AI Agent는 정보를 언어로 작성된 프로그램입니다.
AI Agent는 사용자나 외부에서의 요청을 인지하고 분석, 추론, 계획, 정보 획득, 외부와의 상호작용, 피드백 등의 과정을 거쳐 그것을 해결하고자 시도하는 프로그램입니다. 요청에서 응답까지 필요한 여러 요소들 중, 정보 획득은 Agent의 보급에 큰 영향을 미쳤습니다. 왜 그럴까요?
AI Agent는 LLM에 기반하기 때문에 맥락 학습(In-context learning)이라는 강력한 장점을 공유합니다. 맥락 학습은 사용 시점에 추가적인 정보를 학습시키는 것으로, 이를 통해 마치 우리가 하드웨어와 소프트웨어를 독립적으로 다루듯 중심 모델(GPT, Claude, Gemini, etc)과 Agent를 독립적으로 다룰 수 있게 만들었습니다. 그 결과, AI Agent는 낮은 비용으로도 개발 및 사용할 수 있게 되었습니다.
이런 추세에 따라 현재 시점에서 AI Agent를 개발한다는 것은 도메인에 적합하게 모델을 학습하는 것보다, 도메인에 적합한 정보를 제공하는 방법을 고민하고 있습니다. 그럼 어떻게 정보를 제공해야 할까요? 사실, 단순한 기능(일회성 QA 등)만 제공하는 Agent라면 복잡한 방법을 사용할 필요 없이 관련된 모든 정보를 중심 모델에 제공해도 괜찮을 수 있습니다. 모델들은 갈수록 더 많은 맥락과 맥락 속에서 더 정확하게 정보를 찾을 수 있도록 향상되고 있기 때문입니다. 하지만, 이런 접근 방식은 비용, 속도, 보안 등 다양한 요소에서 부적절하고 머지않아 한계에 다다르게 됩니다.
적절한 정보를 제공하기 위해서는 우선 정보란 무엇인지 알아야 합니다. 특정 도메인(IoT, 스마트 시티 등)과 플랫폼, 서비스는 자신만의 용어, 개체, 관계 등을 보유하고 있습니다. 지식 표현(Knowledge Representation) 관점에 따라 이들은 Ontology와 Knowledge Graph로 정리될 수 있습니다.
| 정의 | 설명 |
|---|---|
| Ontology | 도메인에 대한 일반화된 선언문으로, 용어와 일반적인 관계 등을 정의한 표현법 |
| Knowledge Graph | 도메인에서 실제로 생성되는 개체와 개체간 관계를 정의한 표현법 |
Ontology에 따라 정리된 도메인은 Knowledge Graph를 통해 실제 개체 사이의 연관성을 파악할 수 있습니다. 또한, 서로 다른 도메인이 Knowledge Graph를 통해 연결될 수 있기에 확장 가능한 형태로 도메인 정보를 관리할 수 있습니다. 이러한 내용에서 알 수 있듯 이것은 데이터 사전(Data Dictionary)를 만드는 것과 크게 다르지 않습니다. 따라서 이미 데이터 사전을 갖고 있었다면 그것을 사용할 수 있고, 만약 없다면 지식 표현을 구축함으로써 표준화되고 일반화된 데이터 사전을 함께 만들 수 있습니다.
AI Agent가 사용하는 정보는 위와 같이 간략히 정리할 수 있습니다. 이제 처음 질문으로 돌아가 어떻게 정보를 제공할 것인가를 고민할 필요가 있습니다. Agent가 받아들일 수 있는 맥락은 제한되어 있기 때문에, 요청을 해결하는데 필요한 정보만을 제공해야 합니다. 컴퓨터에 빗대어 생각하면, 한정된 메모리에 최적의 데이터를 올리는 것과 유사합니다. 이를 위해서는 정보를 쪼개고, 연관된 정보를 묶으며, 이들을 찾을 수 있어야 합니다. 상호작용의 관점에서 정보는 다음과 같이 나뉠 수 있습니다.
| 유형 | 설명 | 유사 정의 |
|---|---|---|
| 일시적인 정보(Episodic) | 하나의 주제에 대한 상호작용 | 대화(Multi-turns) |
| 작업에 대한 정보(Working) | 하나의 주제에 대한 상호작용 결과 | 주제(Topic) |
Working Memory는 Episodic Memory를 요약한 것으로, 압축된 정보를 생성합니다. 이와 유사하게 도메인 정보 역시 세부 요소에 따라 나뉘고, 이들에 대해 압축된 정보를 가질 수 있습니다. 이렇게 나뉜 정보들은 검색 가능한 형태로 색인되며, Agent의 한정된 메모리에 가장 적절한 정보만이 올라갈 수 있도록 구성됩니다. 이에 대한 도식은 아래와 같습니다.
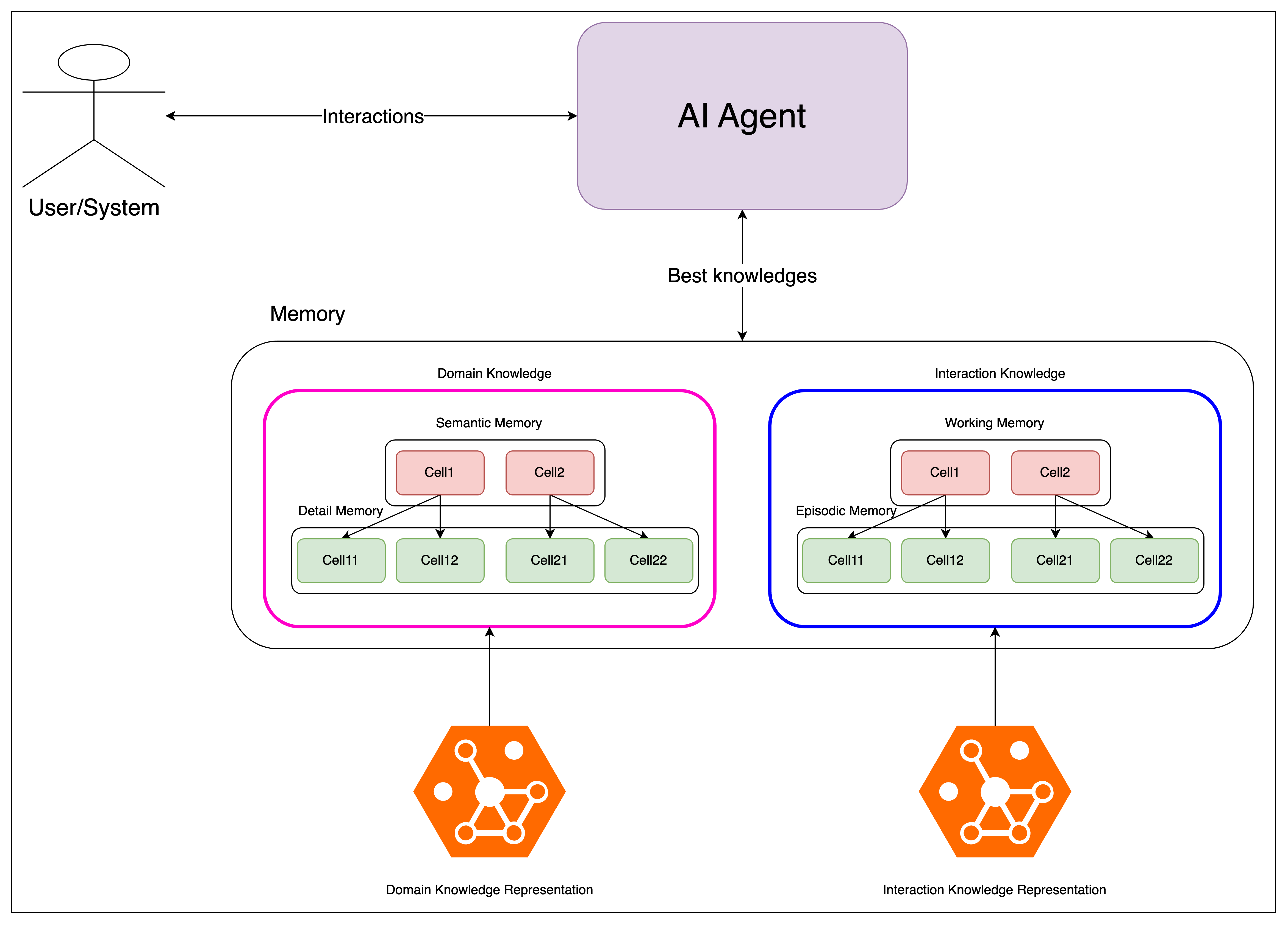
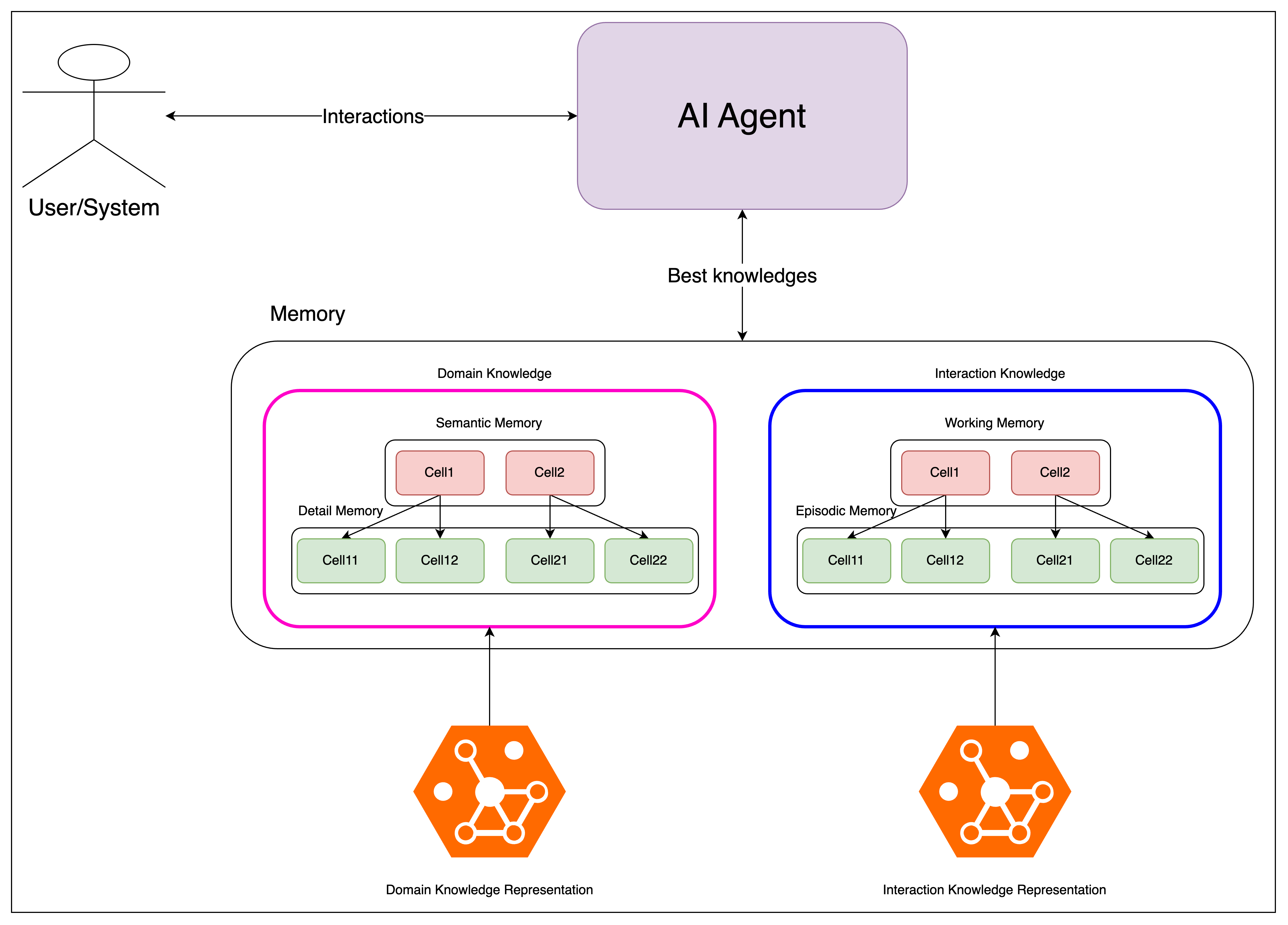
AI Agent는 외부 사용자와의 상호작용에 필요한 최적의 정보를 메모리에 갱신하고, 그것을 사용하여 응답합니다. 메모리는 도메인과 상호작용이라는 두 개의 영역으로 나뉘고, 각 영역마다 핵심 정보와 그와 연관된 세부 정보들로 채워집니다. 즉, 메모리는 일종의 계층 구조로 구성되며 이러한 구조를 통해 추가적인 정보가 필요할 때 정보간 연관성을 잃지 않고 확장될 수 있습니다.
마지막으로 고민해야 할 문제는 메모리를 어떻게 갱신할 것인가? 입니다. 메모리는 한정되어 있기 때문에 현재의 상호작용과 가장 관련성이 높은 정보만으로 메모리를 유지해야 합니다. 이를 위해 일반적인 캐시 전략을 도입해볼 수 있습니다. FIFO(First-In, First-Out)나 LRU(Least Recently Used) 같은 전략을 사용함으로써 메모리를 매번 초기화 후 갱신하지 않고도 적절한 정보를 남겨둘 수 있습니다. 관련성이 높은 정보인지는 핵심 정보(Semantic/Working Memory)의 적중 여부(Hit Ratio)를 통해 검증 가능하며, 불일치 시 연관된 세부 정보를 함께 지움으로써 관련성 없는 정보를 제거할 수 있습니다.
AI Agent는 이전에는 자동화할 수 없던 것들을 자동화하고 있습니다. Agent가 이를 할 수 있던 핵심 요소는 맥락 학습으로, 기반 모델과 정보를 분리시켜 마치 프로그래밍하는 것처럼 정보의 조합으로 Agent를 만들 수 있게 하였습니다. 현재까지도 어떻게 정보를 제공하는가에 대한 명확한 지침은 없기 때문에 앞으로 더 효율적인 기법이 나오기를 기대합니다.
참고 자료
