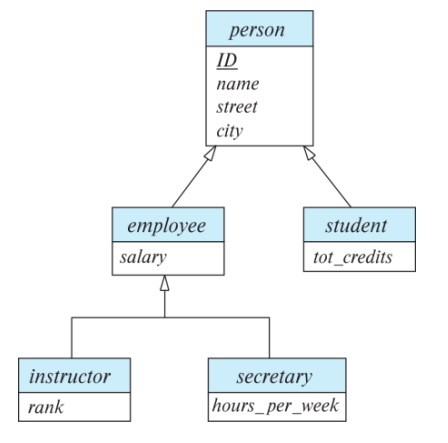
Specialization : Top-down design process
- entity set 내에서 다른 entity들과 구별되는 것들을 모아 sub-grouping을 진행한다.
- 이러한 sub-grouping된 애들은 lower-level entity set이 된다.
- lower-level entity set은 그것과 연결된 higher-level entity set의 속성이나 relationship을 상속받는다
Example
- Overlapping
: 두 subgroup에 모두 소속될 수가 있다.
ex). 학부조교 Tom는 employee와 student 두 entity set에 소속된다
- Disjoint
: 하나의 subgroup에만 소속될 수 있다.
ex). instructor / secretary
- Total and partial
- total : 모든 employee는 instructor 아니면 secretary이다.
- partial : employee와 student가 아닌 person이 있을 수 있댜.
Method 1
-
higher level entity에 대한 schema를 만든다
-
each lower level entity set에 대한 schema를 만든다.
이 때, higher-level entity set의 primary key와 local attributes를 포함시킨다.schema attributes person ID, name, street, city student ID, tot_cred employee ID, salary -
정보의 중복은 줄지만, 찾는 시간이 늘어난다.
Method 2
-
모든 local, inherited attribute을 갖는 entity set에 대한 schema를 만든다
schema attributes person ID, name, street, city student ID, name, street, city, tot_cred employee ID, name, street, city, salary -
정보의 중복이 많아지고, 찾는 시간을 줄어든다.
Generalization : Bottom-up design process
- 같은 특징을 공유하는 entity들을 모아 하나의 higer-level entity set을 만든다.
- 이와 같은 방식 때문에, partial이 불가능하다. 모든 상하 관계가 total이다.
"Partial generalization is the default"
Aggregation
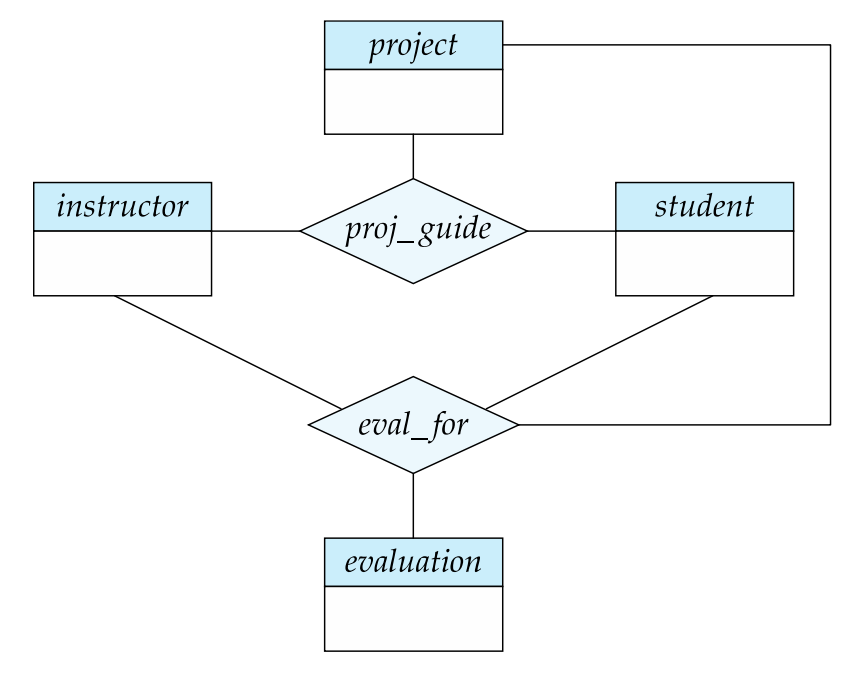
- ternary relationship인 proj_guide를 보자
- 우리는 어떤 project에 대해 instructor가 student에게 준 "evaluation"을 기록하고 싶다.
- 여기서 "proj_guide"와 "eval_for"는 overlapping information을 가지고 있다.
- 모든 "eval_for" 관계는 "proj_guide" 관계에 해당될 수 있다.
- 하지만, 어떤 "proj_guide"는 어떠한 "eval_for"에도 해당되지 않을 수 있다.
- 따라서 "proj_guide"를 제거할 수는 없다.
- 우린 aggregation을 통해 이 중복을 제거한다.
- relationship을 하나의 추상적인 entity로 생각한다
- relationship들 사이의 relationship을 허용한다
- Abstraction of relationship into new entity
(관계를 하나의 entity로 추상화한다)
- 결국, 아래와 같은 diagram을 만들 수 있다
네모 entity와 evaluation entity 사이에 many-to-many 관계인 eval_for를 만들었다.
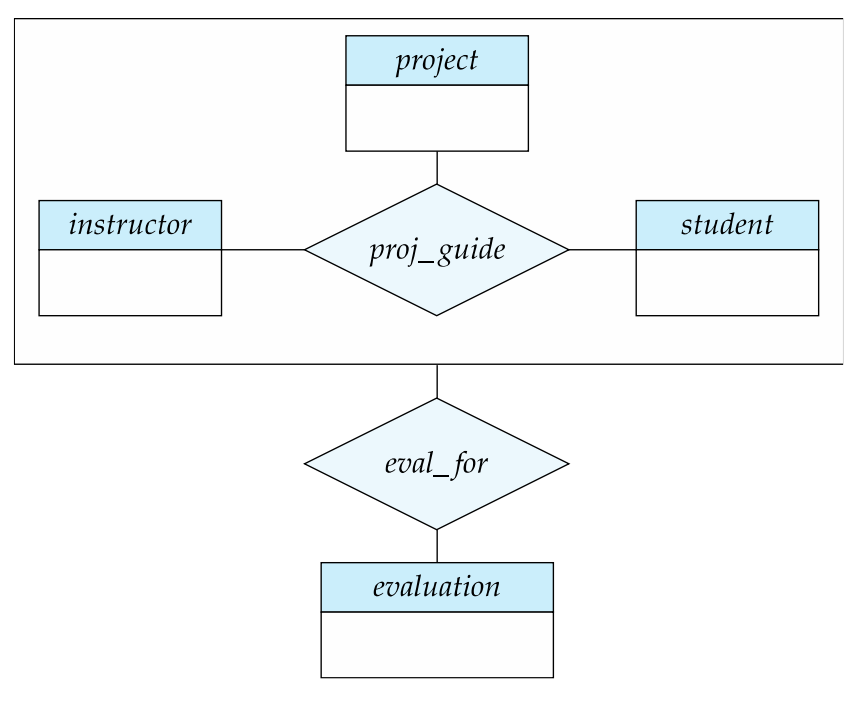
- student는 하나의 project에 대해 instructor의 지도를 받는다
- student, project, instructor combination은 evaluation과 연관이 있을 수 있다. (-> partial임을 의미하는 말)
- 네모칸 되어 있는 combination의 primary key는 ternary relationship proj_guide의 primary key이다
(하나의 entity로 여긴다고 했기 때문에 primary key를 물어보는 것 같다)
- 그렇다면, proj_guide와 eval_for에 대한 두 개의 schema를 만들어야 하냐?
뭐라뭐라 필기 해뒀는데 잘 이해가 안된다.. 아래 내용을 참고하자
Reduction to relational schema
- 이러한 aggregation을 표현하기 위해, schema를 만들어야 한다. 다음 속성들이 포함되어야 한다.
1. aggregated relationship의 primary key- associated entity set의 primary key
- any descriptive attributes
- 위의 예시에서는,
eval_for(s_ID, project_id, i_ID, evaluation_id)로 eval_for relationship에 대한 schema를 생성한다 - the schema proj_guide is redundant. 그렇다고 한다.
- 필기한 내용은 evaluation이 없는 것들은 어떻게 할 지에 대한 내용이었다.
내가 이해한 바로는, 평가가 없다는 뜻으로 특정 evaluation_id를 주고,
이 테이블과 linking되어 있는 예를 들면 실제 grade table에서,
그 특정 값을 가진 애들은 grade를 null로 체크해준다...?
