
Introduction
컴퓨터비전에서의 문제들은 크게 다음 4가지로 분류할 수 있다.
- Classification
- Object detection
- Image segmentation
- Visual relationship
먼저 1, 2, 3의 차이를 살펴보겠다.
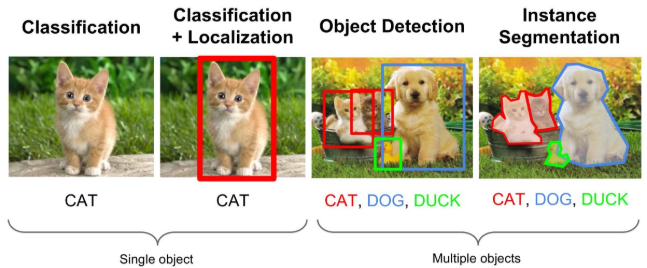
- Classification: single object에 대해서 object의 클래스를 분류하는 문제이다.
- Classification + Localization: Single object에 대해서 bounding box로 찾고 클래스를 분류하는 문제이다.
- Object detection: Multiple objects에서 각각의 object에 대해서 classification + localization 하는 문제이다.
- Instance segmentation: Object detection과 유사하지만 물체를 bounding box로 찾는 것이 아니라 아닌 실제 object의 edge로 찾는다.
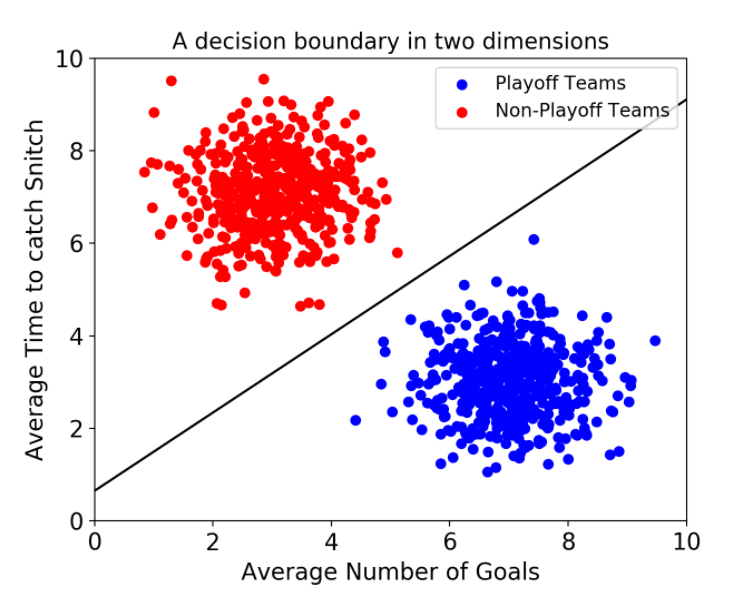
Object detection에는 1-stage detector, 2-stage detector가 있다.
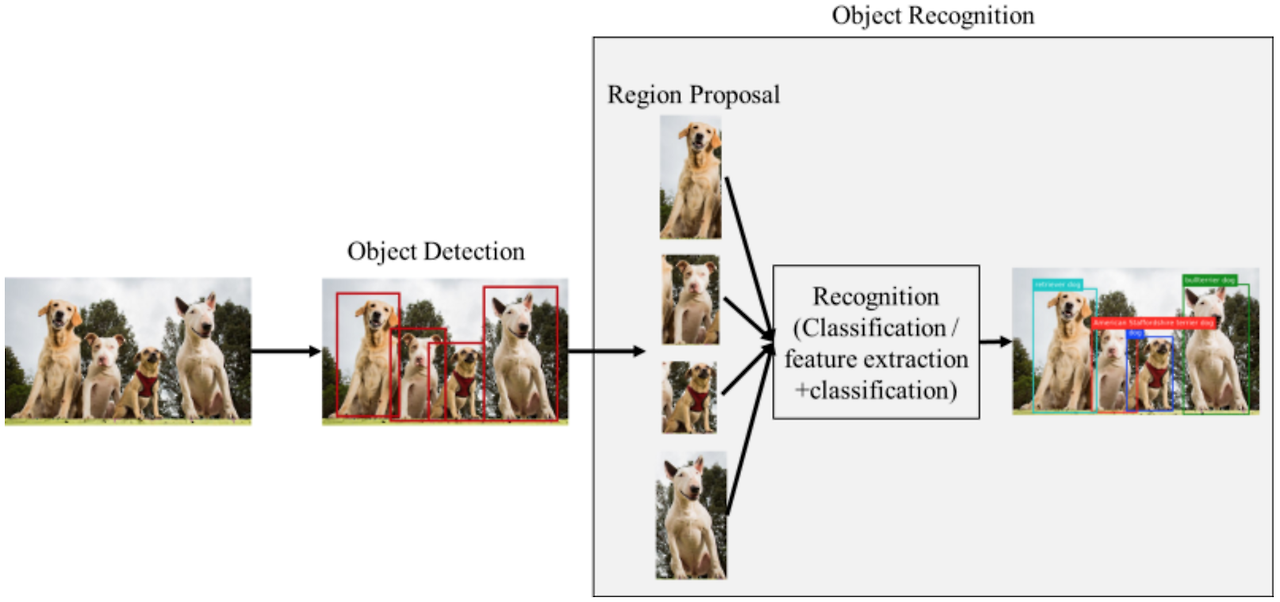
위 그림은 2-stage detector의 동작과정
Selective search, Region proposa network와 같은 알고리즘, 네트워크를 통해 물체가 있을만한 영역을 뽑아낸다. 이 영역을 ROI(Region of Interest)라고 한다.
이 영역을 우선 뽑아내고 나면 convolution을 통해 classification, box regression을 수행한다.
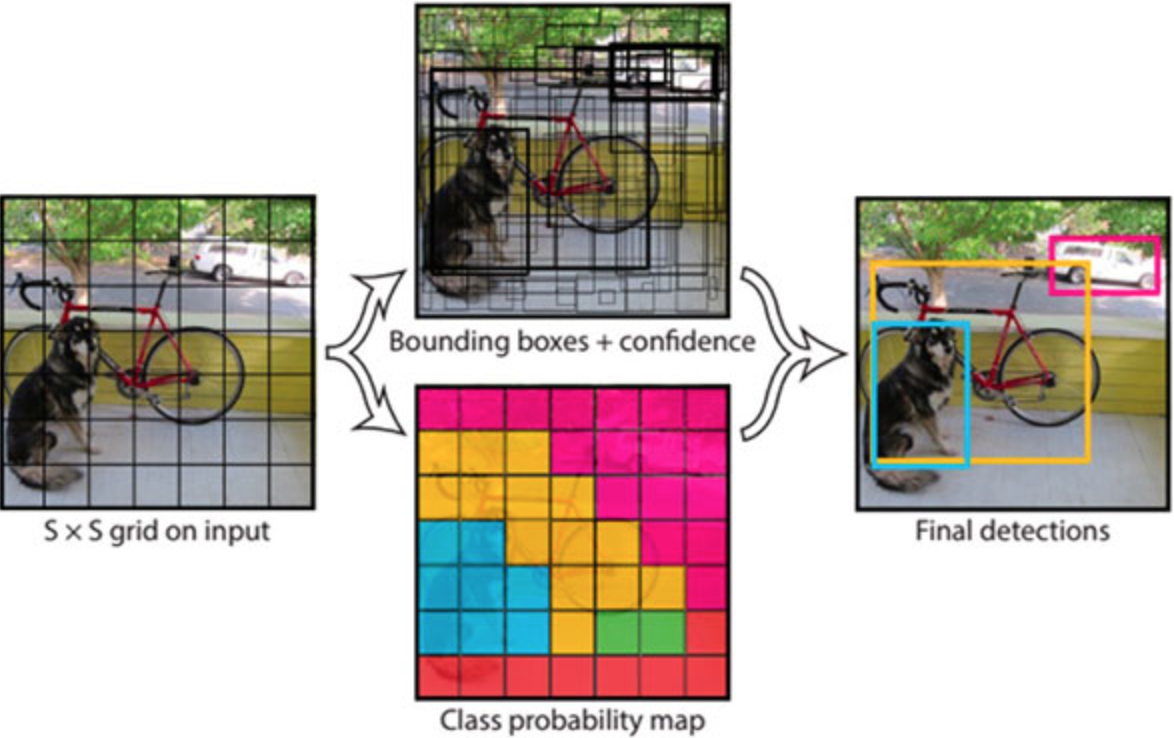
1-stage는 2-stage와 다르게 ROI영역을 먼저 추출하지 않고 전체 image에 대해서 convolution network로 classification, box regression을 수행한다.
당연이 특정 object를 하나만 담고 있는 ROI에서 classification, box regression을 수행하는 것보다 성능은 떨어지지만, 간단한 만큼 속도가 빠르다는 장점이 있다.
R-CNN
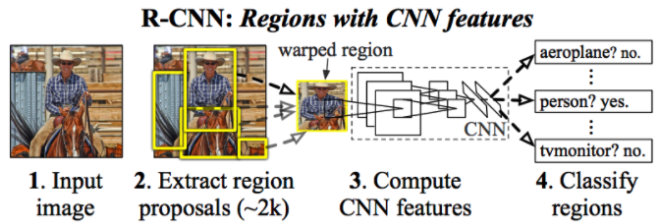
R-CNN은 Image classification을 수행하는 CNN과 localization을 위한 region proposal알고리즘을 연결한 모델이다.
-
입력이미지를 받음
-
2000개의 bottom-up Region proposals 추출 및 생성 (노란 박스)
- SS(Selective Search) 기법을 사용
- CNN 네티워크 입력 사이즈에 맞게 Region proposals의 크기를 warp

- 이러한 region proposal은 detections의 후보 세트를 정의함
- CNN을 통해 Region proposal들의 features를 계산함 -> 고정된 길이의 feature vector를 생성함
warping을 했기 때문에 CNN에 들어가는 feature의 사이즈가 동일하다. 그렇기 때문에 고정된 길이의 feature vector 생성이 가능한 것임!
- 클래스마다 linear SVM 을 적용하여 각 region의 class를 분류한다.
💡 SVM이란?
SVM은 class를 구분하는 선을 긋는 모델이다.
<연구 초반의 2가지 고민들>
- deep network를 이용하여 object를 어떻게 localize할 수 있을까? --> 이미지 내에서 Bound Box를 어떻게 그릴 수 있을까?
-
접근법 1 : localizing을 regression 문제로 접근
-
접근법 1 장점 : 단일 object의 localizing 성능 좋음
-
접근법 1 단점 : 다수 objects의 localizing 성능 저조
-
-
접근법 2 : Sliding-Window 기법 적용
-
접근법 2 장점 : computational efficiency
-
접근법 2 단점 : 모든 object에 동일한 aspect ratio(동일한 윈도우 크기, 비율)을 사용 --> 다양한 object 크기를 반영 못함
-
💡 Sliding-Window란?: 링크
-
접근법 3 : Recognition Using Regions (본문에서 적용한 기법, 위의 R-CNN 개요가 이 기법에 해당하는 내용) --> 본문의 기여점 1
- 접근법 3 장점 : 이 기법은 Detection 및 Segmentation에 모두 성능이 좋음
(2)적은 양의 label된 데이터로 high-capacity모델을 어떻게 학습시킬 수 있을까?
-
이전에 사용했던 방법: Unsupervied Pre-training (with Supervied Fine-Tunning)
-
본문에서 사용한 방법:
-
본문에서 사용한 방법 : Supervised Pre-training --> 본문의 기여점 2
-
대량의 데이터셋(ILSVRC)에서 pre-training
-
domain-specific fine-tuning on a small dataset(PASCAL)
-
이 기법을 사용하여 적은 양의 데이터에서도 효과적인 성능을 보임
-
-
연구방법: Object Detection with an R-CNN
Module design
region proposal을 생성하는 방법들은 다양하다. objectness, selective searuch, category-independent object 등등..
R-CNN은 이전 연구와 성능을 비교하기 위해서 selective search의 방법을 선택했다고 한다.
Feature Extraction
- CNN을 사용하여 각 region proposal에서 고정된 길이의 feature vector를 생성함
- CNN구조는 oxfordnet과 Torontonet을 사용했다고 한다. (둘 다 feature vector는 4096차원)
마지막 vector의 차원수는 분류할 개수에 맞춰야되기 때문에 region을 warp해서 사용했다.
Test-time detection
- 약 2000개의 region proposal을 생성하기 위해 test image에 selective search를 적용했다. (모든 실험에서 selective search의 fast mode를 사용했다고 한다. )
- 그 후, 각 region proposal을 warp한 후, featrue 계산을 위해 CNN으로 forward propagate 진행
- 그 후, 각 클래스마다, SVM을 사용하여 추출된 feature vector의 점수를 매김
- Greedy NMS를 적용
💡Selective Search fast mode란?
selective search는 픽셀의 유사성에 따라 초기 segment를 형성하고, 이 segment들을 결합하여 더 큰 region proposals를 형성하는 방식으로 작동합니다. 이때 병합과정은fast mode와quality mode두 가지의 모드가 있는데quality mode는fast mode보다 보통 더 크고, 복잡한 region proposals을 생성합니다.
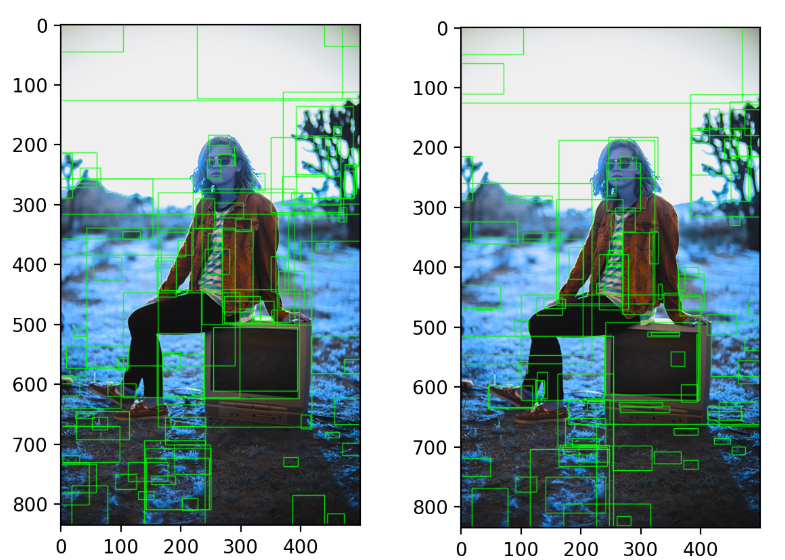
Training
<Supervised Pre-Training>
- CNN의 pre-train에 사용한 데이터 : ILSVRC2012 classification
<Domain-Specific Fine-Tuning>
-
CNN을 새로운 task(detection)와 새로운 도메인(warped proposal windows)에 adapt하기 위해, 오직 warped region proposals를 사용했고 CNN 파라미터의 학습에 SGD를 사용
-
CNN 아키텍쳐는 object의 class가 변경됨에 따라 마지막 레이어가 수정된 것 외에는 동일
-
ILSVRC2013에서는 200개의 class 분류
-
IoU 임계값은 0.5를 사용
-
학습률은 0.001, mini-batch size는 128로 설정
실험 분석
Visualizing learned features
-
첫번째 레이어는 직접적으로 시각화 할 수 있으며 쉽게 이해할 수 있다. 하지만 이후의 레이어는 이해하기 다소 어렵다.
-
네트워크가 어떻게 학습됐는지 직접적으로 보여줄 수 있는 단순한 방법인 'non-parametric method'를 제안한다.
-
이 아이디어는 네트워크에서 특정한 feature를 분리하여 feature 자체를 object detector로 사용하였다.
-
본 논문에서는 TorontoNet의 pool5 레이어의 5번째와 마지막 콘볼루션 레이어를 시각화 하였다.

-
Fig. 4의 각 행은 CNN의 pool5레이어에서 활성화된 상위 16개 unit을 나타낸다.
-
이러한 unit들은 네트워크가 무엇을 학습하였는지 보여주는 대표적인 예시이다.
-
두 번째 행을 보면 강아지의 얼굴과 점들의 배열에 집중했다는 것을 볼 수 있다.
-
본 연구의 대부분의 결과는 TorontoNet 네트워크 아키텍쳐를 사용하였다.
-
하지만 어떠한 아키텍쳐를 사용하는지에 따라 R-CNN의 성능에 큰 영향을 미친다는 것을 발견하였다.
-
Table 3을 보면 ILSVRC 2014 Classification Challenge에서 우수한 성능을 보인 OxfordNet을 VOC 2007 데이터로
test한 결과를 볼 수 있다.
-
OxfordNet은 3x3 커널을 갖는 컨볼루션 레이어 13층과 Max-pooling 레이어 5층, 그리고 마지막 3층의 fcn으로구성되어 있다.
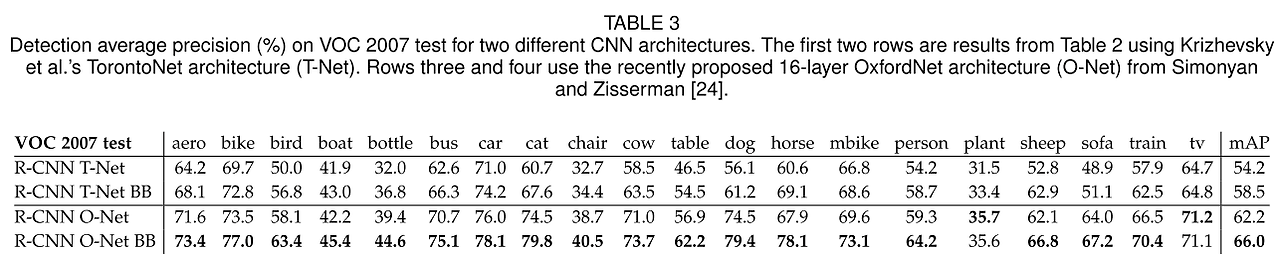
-
Table 3을 보면 OxfordNet이 TorontoNet보다 mAP를 7.5% 향상시킨 것을 확인할 수 있다.(58.5% -> 66.0%)
-
하지만 Compute time은 OxfordNet이 TorontoNet보다 7배가량 오래 걸렸다.
데이터셋 : The ILSVRC2013 Detection Dataset
Dataset overvies
<ILSVRC2013 detection 데이터셋 구성>
* 학습(train) : 395,918 개
* 검증(val) : 20,121 개
* 테스트(test) : 40,152 개 -
검증 및 테스트 데이터셋은 모두 annotate 되어 있음
- annotate 의미 : 각 이미지에 box label이 있음 (200개의 class)
-
반면 학습 데이터셋의 annotate는 일부 누락
-
각 데이터셋 중에 negative image들은 사용되지 않음
- negative image : label 정보가 아에 없는 이미지들(?)
< R-CNN의 전략>
-
val 데이터셋을 학습과 검증에 모두 사용하기 위해, val 데이터셋을 동일한 크기로 2분할 --> val1, val2
-
val 데이터셋에서 어떤 class는 갯수가 적기 때문에, class-balance를 맞출 필요가 있음
- 가장 적은 class 데이터 갯수는 31개, 그리고 절반 이상의 class는 110개 이하
Conclusion
-
이전까지 object detection에서 가장 좋은 성능을 보인 모델 : 복잡한 앙상블 모델
- object detectors와 scene 분류기를 통해 low-level image feature를 high-level context를 병합
-
본문에서는 R-CNN이라는 간단하고 확장가능한 detection 모델을 소개
-
이는 PASCAL VOC 2012기준 이전까지 가장 좋았던 모델보다 50%가량 성능이 좋음
-
아래의 두 가지 insights를 통해 최고 성능을 발휘
(1) object를 localize하기 위해 CNN에 bottom-up region proposals(Selective Search)를 접목
(2) 라벨링 된 데이터가 부족할 때, large CNN을 학습하는 paradigm.
-
풍부한 데이터(image classification)로 네트워크를 pre-train한 후, 데이터가 부족한(detection) task를 수행하는 네트워크를 fine-tune하는 것이 효과적
-
이를 supervised pre-training/domain-specific fine-tuning 이라고 부름
