
01-1 인공지능, 머신러닝, 딥러닝
AI, AI하는데 그게 뭐야?
AI는 두 번의 붐이 있어 왔고 2016년 알파고의 등장으로 지금 점점 주가가 올라가는 몸이다.
AI는 artificial intelligence로 사람 같이 생각하는 지능을 가진 프로그램이다.
인공일반지능 artificial general intelligence는 strong AI라고도 불리며 사람과 거의 유사한 지능을 가진 인공지능을 말한다.
그와 반대로 약인공지능 weak AI는 우리 주변에서 볼 수 있는 노래추천, 자율주행기능, 기계번역과 같이 우리의 보조 비서 역할을 해주는 인공지능이라고 생각하면 된다.
머신러닝이란?
AI의 하위분야로 일일이 프로그래밍을 하지 않아도 데이터 속에서 규칙을 찾아 학습하는 알고리즘을 연구하는 분야이다.
머신러닝은 사이킷-런이라는 파이썬의 라이브러리를 통해 사용할 수 있다. 이 오픈소스 라이브러리는 유수의 석학들이 연구한 알고리즘 중 쓸만한 것들을 모아 사용하기 쉽게 모아둔 라이브러리이다.
사이킷-런의 의미는 이 라이브러리가 나오고부터 누구나 파이썬만 조금 안다면 머신러닝을 시작할 수 있게 만들었다는 데서 온다.
그렇기에 우리는 새로운 이론이나 기술을 "코드로 구현"하지 못하면 그것을 가치가 없다고 평가하게 되었다.
딥러닝이란?
머신러닝 알고리즘들 중에 인공 신경망 Artificial neural network을 활용한 방법들의 통칭이다. 딥러닝이 곧 인공 신경망이라고 보면 된다.
인공 신경망이 뭔지는 모르겠지만 이미지 처리 기술에 합성곱 신경망을 사용하는 게 대세이다.
앞에서 머신러닝 라이브러리 사이킷-런을 소개했듯 딥러닝에서도 양대산맥 라이브러리가 존재한다.
바로 구글의 tensorflow, 페이스북의 pytorch이다.
01-2 주피터 노트북
우리는 구글 코랩을 이용해 실습을 한다. 이것은 클라우드 기반이라 컴퓨터 성능과는 무관하다.
코랩은 클라우드 기반의 주피터 노트북 개발 환경이다.
주피터 노트북이란?
주피터 프로젝트의 대표 제품으로 이 프로젝트는 구글이 대화식 프로그래밍 환경인 주피터를 만드는 프로젝트이다. 이 프로젝트는 파이썬부터 시작해서 최근에는 다른 언어까지 지원하게 되었다.
말이 좀 와닿지는 않지만 아무튼 파이썬 실행 사이트(?) 정도로 나는 이해했다.
코랩 : 웹 브라우저 기반의 파이썬 코드 실행 환경
노트북 : 코랩의 프로그램 작성 단위이며 대화식이라 데이터 분석에 편함
01-3 마켓과 머신러닝
생선이 도미이냐 빙어이냐 구분하는 머신러닝 모델을 만들어보자.
<용어 설명>
생선의 종류할 때 종류는 머신러닝에서 class라고 부르고 분류하는 것은 classfication라고 한다. 특히 이번 예제처럼 2개 중 하나의 것을 고르는 분류는 이진 분류 binary classfication이라고 한다.
특성은 featrue이라고 하며 생선의 길이, 무게 같은 데이터의 특징이라고 생각하면 된다.
용어 정리는 이쯤하고 차차 부족한 건 추가하겠다.
K-Nearest Neighbors (K-최근접 이웃 알고리즘)
이번 머신러닝 모델을 만들 때 필요한 알고리즘.
알고리즘이라고 할 것도 없는게 모델이 from sklearn.neighbors import KNeighborsClassifier에서 KNeighborsClassifier()이라고 치면,
모델의 fit() 메소드 안에 값 데이터랑 정답 데이터만 넣으면 주변 5개의 이웃을 보고 더 많은 쪽의 (도미, 빙어) 종류를 정답으로 내어놓는 알고리즘이다. 단순 연산인 셈.
그리고 이웃 갯수는 5개가 default이며 k_neighbors = 49와 같이 변경도 가능. 이 경우 잘못하면 정확도가 훅 떨어진다. 이유는 후술.
참고.
이 알고리즘을 사용할 때는 scatter plot를 활용하여 시각적으로 확인하는 작업을 많이 한다. 그 코드는 머리 속에 익히자.
import matplotlib.pyplot as plt
plt.scatter(x,y)
plt.xlabel = xname
plt.ylabel = yname
plt.show()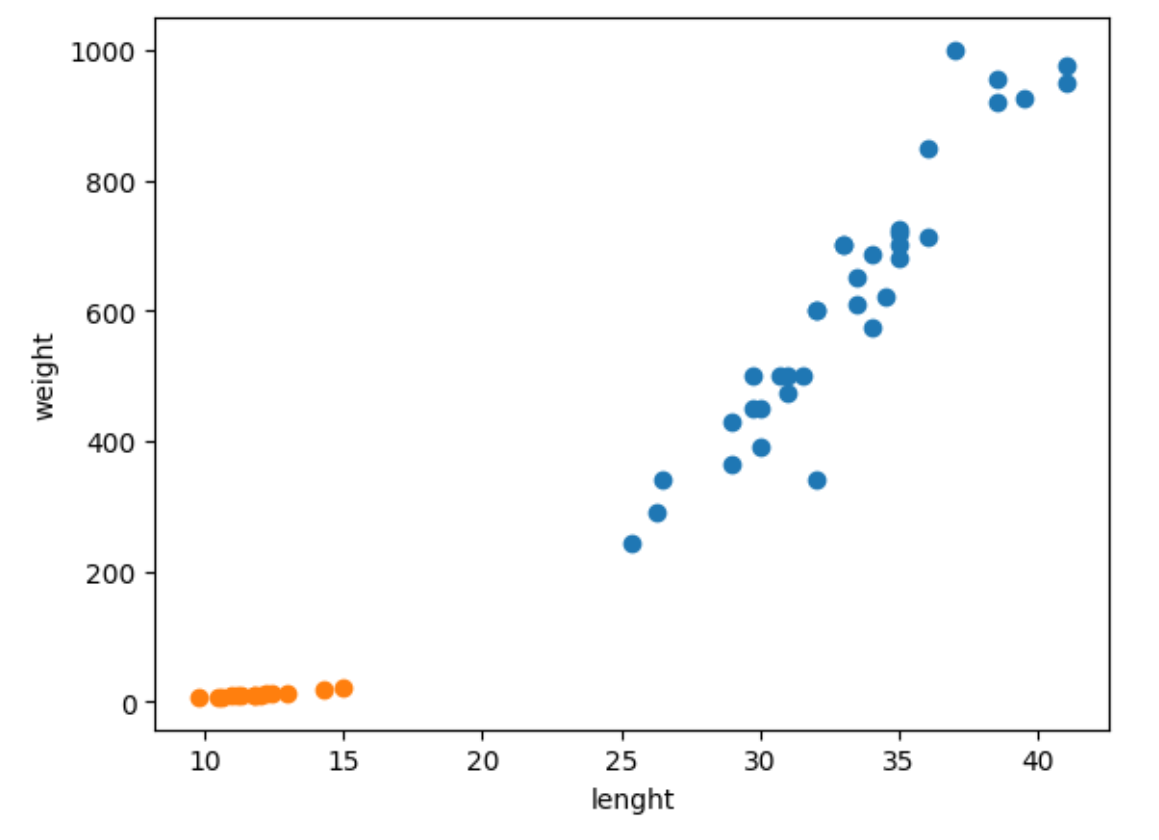
KNeighborsClassifier() 모델의 메소드
-
kn.fit(fish_data, fish_target)이때 fish_data는 이중 리스트이며 [길이,무게] 이렇게 이루어진 데이터묶음이 나열되어있다.
값 데이터와 정답 데이터를 통해train시킬 수 있다. -
kn.score(fish_data, fish_target)
정확도 accuracy를 0에서 1사이 값으로 확인 가능하다. -
kn.predict([[30,600]])
30에 600을 가진 생선이 도미이냐를 물어보기 가능하다. array([1])의 값으로 도미임을 알려주는데 일단 1이냐만 보고 array는 무시하자. -
kn._fit_X
kn의 fish_data를 확인 가능 -
kn._Y
kn의 fish_target을 확인 가능 -
kn49 = KNeighborsClassifier(n_neighbors=49)
이웃의 수를 49로 변경하면 모든 답은 도미로 나온다. 그 이유는 원래 fish_data의 값에 35개가 도미이고 14개가 빙어라서 다수결의 법칙에 따라 늘 도미만 나오게 되는 것이 까닭이다.
