
🔹 들어가며
기존의 이미지 분류 모델들은 CNN(Convolutional Neural Networks)을 기반으로 발전해 왔다. CNN은 지역적인 특징을 학습하는 데 매우 효과적이지만, 글로벌한 정보를 다루는 데 한계가 있다. 이를 해결하기 위해 Google Research는 Vision Transformer (ViT)을 제안하였으며, 이는 트랜스포머(Transformer) 구조를 활용하여 이미지를 처리하는 새로운 방법론이다.
ViT는 이미지를 패치(Patch) 단위로 분할하여 텍스트 데이터처럼 처리하며, 트랜스포머의 자기 주의(Self-Attention) 메커니즘을 활용하여 장기적인 의존 관계를 학습할 수 있도록 설계되었다. 이번 리뷰에서는 ViT의 핵심 개념과 작동 원리를 살펴보겠다.
✅ Vision Transformer의 핵심 개념
🟠 이미지 패치 분할
CNN과 달리, ViT는 이미지를 작은 패치(Patch)로 나누어 이를 일종의 단어 토큰처럼 처리한다. 주어진 입력 이미지 가 있을 때, 이를 크기의 패치로 분할하여 개의 패치를 만든다.
여기서,
- 는 이미지의 높이와 너비
- 는 채널 수
- 는 한 패치의 크기
- 은 생성된 패치의 개수
이렇게 생성된 패치는 Flatten 과정을 거쳐 벡터 형태로 변환된다. 즉, 각 패치 를 1D 벡터 로 변환한다.
🟠 패치 임베딩
이제 변환된 패치를 선형 변환(Linear Projection)을 적용하여 임베딩 벡터로 만든다.
여기서,
- 는 학습 가능한 가중치 행렬
- 는 바이어스 벡터
- 는 모델의 차원
이제 각 패치를 Transformer 입력으로 사용할 수 있도록 정제된 패치 임베딩 벡터가 생성되었다.
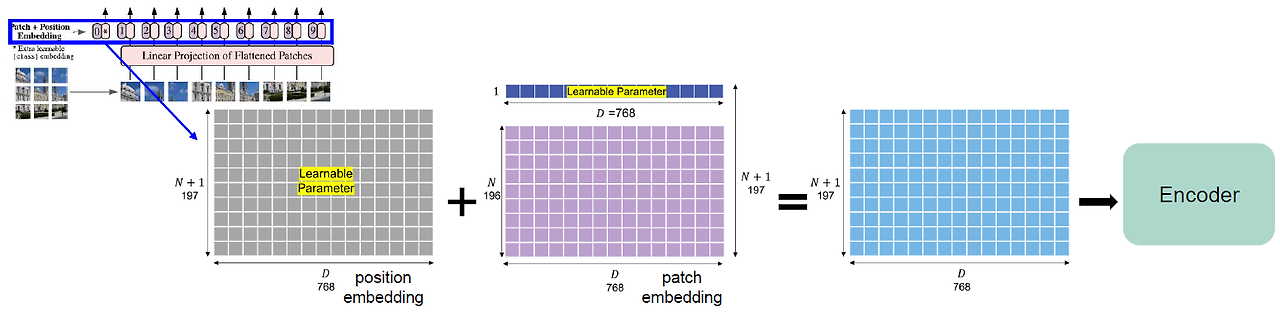
🟠 클래스 토큰(Class Token) 추가
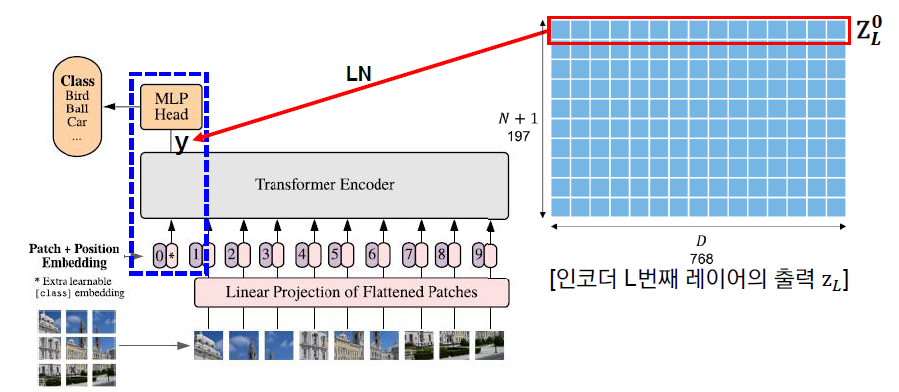
NLP에서 BERT 모델이 문장의 대표 정보를 담기 위해 [CLS] 토큰을 사용하듯이, ViT에서도 클래스 토큰()을 추가하여 최종 분류에 활용한다.
여기서,
- 는 학습 가능한 클래스 토큰
- 는 위치 임베딩(Position Embedding)
위치 임베딩은 트랜스포머가 패치의 순서를 학습할 수 있도록 도와준다.
✅ Transformer Encoder를 이용한 이미지 처리
ViT는 트랜스포머의 Encoder 블록을 사용하여 이미지 패치 간의 관계를 학습한다. 각 인코더 블록은 다음과 같은 주요 구성 요소로 이루어진다.
- 멀티 헤드 셀프 어텐션 (Multi-Head Self Attention, MHSA)
- MLP (Feed-Forward Network, FFN)
- Layer Normalization (LN) 및 Residual Connection
🟠 멀티 헤드 셀프 어텐션 (MHSA)
각 패치는 서로 다른 패치들과의 관계를 학습하기 위해 Self-Attention을 사용한다. 이는 다음과 같이 계산된다:
여기서,
- 는 각각 Query, Key, Value 행렬
- 는 학습 가능한 가중치 행렬
- 는 차원 수 스케일링 값
이 과정이 여러 개의 헤드(Head)에서 병렬적으로 수행되며, 마지막에 이를 합치는 과정이 포함된다.
🟠 MLP 및 최종 분류
트랜스포머 블록을 여러 개 통과한 후, 최종적으로 클래스 토큰()을 활용하여 이미지의 클래스를 예측한다.
여기서,
- 는 출력층의 가중치 행렬
- 는 예측된 클래스 확률 분포
✅ ViT의 성능 및 CNN과의 비교
ViT는 트랜스포머 기반 모델로서 기존의 CNN과는 다른 방식으로 이미지를 처리한다. 그렇다면 ViT는 CNN 대비 어느 정도의 성능을 보이며, 어떤 장점과 단점을 가지고 있을까? 이번 섹션에서는 ViT의 성능을 분석하고 CNN과 비교하여 그 차이를 살펴보겠다.
🔹 ViT vs. CNN: 성능 비교
ViT는 대규모 데이터셋에서 우수한 성능을 발휘하는 것으로 알려져 있다. 논문에서는 ImageNet-1K, ImageNet-21K, JFT-300M 등의 데이터셋에서 ViT와 CNN의 성능을 비교하였다.
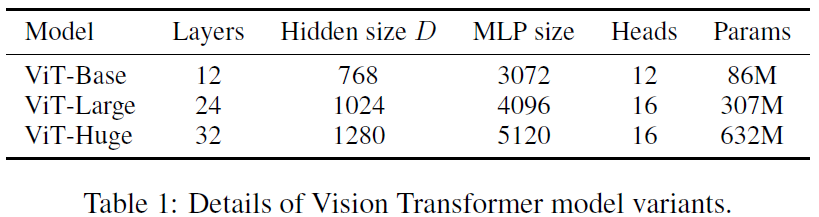
baseline
ResNet with Group Normalization & Standardized Convolutions (BiT)
Hybrids
ViT에 ResNet의 stage 4 feature map을 입력으로 넣어주고 patch size = 1로 설정

- optimizer: Adam for Pre-training and SGD for fine-tuning
- batch size: 4096
- linear warmups + Learning Rate Decay (Cosine or Linear)
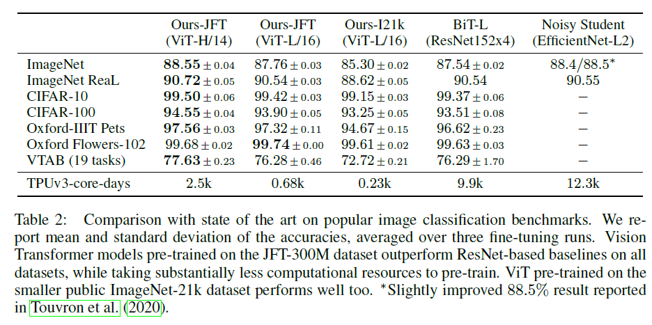
전이학습 평가를 위한 각 데이터셋 별 ViT 모델과 기존 전이학습 SOTA CNN 모델과의 (BiT-L / NoisyStudent) 성능 비교
- fine-tuning을 각각 3번 진행하고 정확도의 평균과 표준편차를 계산하여 정확성을 평가
- TPUv3-core-days = 사전학습 시 사용된 코어 수 X 소요 일수 (효율성을 평가하는 지표)
- 중간 사이즈의 데이터셋: Baseline > ViT ; 큰 사이즈의 데이터셋: ViT > Baseline
- ViT의 경우 모델 파라미터(모델 규모)가 증가하고, 데이터셋의 크기가 증가할 수록 지속적으로 성능이 증가. (no saturation)
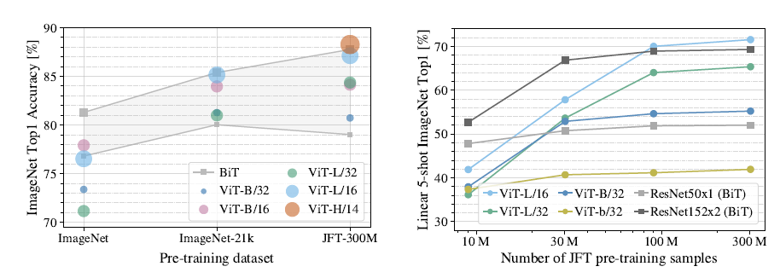
이 결과에서 볼 수 있듯이, ViT는 사전 훈련을 충분히 거쳤을 때 CNN보다 높은 성능을 보인다. 특히, 더 큰 데이터셋에서 학습할수록 성능이 더욱 향상되는 경향을 나타낸다.
하지만, 데이터가 부족한 경우 CNN이 더 좋은 성능을 보이는 경우도 존재한다. 이는 ViT가 패치 단위로 이미지를 처리하기 때문에, 지역적인 특징을 잘 학습하는 CNN보다 적은 데이터에서 일반화하는 능력이 떨어질 수 있기 때문이다.
✅ ViT의 장점과 단점
🟠 ViT의 장점
- 장기적인 의존성(Long-range Dependency) 학습 가능
- CNN은 지역적인 필터를 사용하여 정보를 처리하지만, ViT는 Self-Attention 메커니즘을 통해 전역적인 정보를 학습할 수 있음
- 유연한 구조
- CNN과 달리 고정된 커널 크기가 없고, 다양한 크기의 이미지에도 적용 가능
- 대규모 데이터에서 우수한 성능
- ImageNet-21K나 JFT-300M과 같은 대규모 데이터셋에서 CNN보다 더 뛰어난 성능을 보임
🔵 ViT의 단점
-
대량의 데이터 요구
- 작은 데이터셋에서는 CNN보다 성능이 낮을 수 있음
- 따라서 데이터 증강(Augmentation) 기법이나 사전 훈련(Pre-training)이 필수적
-
높은 계산 비용
- Self-Attention 연산이 의 시간 복잡도를 가지므로, 큰 이미지에서는 연산 비용이 증가
- 이를 해결하기 위해 Swin Transformer와 같은 효율적인 트랜스포머 모델이 등장함
-
해석 가능성이 낮음
- CNN의 컨볼루션 필터는 특정 패턴(예: 에지, 텍스처 등)을 학습하는 것이 비교적 명확하지만, ViT의 어텐션 맵은 직관적으로 해석하기 어려움
