1. 구현사항
- 메뉴
- 카테고리
- 음료 이름
- 영양 정보
- 알러지
- 음료 이미지
- 음료 설명
- 신상 여부
1-1. 메뉴
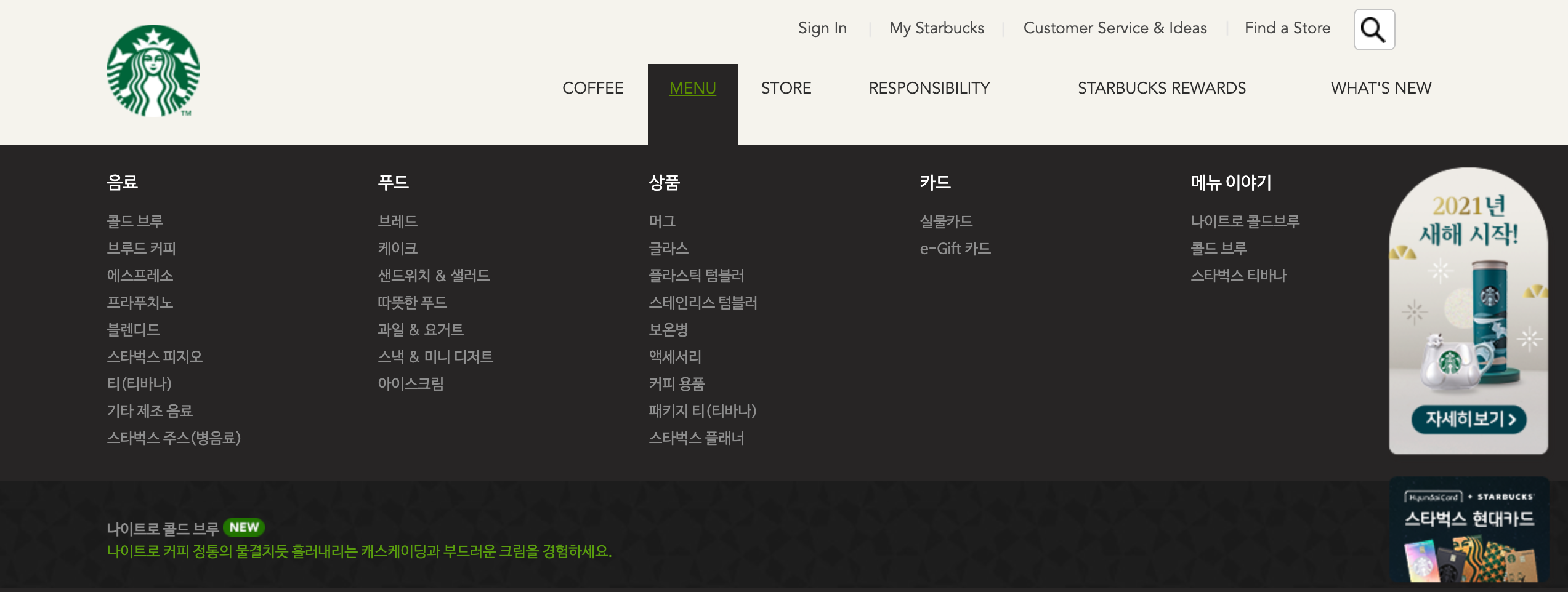
메뉴 에는 음료 / 푸드 / 상품 / 카드 가 있고,
→ 이중에서 음료페이지를 모델링 하려고 한다.
| ID | MENU |
|---|---|
| 1 | 음료 |
| 2 | 푸드 |
| 3 | 상품 |
| 4 | 카드 |
1-2. 카테고리
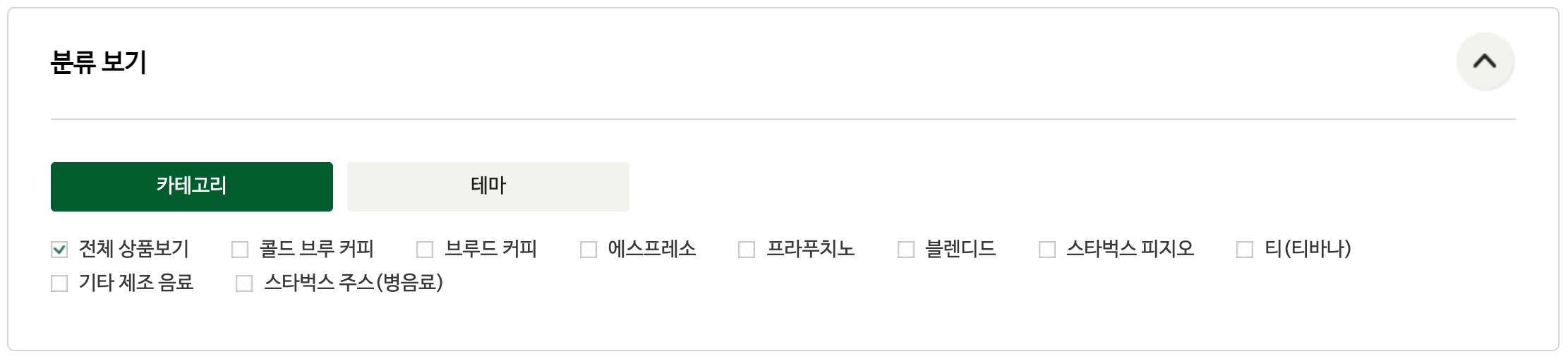
음료 에는 다시 콜드 브루 / 부르드 / 에스프레소 / 프라푸치노 / 블렌디드 / 스타벅스 피지오 / 티(티바나) / 기타 제조 음료 / 스타벅스 주스(병음료) 가 있다.
→ 표로 만들어보면 아래와 같다.
| ID | MENU | CATEGORY |
|---|---|---|
| 1 | 음료 | 콜드 브루 |
| 2 | 음료 | 브루드 커피 |
| 3 | 음료 | 에스프레소 |
| ... | ... | ... |
🤚🏻 이렇게 나열 해보면 우선 MENU 부분에서 음료 가 계속 중복(=반복)된다는 것을 알 수 있다.
👏🏻 그럼! 일단 이부분을 나중에 정규화를 시켜줘야겠다고 생각하고 다음부분을 계속 확인해보자!
정규화 : 중복되는 데이터들을 여러 테이블에 나누어 저장해 필요한 테이블끼리 연결시킴으로써 중복된 데이터를 저장하지 않도록 하는 과정을 말한다.
1-3. 음료이름
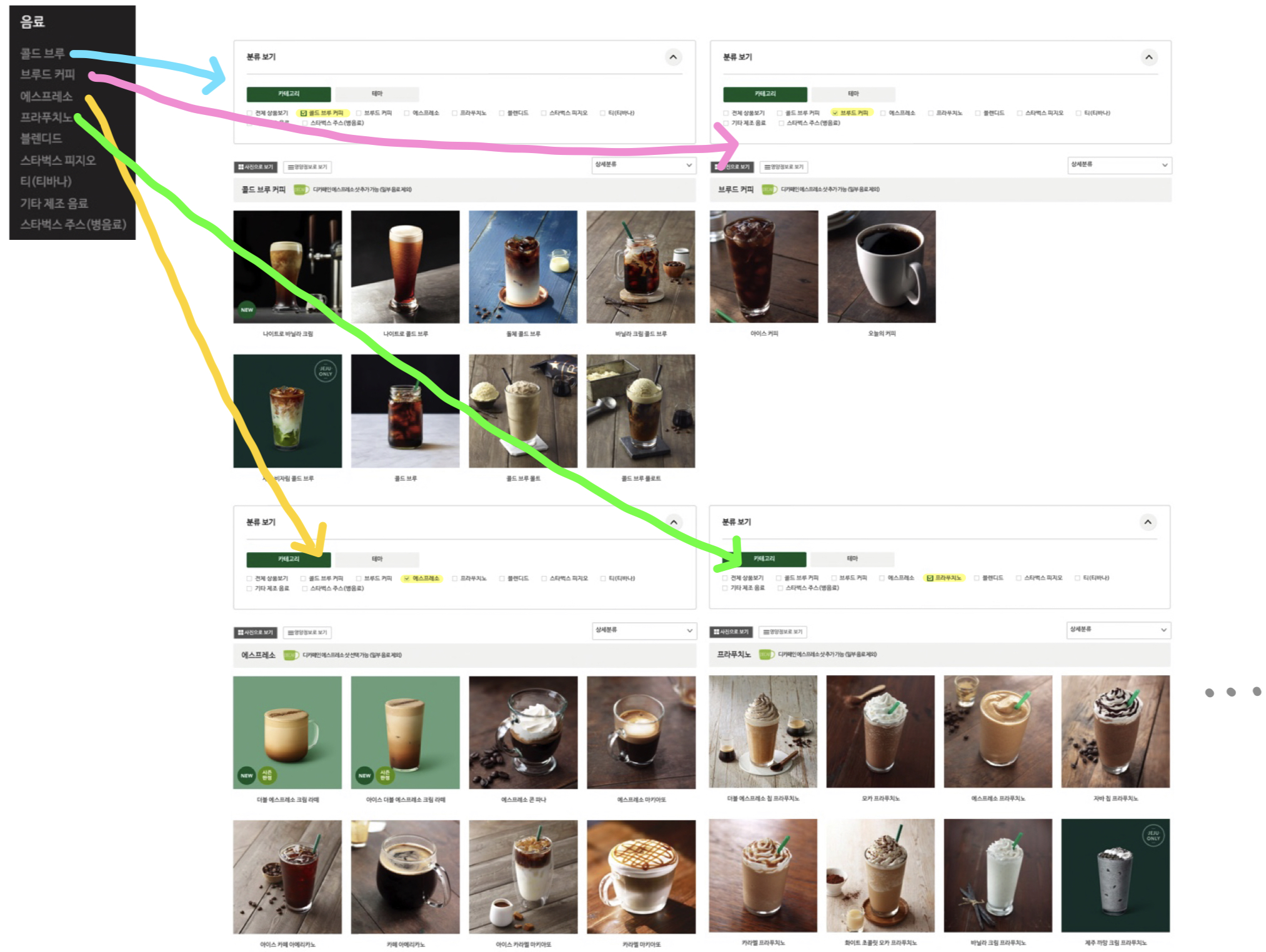
위에서 살펴본 카테고리 들에게는 각각 다양한 음료들이 있다.
| ID | MENU | CATEGORY | Beverages |
|---|---|---|---|
| 1 | 음료 | 콜드 브루 | 나이트로 바닐라 크림 |
| 2 | 음료 | 콜드 브루 | 나이트로 콜드 브루 |
| 3 | 음료 | 콜드 브루 | 돌체 콜드 브루 |
| ... | ... | ... | ... |
| 9 | 음료 | 브루드 커피 | 아이스 커피 |
| 10 | 음료 | 브루드 커피 | 오늘의 커피 |
| ... | ... | ... | ... |
| 44 | 음료 | 프라푸치노 | 더블 에스프레소 칩 프라푸치노 |
| 45 | 음료 | 프라푸치노 | 모카 프라푸치노 |
| 46 | 음료 | 프라푸치노 | 에스프레소 프라푸치노 |
| ... | ... | ... | ... |
🤚🏻 음료 까지 표에 넣어보니, 카테고리도 계속 중복(=반복) 되고 있다.
👏🏻 이부분도 나중에 정규화를 시켜줘야겠다!
1-4. 영양 정보
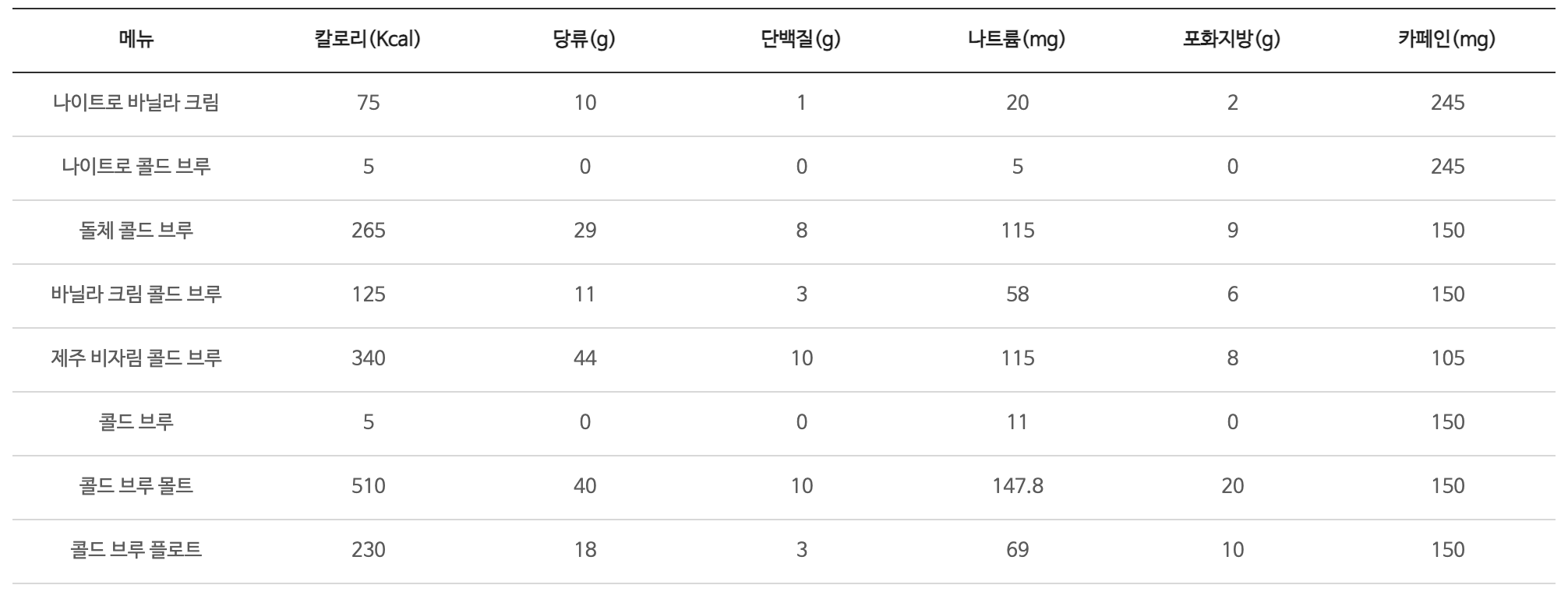
모든 음료에게는 영양정보들이 있는데, 각각의 음료들은 칼로리 ~ 카페인 까지의 영양 종류들을 가지고 있으며 그에 대한 숫자값들은 서로 거의 겹칠 것 같지 않아보인다.
1-5. 알레르기 유발요인
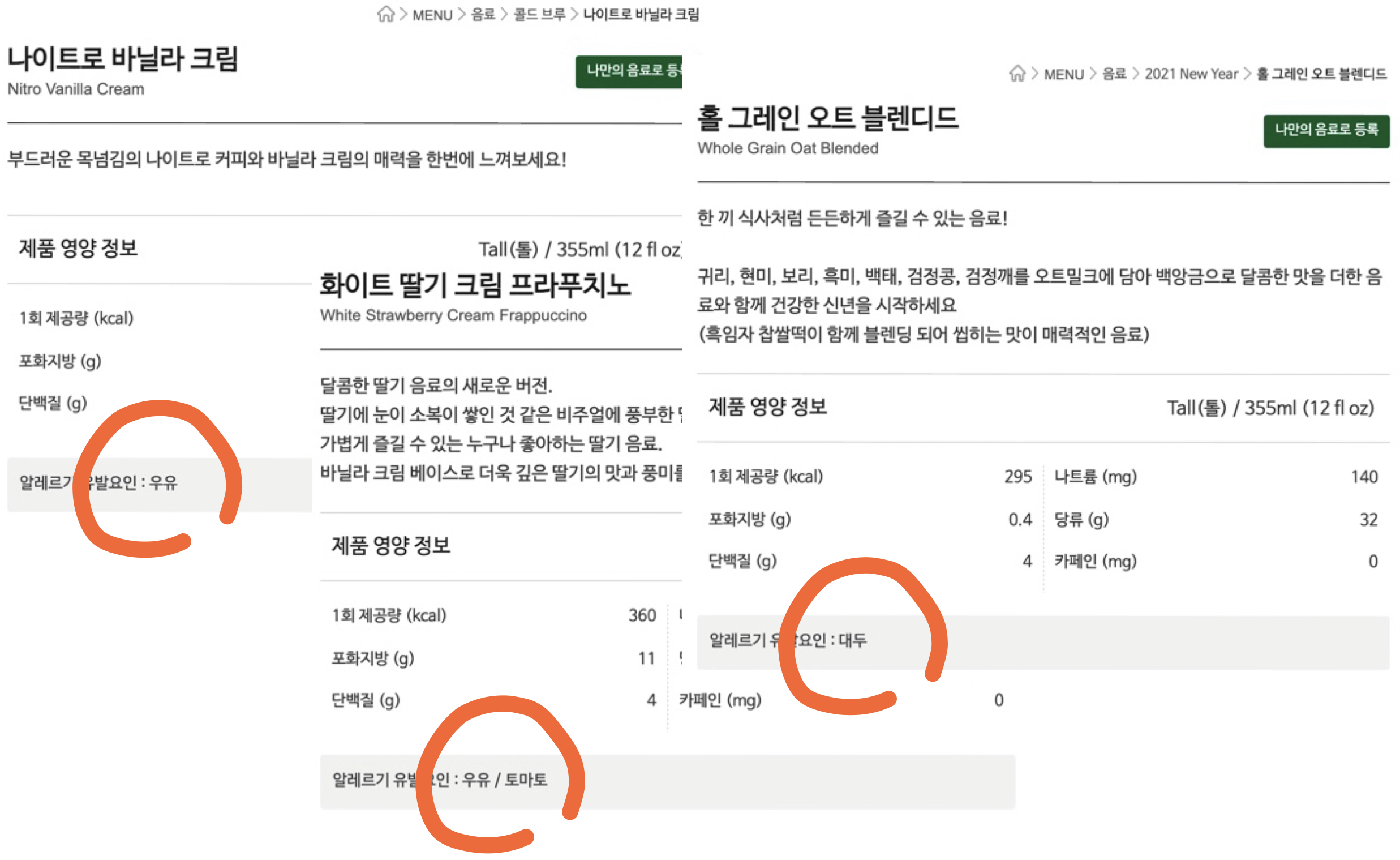
이번에는 알레르기에대한 정보들이다.
- 어떤 음료는 알러지성분이 하나도 없기도 하고,
- 어떤 음료는 알러지 유발요인을 하나를 가지고 있기도,
- 또 어떤 음료는 두가지의 알레르기 유발요인을 가지고 있는 것도 있다.
✨ 위에 있는 사진속 알레르기 정보들만 간단하게 표로 나타내보면,
| ID | MENU | CATEGORY | Beverages | Allergies |
|---|---|---|---|---|
| 1 | 음료 | 콜드 브루 | 나이트로 바닐라 크림 | 우유 |
| ... | ... | ... | ... | ... |
| 4 | 음료 | 프라푸치노 | 화이트 딸기 크림 프라푸치노 | 우유 / 토마토 |
| ... | ... | ... | ... | ... |
| 7 | 음료 | 블렌디드 | 홀 그레인 오트 블렌디드 | 대두 |
| ... | ... | ... | ... | ... |
🤚🏻 우유가 중복 되고 있다. 알레르기를 유발하는 모든 음료들을 채워넣는다면 다른 요인들도 더 중복되는것이 나올 수 있겠다.
👏🏻 그렇기 때문에 이것도 나중에 정규화를 시켜줘야겠다!
1-6. 음료이미지
음료들마다 대표하는 사진이 있다. 사진은 URL 값으로 가지고 있을거라 가정한다. 그리고 전부는 들어가보지 못했지만 여러개를 확인해봤을때 전부 사진이 한장씩 밖에 없었기때문에 이번 모델링 작업에서는 음료이미지는 한장씩 있는걸로 생각하고 진행해보겠다! 🙂
👏🏻 각각의 음료들은 자신만의 사진을 가지고 있을 것이기때문에 겹치는 사진은 없다.
1-7. 음료설명
👏🏻 각각의 음료 설명도 마찬가지로 자신에게만 해당하는 설명글이기 때문에 겹치는 음료설명은 없다.
1-8. 신상 여부

신상여부를 확인해봤을 때 ! 각각의 음료마다 신상에 해당하는 음료들에게만 NEW 스티커가 붙어있다.
→ 그러면! 신상인지 아닌지 true, false 의 방식으로 여부를 체크해 줄 수 있을것같다. 👏🏻
2. 테이블 연결 (정규화)
테이블끼리 연결하는 종류에는 크게 3가지가 있다.
- one to one
- one to many
- many to many
1번. 구현사항 부분에서 나열했던 데이터테이블에 대해 서로 연결시킬 관계들을 생각해보자!
2-1. one to one
-
음료이름 - 영양정보 : 각각의 음료들과 영양정보의 관계는 1:1로 생각했다. 왜냐하면 한 음료에겐 각각의 수치에 해당하는
칼로리, 당류, 단백질, 나트륨, 포화지방, 카페인 (총 6종류)값들이 한세트씩 연결되어있기 때문이다.
반대로 영양정보의 6가지 조합 세트들도 해당하는 음료에게만 적용되는 데이터이기 때문에 이 둘의 관계는 서로 one to one 인 것이다. -
음료이름 - 음료이미지 : 하나의 음료는 하나의 이미지만 가지고 있으며, 그 이미지 또한 하나의 음료에 대한 이미지인 것이기 때문에 서로 one to one인 관계이다.
-
음료이름 - 음료설명 : 마찬가지로 하나의 음료는 하나의 설명을 포함하고 있으며, 그 음료의 설명도 다른 음료에는 맞지 않고 해당하는 음료로만 향하는 설명이기 때문에 이 관계도 one to one이다.
2-2. one to many
-
메뉴 - 카테고리 : 하나의 메뉴, 그 중에서도 지금 살펴보고있는
음료메뉴와!콜드 브루 / 부르드 / 에스프레소 .. 등등각각의 카테고리들과의 관계는 one to many로 볼 수 있다. 왜냐하면 음료라는 메뉴는 여러 카테고리들을 포함하고 있지만,하나의 카테고리는 음료만을 향하고 있기 때문에
따라서 메뉴(one), 카테고리(many) 이므로 one to many 관계가 된다. -
카테고리 - 음료이름 : 하나의 카테고리에는 여러가지의 음료이름들이 포함되어 있지만, 반대로 하나의 음료는 하나의 카테고리로만 연결된다. 그렇기 때문에 카테고리가 one이되고, 음료이름이 many인 one to many 관계가 된다.
- 신상여부 - 음료이름 : 신상이다 아니다에서 신상이다는 여러 신상인 음료들을 포함하고 있지만, 각각의 음료들은 신상이나, 신상이 아닌것에 각각 하나씩만 향하고 있기 때문에
신상이 one, 신상인 음료들이 many인 one to many의 관계를 갖는다.
→ 1대 다의 관계에서는 Many 쪽이 외래키(FK)를 갖는다.
2-3. many to many
- 음료이름 - 알레르기 : 하나의 음료가 여러가지의 알레르기 유발 요인들을 포함하기도 하고, 반대로 하나의 알레르기 유발성분도 여러 음료에 알레르기 유발 영향을 끼치기도 하므로 서로 many인 관계인 many to many 관계가 된다.
3. ERD 그리기
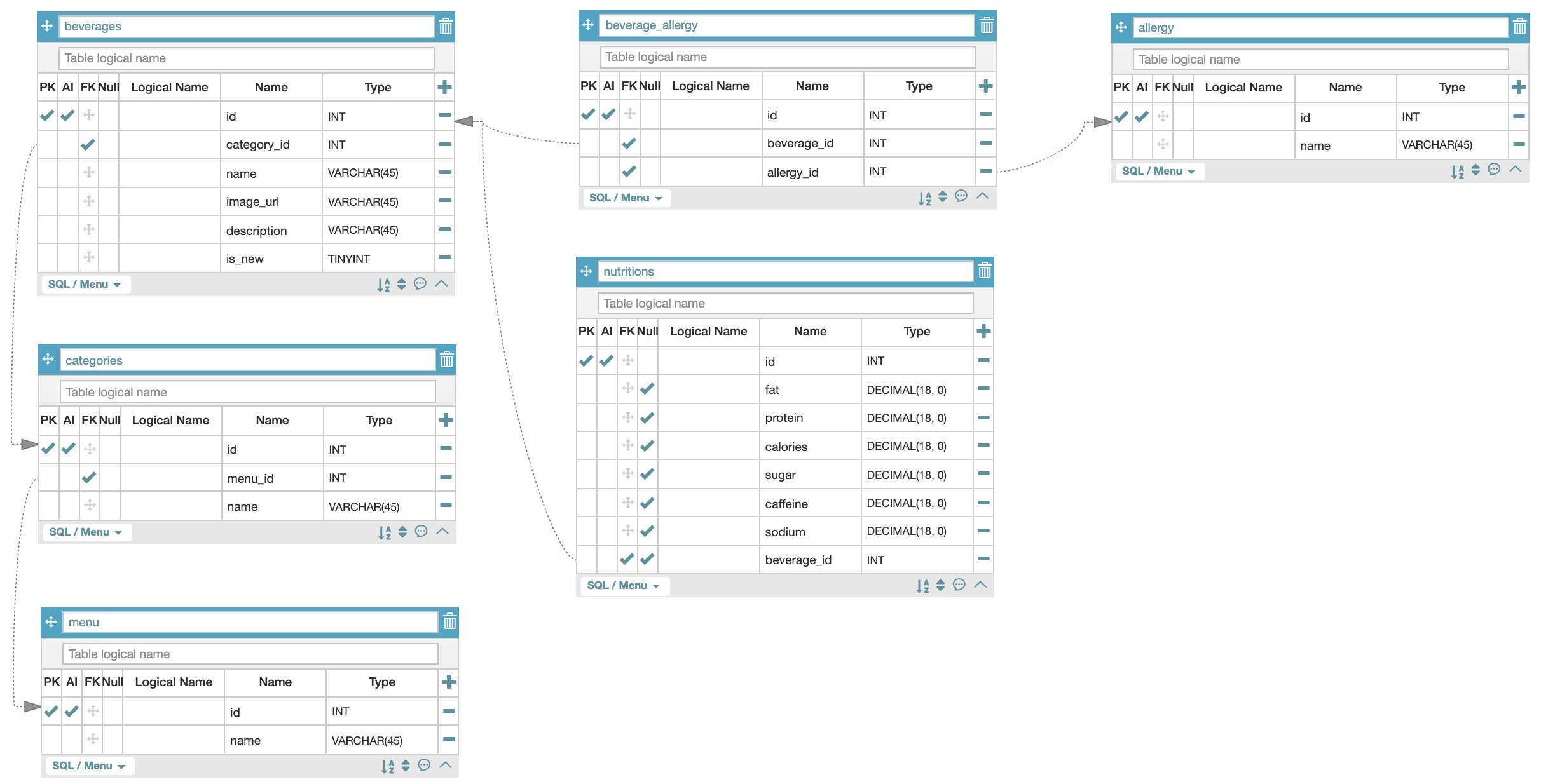
- 음료 설명과, 음료 이미지는 one to one이기 때문에 그냥 beverage table에 넣었다.
- 음료 신상여부는 1 / 0으로 표현할 수 있는 TINYINT 형식으로 이거도 beverage table에 넣었다.
- 음료이름(beverages)과 영양성분(nutritions)도 one to one 이지만, 영양성분 column name이 많아서 테이블을 분리시켜준 후 음료이름의 테이블의 PK를 받아와 영양성분 테이블에 FK로 두었다.
- one to many 관계였던 메뉴와 카테고리는 many인 카테고리테이블쪽에 FK를 두었다.
- 또 다른 one to many 관계인 카테고리(categories)와 음료이름(beveragies)의 테이블도 many인 음료이름쪽 테이블에 FK를 두어 연결시켰다.
- 마지막으로 many to many인 음료이름(beveragies)와 알레르기 유발요인(allergy)은 beverage_allegy 라는 중간테이블을 두어 서로를 연결시켜줬다.
