generationConfig: { responseMimeType: 'application/json', // 이렇게!! temperature: 0.1, topP: 0.95, }, });(3) 응답에서 필요한 {...} 블록만 추출하는 regex fallback을 두기
실전:
- 이건 LLM호출의 여러 부분에 적용가능한데, 서브에이전트 등 호출시 응답 형식을 정해두면 서브에이전트를 사용하는 에이전트의 효율도 더 올라가는거 같습니다.
- 프롬프트에서 명시해도 JSON으로 안 나오는 경우가 있는데, 이거 때문에 이 팁을 연구한거고 대부분은 (2)항인 responseMimeType이 빠진 경우가 많습니다.
- 프롬프트 한 줄로 해결하려는 시도보다 SDK 설정이 조금 더 확실하게 출력 형식을 정해주는 거 같습니다.
마무리
각 비유는 외우는 도구가 아닙니다. 오개념이 어디서 생기는지를 드러내는 도구입니다. topP 0.5에서 "0개"라고 떠오른다면 날씨 비유로 다시 돌아오고, confidence 미만에서 "재호출"이 먼저 나온다면 학생 시험지 비유로 돌아오면 됩니다. 메커니즘이 잡히면 파라미터 결정에 근거가 생깁니다.
