
1.0 Introduction
Word2Vec이나 Skip-gram 등 이전 모델들은 각 단어가 한 개의 벡터로만 표현됩니다. 이렇게 한 개의 벡터로만 표현된다면 문법구조나 다의어에 따른 뜻 변형을 적절히 반영하기 어렵습니다. 예를 들어서 임베딩 방법론으로 present란 단어를 임베딩하였다고 하면, 이 단어가 선물이라는 뜻으로 사용될 때도 있고 현재라는 뜻으로 사용될 수도 있음에도 불구하고 모두에서 동일한 벡터가 사용됩니다.
그렇다면 같은 표기의 단어라도 문맥에 따라서 다르게 워드 임베딩을 할 수 있으면 자연어 처리의 성능이 더 올라가지 않을까요? 단어를 임베딩하기 전에 전체 문장을 고려해서 임베딩을 하겠다는 것이죠. 그래서 탄생한 것이 문맥을 반영한 워드 임베딩(Contextualized Word Embedding)입니다.
ELMo는 Embeddings from Language Model의 약자로 해석하면 '언어 모델로 하는 임베딩'입니다. ELMo의 가장 큰 특징은 사전 훈련된 언어 모델(Pre-trained language model)을 사용한다는 점입니다. 즉, 엘모는 사전훈련과 문맥을 고려하는 문맥 반영 언어 모델입니다. 또한, 이 representation은 (문장 내) 각 token이 전체 입력 sequence의 함수인 representation를 할당받는다는 점에서 전통적인 단어 embedding과 다릅니다. 이를 위해 이어붙여진 language model(LM)로 학습된 bidirectional LSTM(biLM)로부터 얻은 vector를 사용합니다.
또한, lstm의 마지막 레이어만 사용하는 기존의 방법론과는 달리, ELMo는 lstm의 모든 내부 레이어를 사용해서 만들어지기 때문에 더욱 많은 정보를 사용할 수 있다.
• higher-level LSTM : 문맥을 반영한 단어의 의미를 잘 표현
• lower-level LSTM : 단어의 문법적인 측면을 잘 표현
왜 higher-level LSTM과 lower-level LSTM이 잘 표현할 수 있는 부분이 다를까?
1. Lower-level LSTM: 문법적 정보
LSTM의 하위 계층에서는 주로 원래의 입력 시퀀스(단어 시퀀스)를 학습합니다. 이 과정에서, 모델은 단어의 형태나 문법적인 요소, 어순과 같은 로우 레벨 정보를 파악합니다.
Lower-level LSTM은 주로 구조적 정보에 집중합니다. 예를 들어, 단어의 형태소, 품사, 수식관계, 문장의 기본 구조 등을 학습하여 문법적으로 정확한 표현을 위한 기초적인 정보를 제공합니다.
2. Higher-level LSTM: 문맥적 의미
반면, 상위 계층인 higher-level LSTM은 하위 계층에서 추출된 문법적, 구조적 정보를 바탕으로 더 추상화된 의미나 문맥을 학습합니다.
Higher-level LSTM은 문장에서 단어의 위치나 형태보다는 그 단어가 문맥 속에서 가지는 의미나 역할에 더 집중합니다. 예를 들어, 단어가 문맥에 따라 달라지는 의미를 반영하여 더 풍부한 표현을 가능하게 합니다.
이는 문장에서 같은 단어라도 상황에 따라 달라지는 의미를 이해하는 데 중요한 역할을 하며, 이를 통해 모델은 더 높은 수준의 문맥적 이해를 제공합니다.
- GPT의 대답인데 명확하진 않은 것 같다.
의미론적 관점으로는 Low-level에서는 단어의 sequence 그대로 word의 embedding값이 들어오기 때문에 단어의 순서나 구조에 집중을 한다고 생각을 했고 High-level에서는 low-level부터 추출된 문장의 특징들이 모여 조금 더 전체적인 부분을 보는 것이 아닐까? 생각했다.
2.0 Model
2.1 Bidirectional language models

다음은 일반적인 forward model의 예측 과정이다.
이전의 토큰들이 주어졌다고 가정을 했을때 다음 token을 예측하는 것이다.
수식은 bayes rule로 유도가 가능하다.
논문에서 를 independent token representation이라고 했는데 이것은 pretrain된 embedding에서 나온 값을 사용한 걸 말한다.
는 j번째 LSTM layer에서 나온 k번째 token의 embedding 값을 말한다. 위의 forward model의 수식처럼 이전의 token값에 영향을 받기 때문에 context-dependent representation이라고 한다.

다음은 backward부분이다. 수식은 forward와 동일하다.

Loss는 forward와 backward의 Cross entropy Loss의 합으로 사용한다. (가중치는 없으므로 둘 다 동일한 중요도를 가진 것으로 판단하는 듯하다.)

2.2 ELMo
전체의 표현은 2L+1개라고 하는데 이것은 forward LSTM의 Layer L개 + backward LSTM의 Layer L개 + 처음 들어가는 word의 embedding vector 1개로 이루어져 있다.

그래서 이걸 어떻게 사용하는가?
forward와 backward의 hidden state를 선형결합해서 사용한다.
그냥 막대기 두개를 붙혔다고 생각하면 된다.
[ ; ] ( 가로로 이어붙이기 )
그런데 전체의 표현은 짝수가 아니었다.
초기 embedding값이 가 1개이기 때문
이 값을 과 동일한 것으로 가정을 하고 형태를 맞춰주기 위해 같은 embedding값을 복사해서 사용한다.

K번째 token에 대한 ELMo의 output은 다음과 같다. 각 Layer에 의 가중치를 곱한다. (layer마다 가중치가 따로 존재함)
는 output에 대한 scale factor이다.
자 이제 보기 쉽게 그림으로 정리를 해보자!
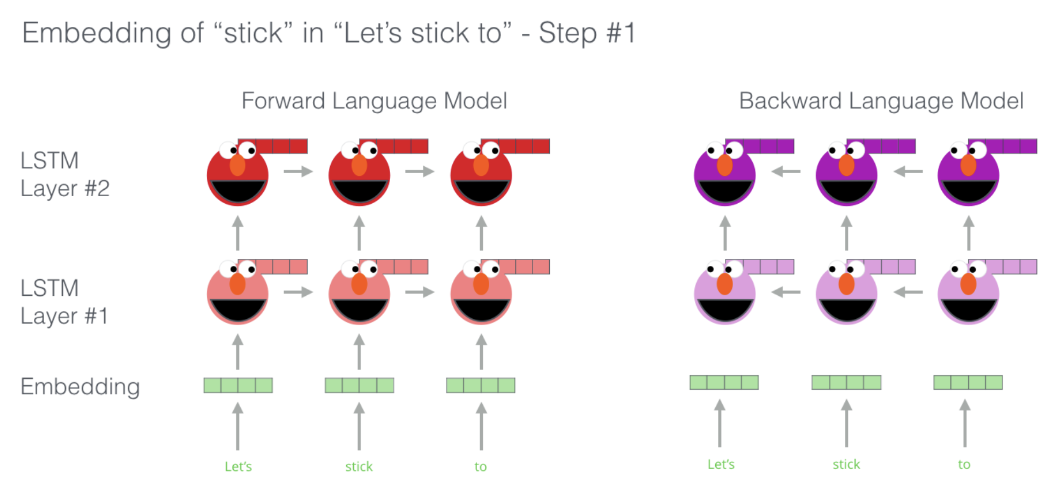
각 layer의 embedding값을 구한다.

구한 forward와 backward의 embedding 값을 선형 결합한다.
그리고 해당 값에 가중치S를 곱해서 합친다.
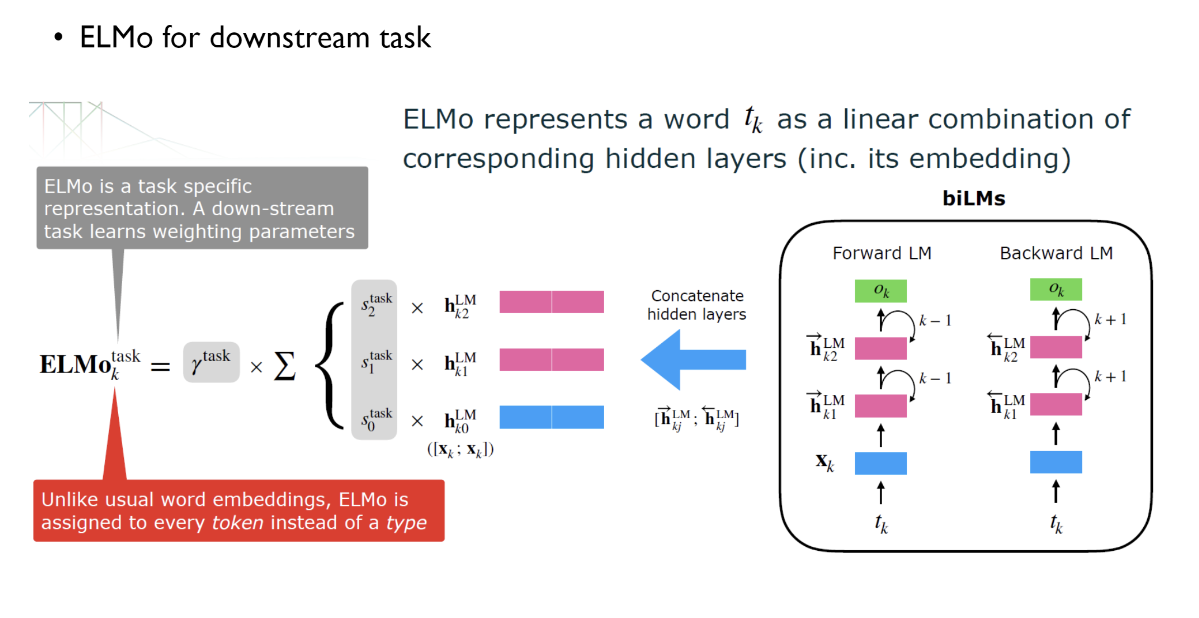
output을 구하는 과정은 다음과 같다.
3.0 Performance

SOTA모델에 대해서 ELMo를 쓰지 않은 것보다 ELMo를 사용했을때의 성능이 높아졌다고 한다.
- 다음은 ELMo의 사용법에 대한 성능의 비교이다.
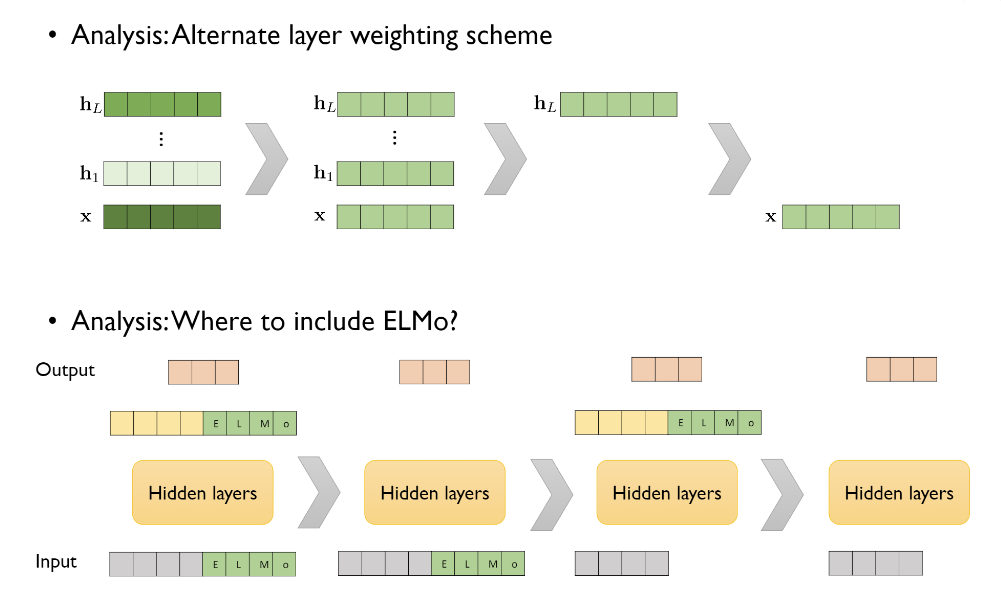
자세히 보면 Embedding값에 대해서 가중치S를 다르게 준 것은 각 embedding 값의 색깔이 다른 것을 알 수 있다.
- 성능비교 결과
S를 다르게 줬을때 > S를 동일하게 줬을때 > 마지막 layer만 사용했을때 > 첫 layer만 사용했을때
엘모를 어느 부분에 사용하면 좋을지에 대한 내용도 아래 나와있다. input과 output전 layer에 사용을 했을때 결과 값이 가장 좋았다고 한다.
4.0 Conclusion
ELMo(Embeddings from Language Models)는 보다 일반화된 임베딩(embedding) 값을 생성하기 위해 고안되었다. 기존 임베딩 기법들은 주로 각 단어에 고정된 벡터를 할당했지만, ELMo는 문맥에 따라 단어의 의미가 달라질 수 있음을 반영하고자 했습니다. 이를 위해 문장의 양방향 LSTM을 통해 단어의 문맥적 의미를 동적으로 파악하고, 문장 내 위치와 주변 단어들에 따라 달라지는 임베딩을 생성하여 다양한 문맥에서 일반화된 임베딩을 제공할 수 있다.
