
OS_16_File Systems
1. File System Structure
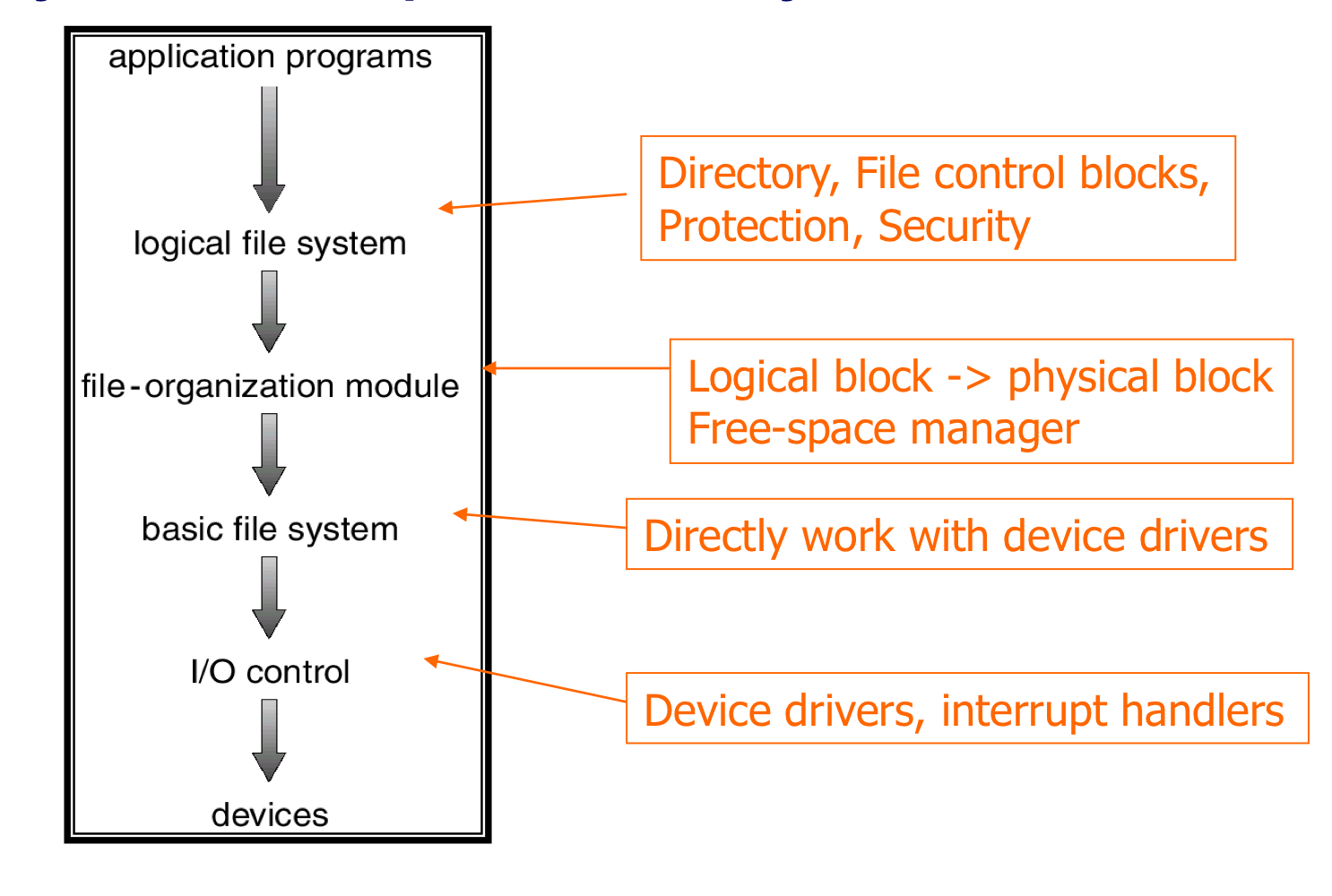
1) File-System Structure
- File system은 각기 다른 층계로 구성되어 있다.
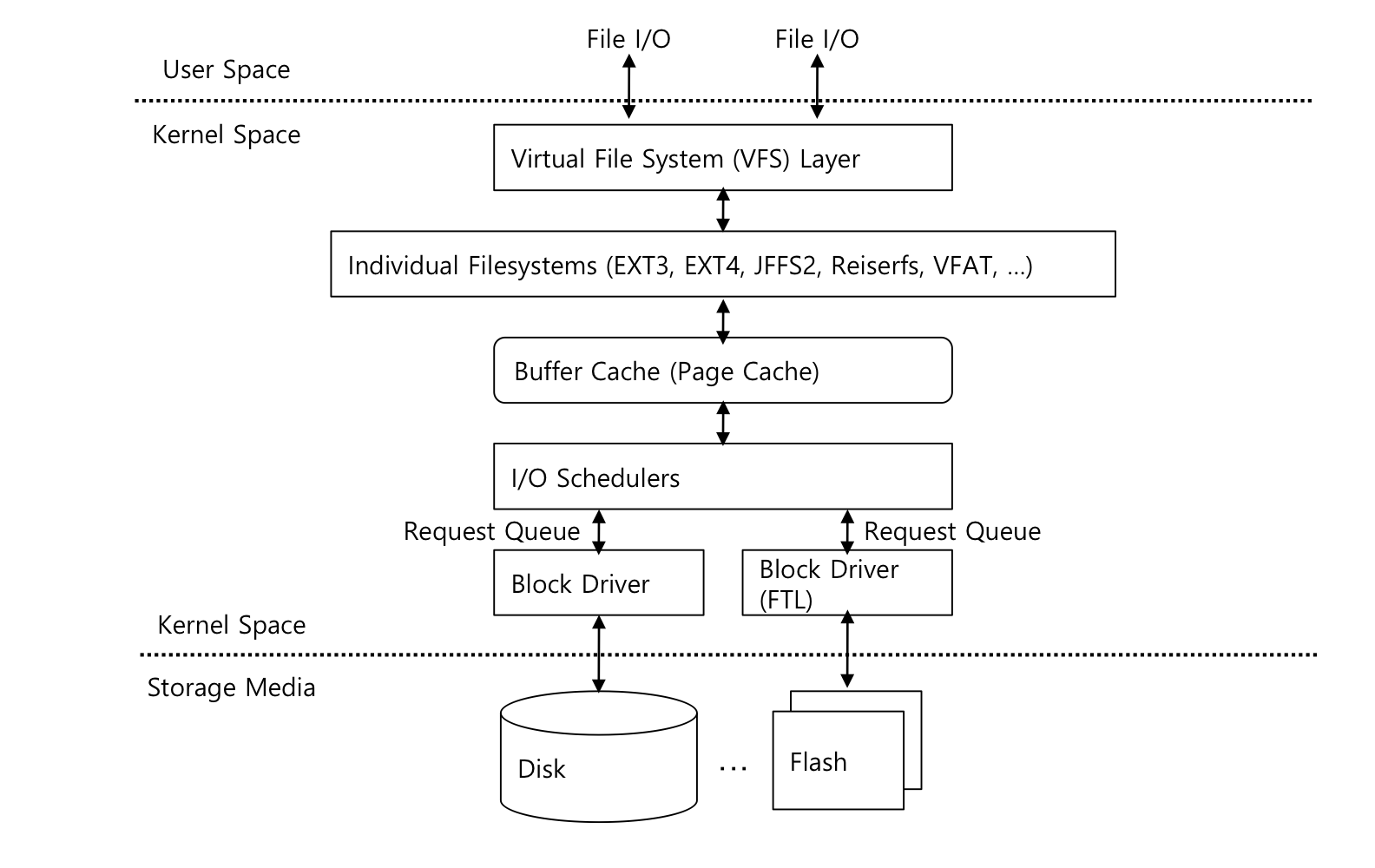
- Logical file system
- Manages metadata information
- Metadata는 실제 데이터를 제외한 모든 파일 정보를 포함한다.
- Manages directory structure via FCB (file control block)
- Manages metadata information
- File organization module
- logical block address를 physical block address로 변환한다.
- logical block은 0부터 N까지 번호가 할당되어 있다.
- Fress space manager는 할당되지 않은 block을 추적하고, 필요할 때 이 블록들을 file organization module에 제공한다.
- Basic File System
- device driver에게 일반적인 명령을 내린다.
- 각 physical block은 numeric disk address로 식별된다.
- Drive 1, cylinder 73, head 2, sector 10
- Two types of addressing
- CHS (cylinder-head-sector addressing)
- LBA (logical block addressing)
- Deivce drivers
- main memory와 disk 사이에 정보를 교환한다.
- 효율성을 위해서, I/O전송은 block 단위로 수행된다.
- Each block은 한 개 이상의 sectors
- Sectors는 32 bytes에서 4,096 bytes까지 다양하며, 대게 512 bytes이다.
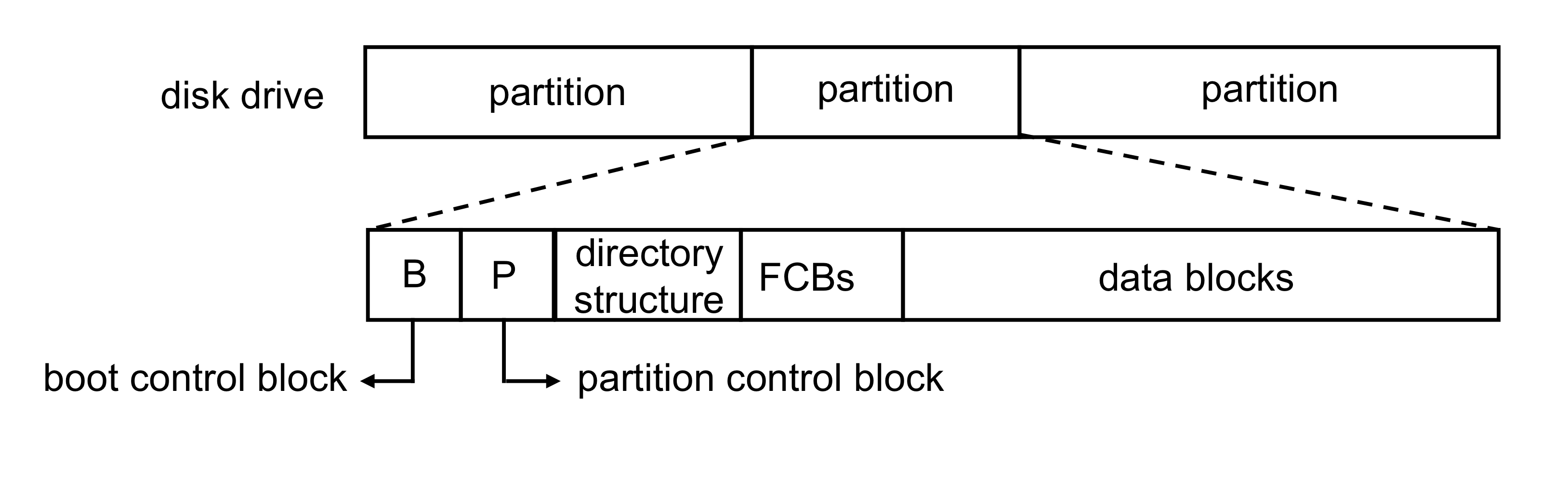
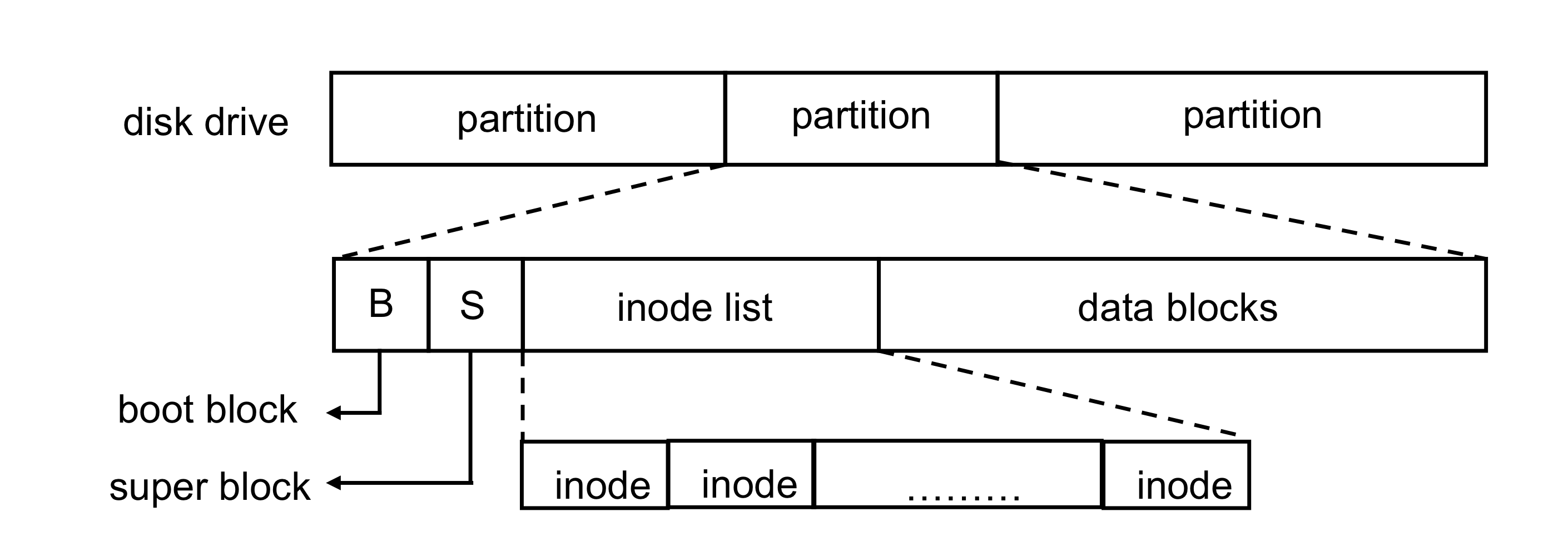
2) On-Disk Structure
- Boot control block
- system이 boot하기 위해 필요한 정보를 포함한다.
- Partition control block
- Number of blocks, size of blocks, free-block information, …
- Directory structure
- FCBs (File Control Blocks)
- Data blocks
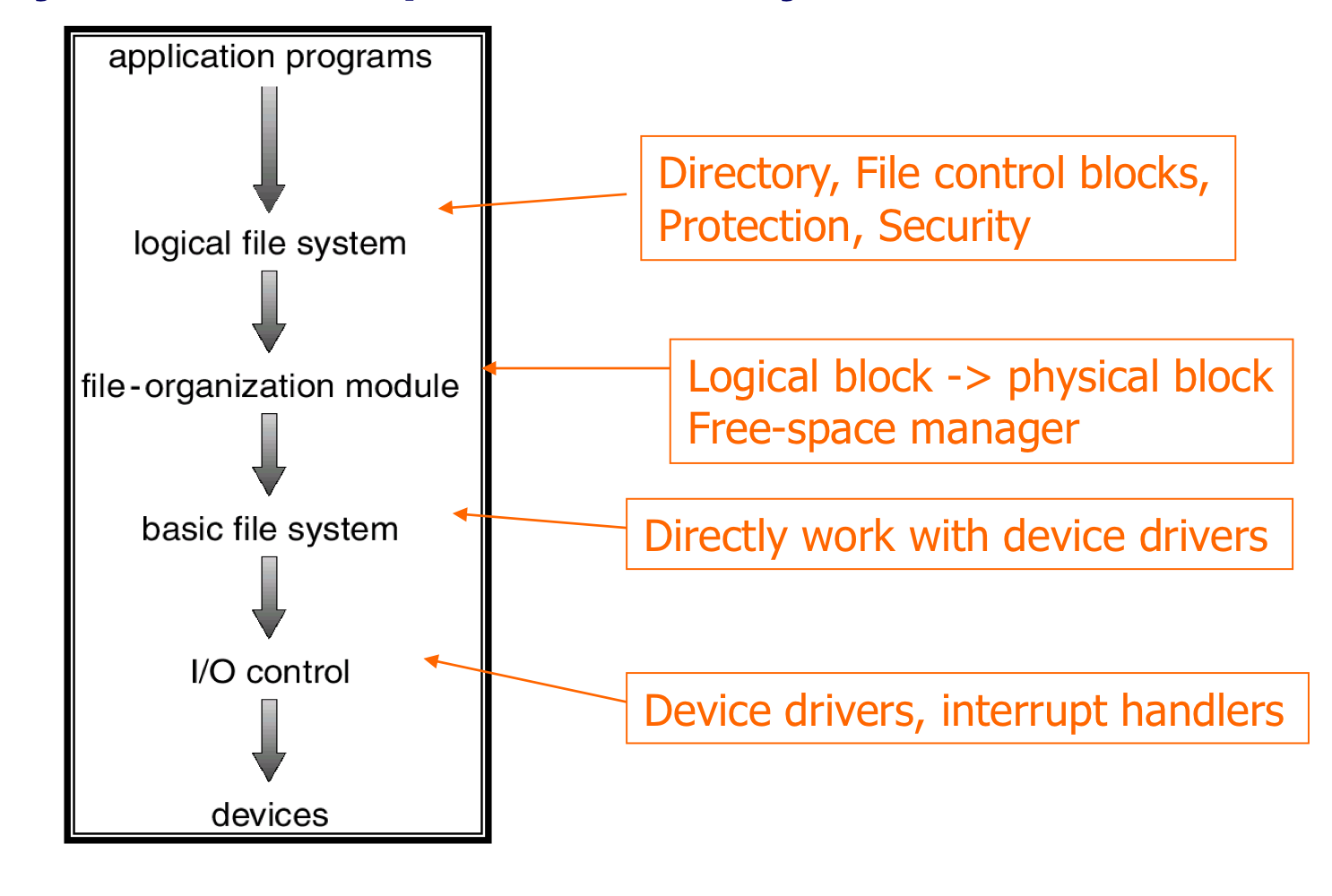
3) In-Memory Structure
- Partition table
- 각 mounted partition에 대한 정보
- Directory structure
- System-wide open-file table
- open file들의 FCB의 복사본을 포함한다.
- Per-process open-file table
- system-wide open-file table에 있는 적절한 항목에 대한 pointer를 포함한다.
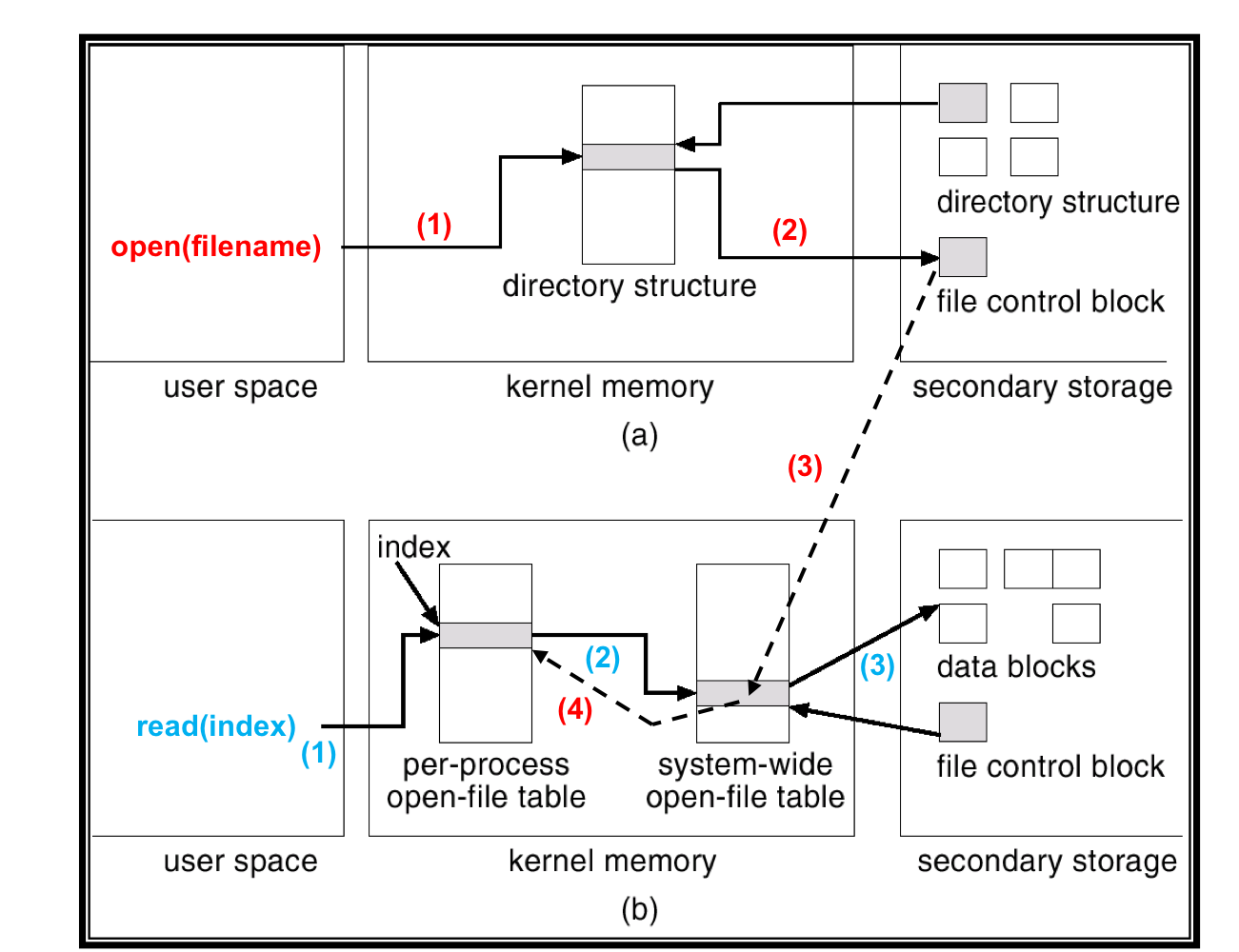
2. Allocation Methods
1) Data Block Allocation
- Allocation method는 파일에 대한 disk block이 어떻게 할당되는 지에 대한 것이다.
- 이는 디스크 공간을 어떻게 효율적으로 사용하고 파일에 어떻게 빠르게 접근할 수 있는지에 대한 주요한 문제.
- Thress major methods
- Contiguous allocation
- Linked allocation
- Indexed allocation
a) Contiguous Allocation
- 각 파일이 디스크의 연속된 블록 set을 차지하는 것이다.
- 장점
- Seek time이 짧다.
- Disk는 디스크에서 선형적인 순서를 정의한다.
- Block b가 접근된 후에 Block b+1에 접근한다.
- 따라서, Head movement는 each track이 바뀔 때만 필요하다.
- Simple
- 시작 위치의 (block #)와 lenth (number of blocks)만 필요하다.
- 순차적이고 random 접근
- Seek time이 짧다.
- 단점
- 새 파일에 대한 공간을 찾는 것이 어렵다. (external fragmentation)
- Compaction은 상당한 오버헤드다.
- File 크기를 늘릴 수 없다.
- 왜냐하면, 파일이 더 커질 공간이 없기 때문이다.
- 새 파일에 대한 공간을 찾는 것이 어렵다. (external fragmentation)
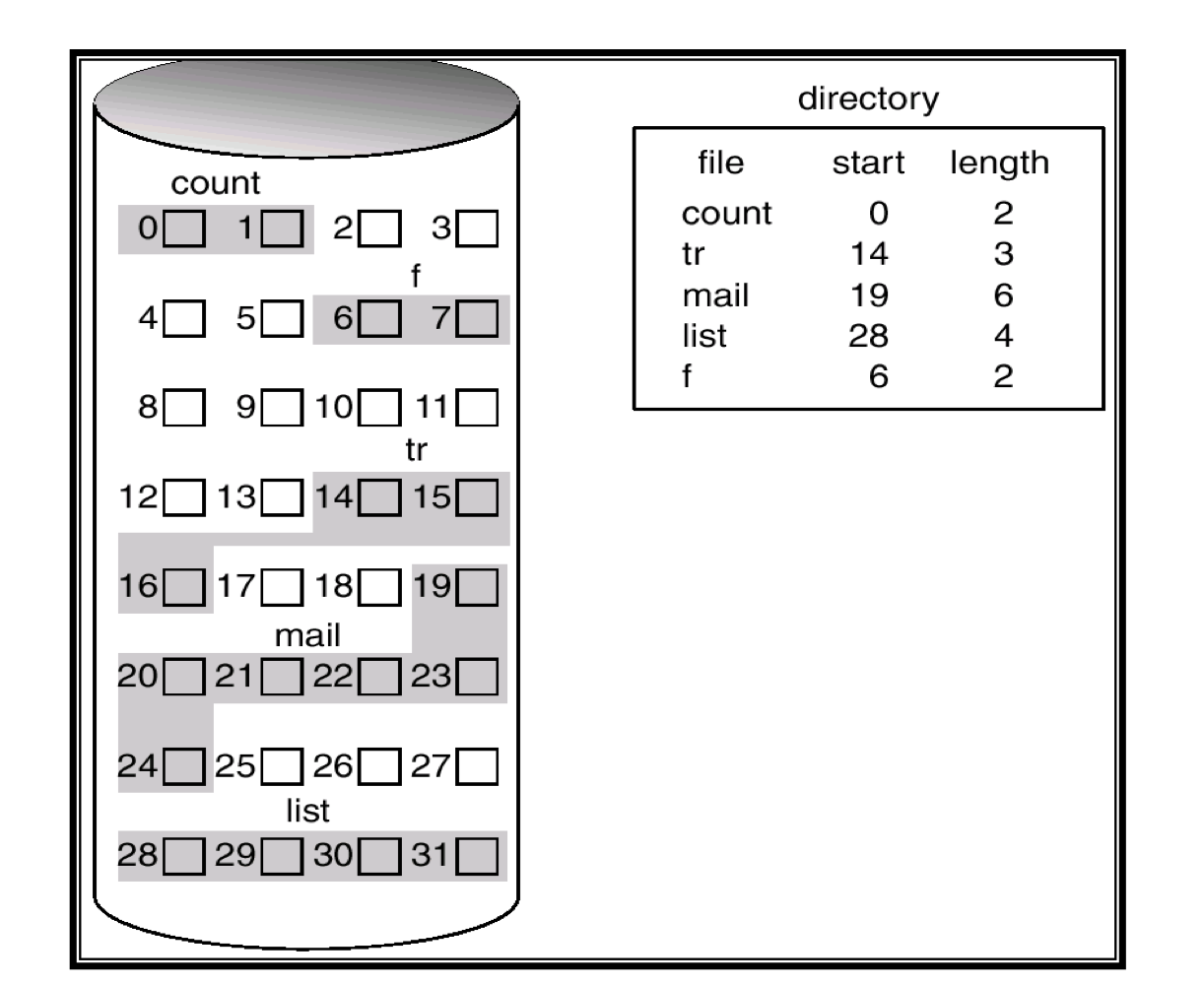
b) Linked Allocation
- Linked allocation은 contiguous allocation의 모든 문제를 해결한다.
- 각 파일은 disk block의 linked list : block은 disk의 어디든 흩어져 있다.
- directory는 file block의 처음과 마지막 block에 대한 pointer를 갖는다.
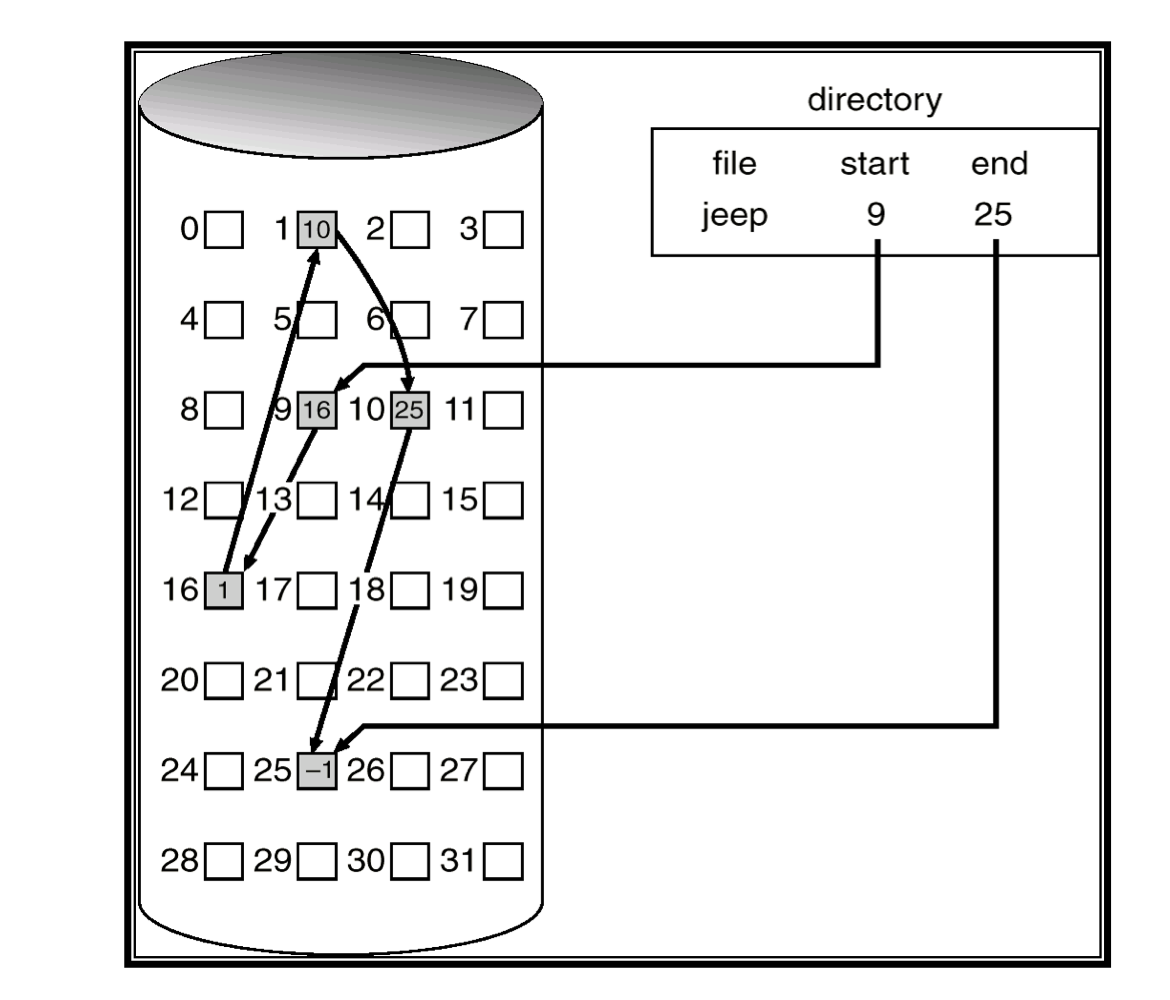
- 장점
- No external fragmentation
- file의 크기를 미리 선언할 필요가 없다.
- 사용 가능한 block이 있을 경우 file size가 계속해서 커질 수 있다.
- 단점
- Sequential access only
- ith block을 찾기 위해서는, 반드시 파일의 시작부터 시작해서 pointer를 따라가야 한다.
- Space is needed for pointers
- 4 bytes가 512-byte block에서 빠진다.
- Low reliability
- Pointers can be lost or damaged
- OS 버그나 HW failure로 잘못된 포인터를 선택할 수 있다.
- Sequential access only
c) File Allocation Table
- Linked allocation에 대한 중요한 변형이다.
- Late 1970 and early 1980
- Used by MS-DOS and OS
- FAT
- 각 partition의 시작 부분에 있는 disk의 section은 table을 담기 위해 할당된다.
- 이 table는 disk block마다 하나의 entry를 가지고 있으며, block number로 index화 되어 있다.
- Directory entry는 각 파일의 첫 번째 block number를 포함한다.
- Random access time이 FAT정보를 읽음으로써 향상된다.
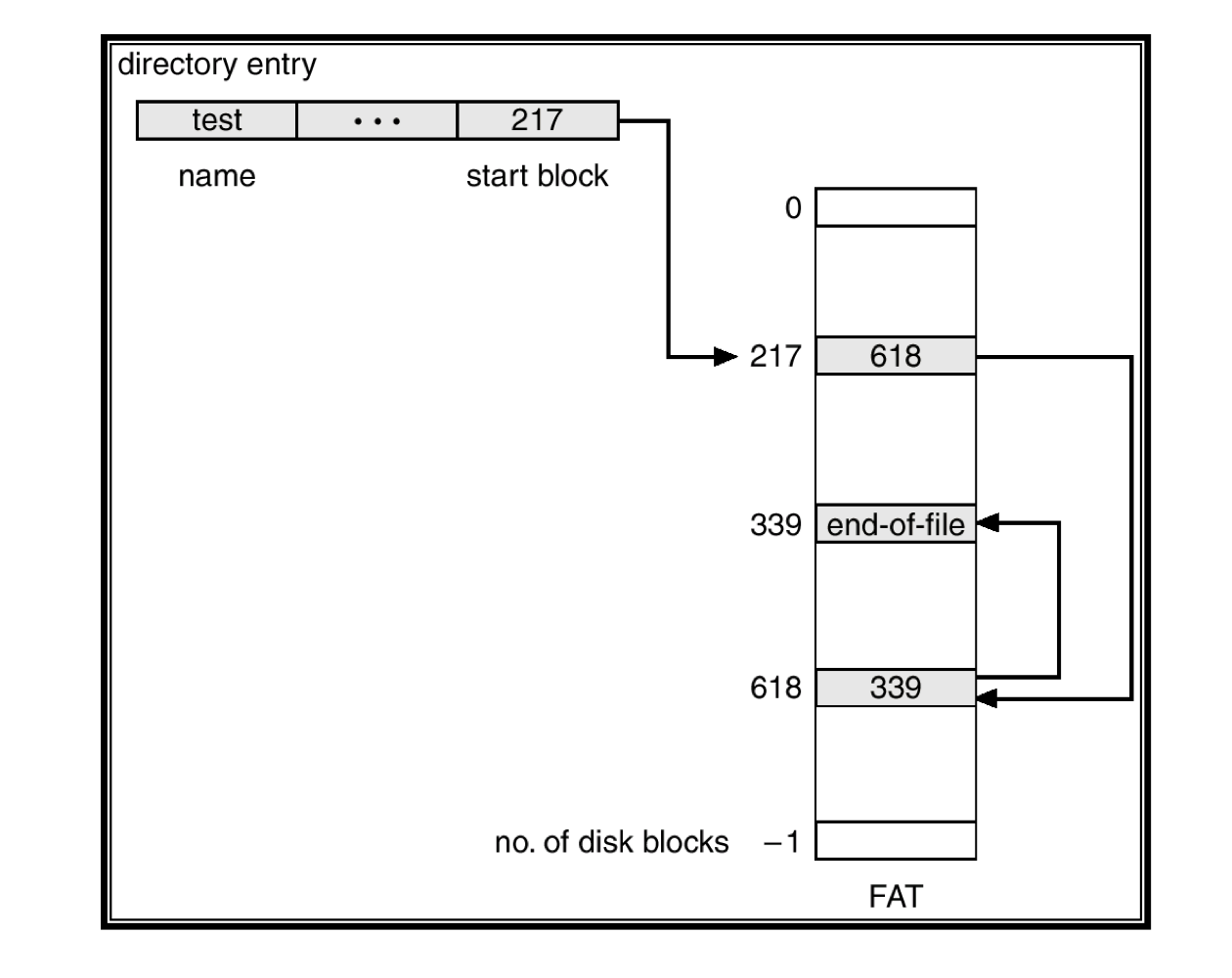
FAT
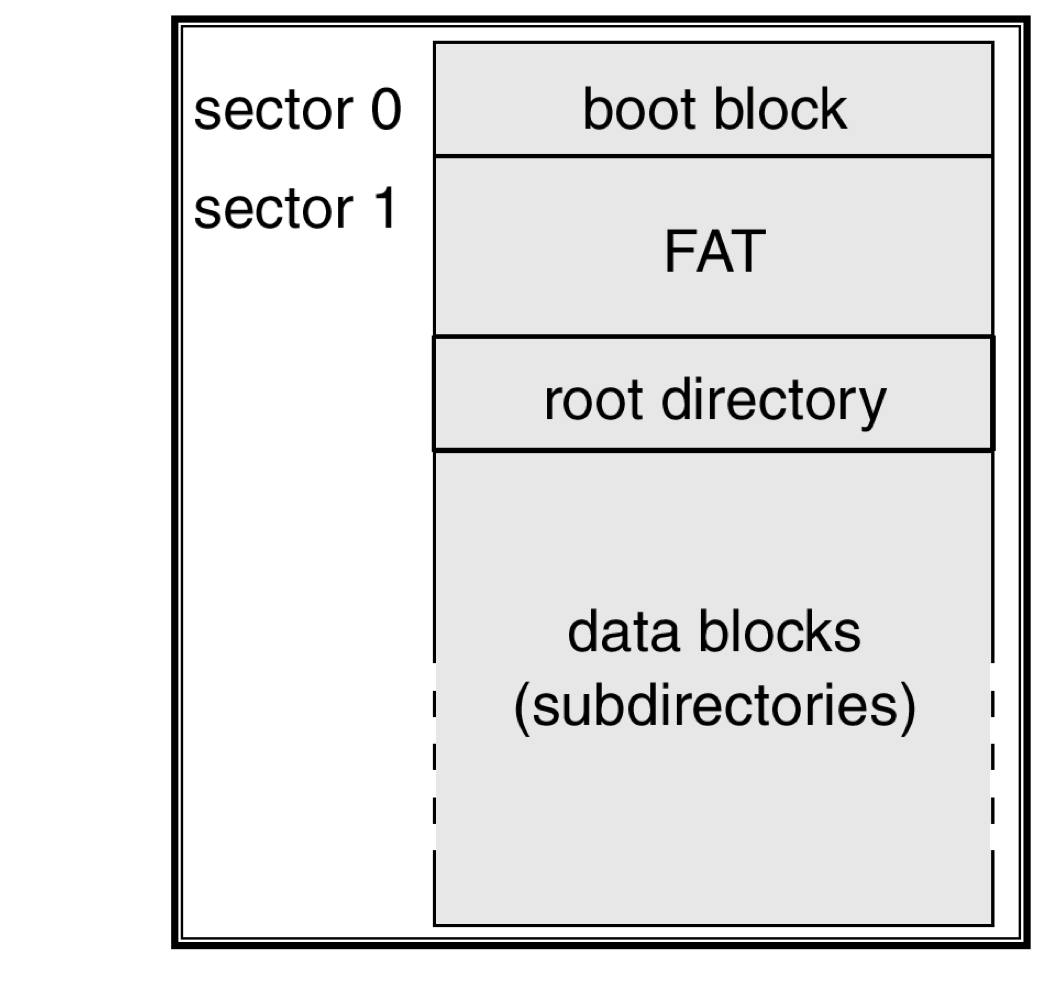
FAT Disk Layout
d) Indexed Allocation
- 모든 pointer들을 index block으로 가져온다.
- 각 파일은 각자의 index block을 가진다.
- ith entry in the index block은 파일의 ith block을 가르킨다.
- directory는 index block의 주소를 포함한다.
- When a file is created
- All pointers in the index block은 nil로 설정
- 파일의 ith block이 처음으로 쓰여질 때, 빈 블록이 할당되고 그 주소는 ith index block entry에 저장된다.
- Wasted space is large
- 하나 또는 두개의 포인터만 nil이 아니여도 전체 block을 할당해야 한다.
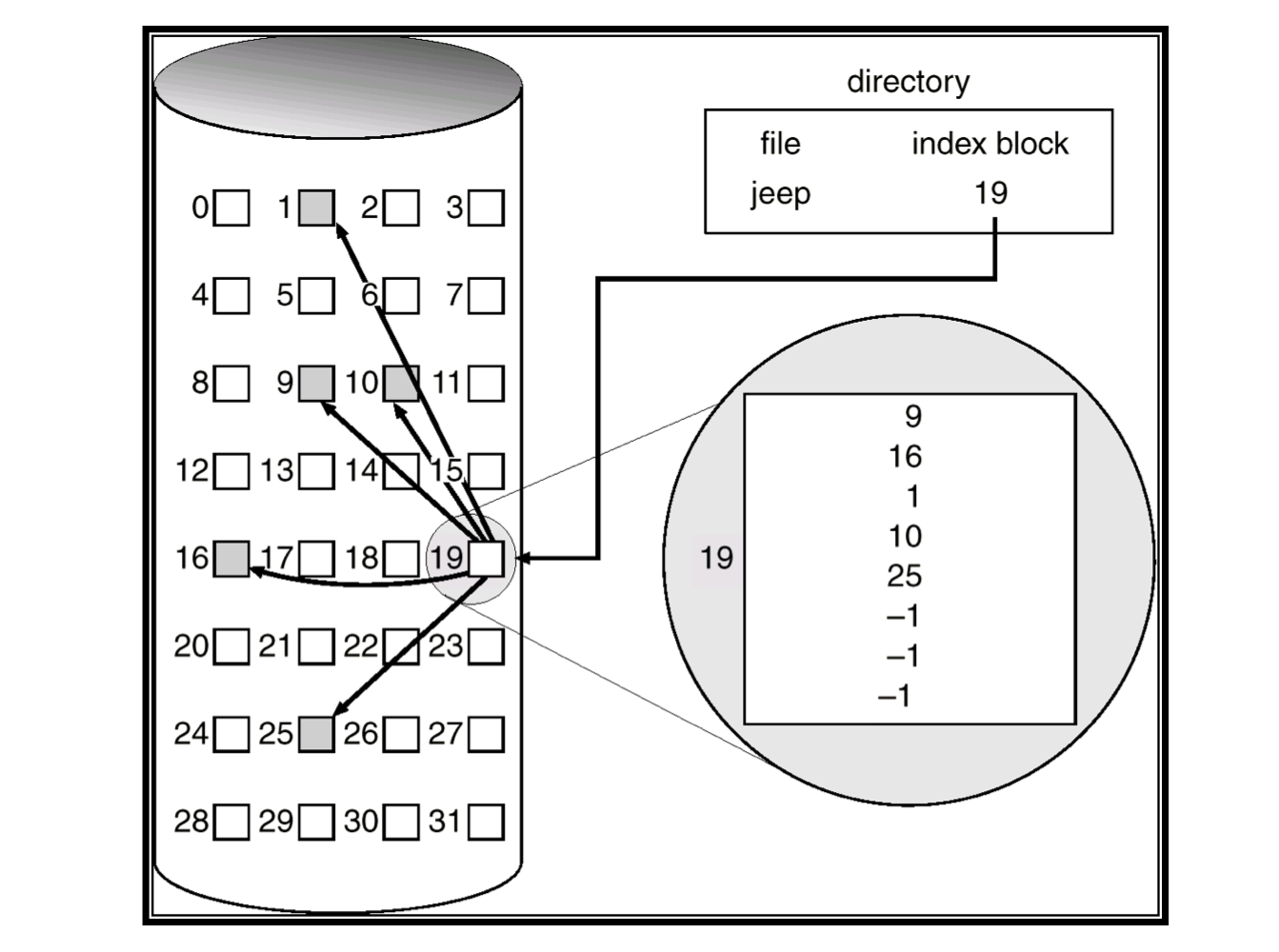
- index block이 얼마나 커야하는가?
- index block이 너무 작다면, 해당 mecahnism이 large file을 다룰 수 있다.
- Linked scheme
- 여러개의 index block을 link
- Small header가 file name을 준다.
- first disk-block addresses의 집합
- Last address는 nill (for a small file) or 다른 인덱스 block을 가리키는 pointer
- Multilevel index
- linked scheme의 변형
- first level index block은 second level index block set을 가리킨다.
- Combined scheme (UFS)
- 15 pointers of the index pointers
- 첫 12개 pointer는 direct block (data of the file)
- 다음 3개의 pointer는 Indirect block
- Single indirect block: an index block
- Double indirect block and triple indirect block
- Linked scheme
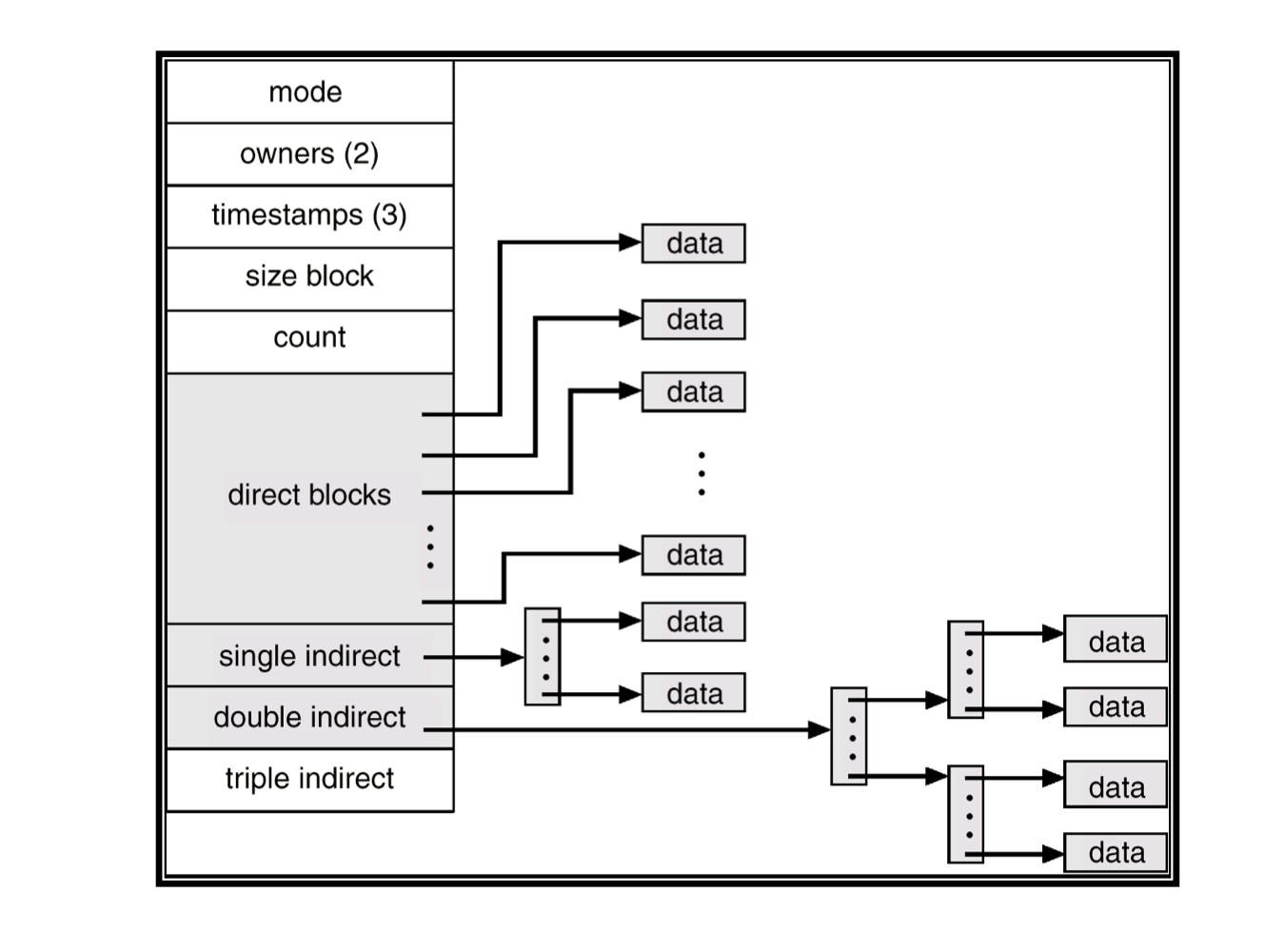
UFS (4K bytes per block)
2) On-Disk Structure in UNIX
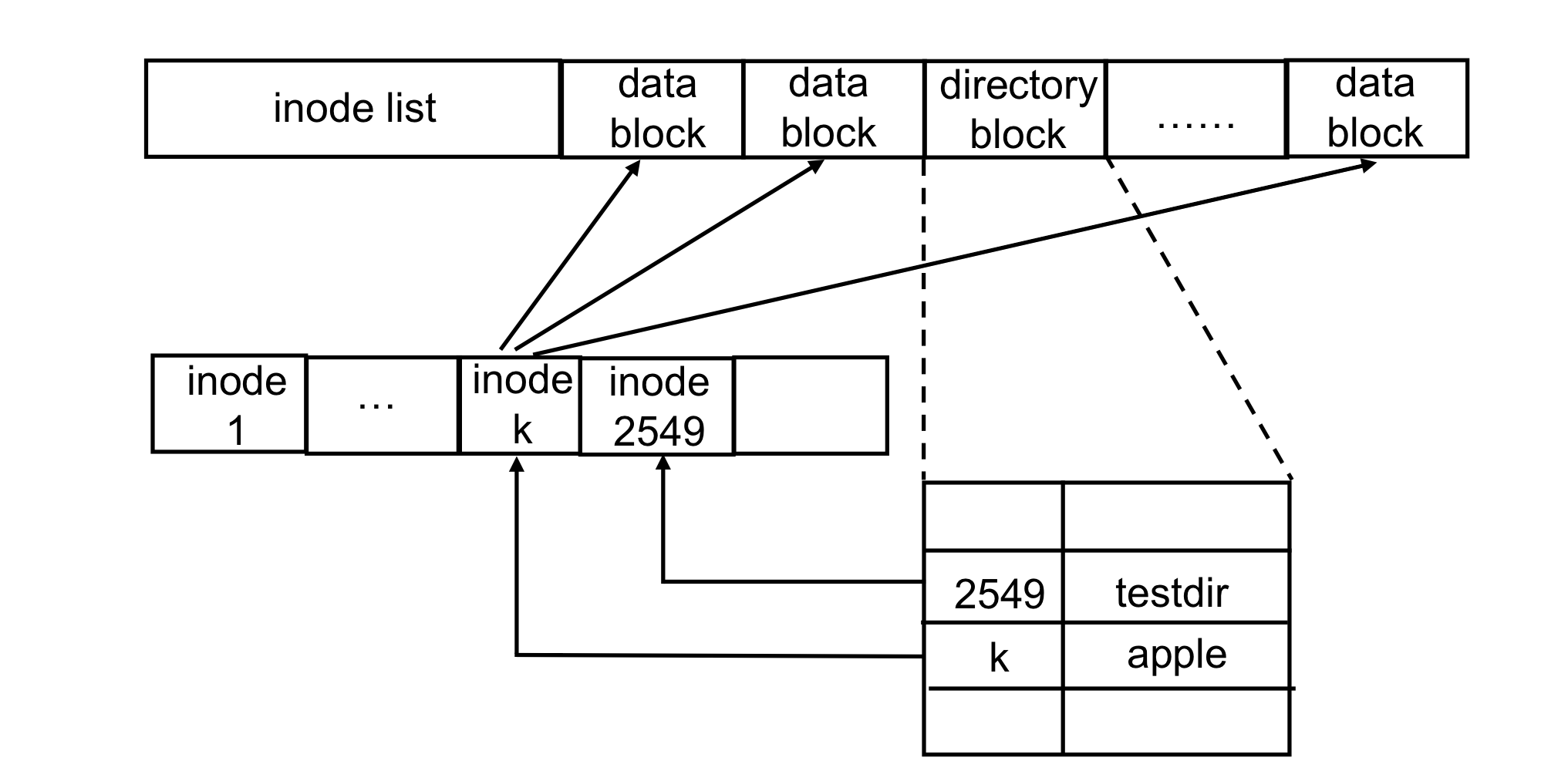
- Boot block: bootstrap(load and initialize)에 필요한 code가 포함되어 있다. (it may be empty)
- Super block: file system 자체의 metablock과 attributes를 저장
- Inode list: Linear array of inodes
- inode list size는 file system이 생성 될 때 설정된다.
- partition에서 포함할 수 있는 최대 파일 개수를 제한한다.
3) Mapping between FIle and Data Blocks
- Directory는 file과 subdirectory를 포함하는 특별한 file이다.
- 각 16 bytes의 고정 사이즈를 포함한다.
- 2 bytes contains inode, 14 bytes contains the file name
- Linux에서 root directory는 inode 2(inode 1 is used to keep track of bad blocks)
4) Free-Space Management
- free disk space를 추적하기 위해서, system은 free space list를 유지해야 한다.
- Implementation techniques of free space list
- Bit vector
- Counting
- Grouping
- Linked list
a) Bit Vector
- Bit vector (n blocks) → datablock의 개수 만큼
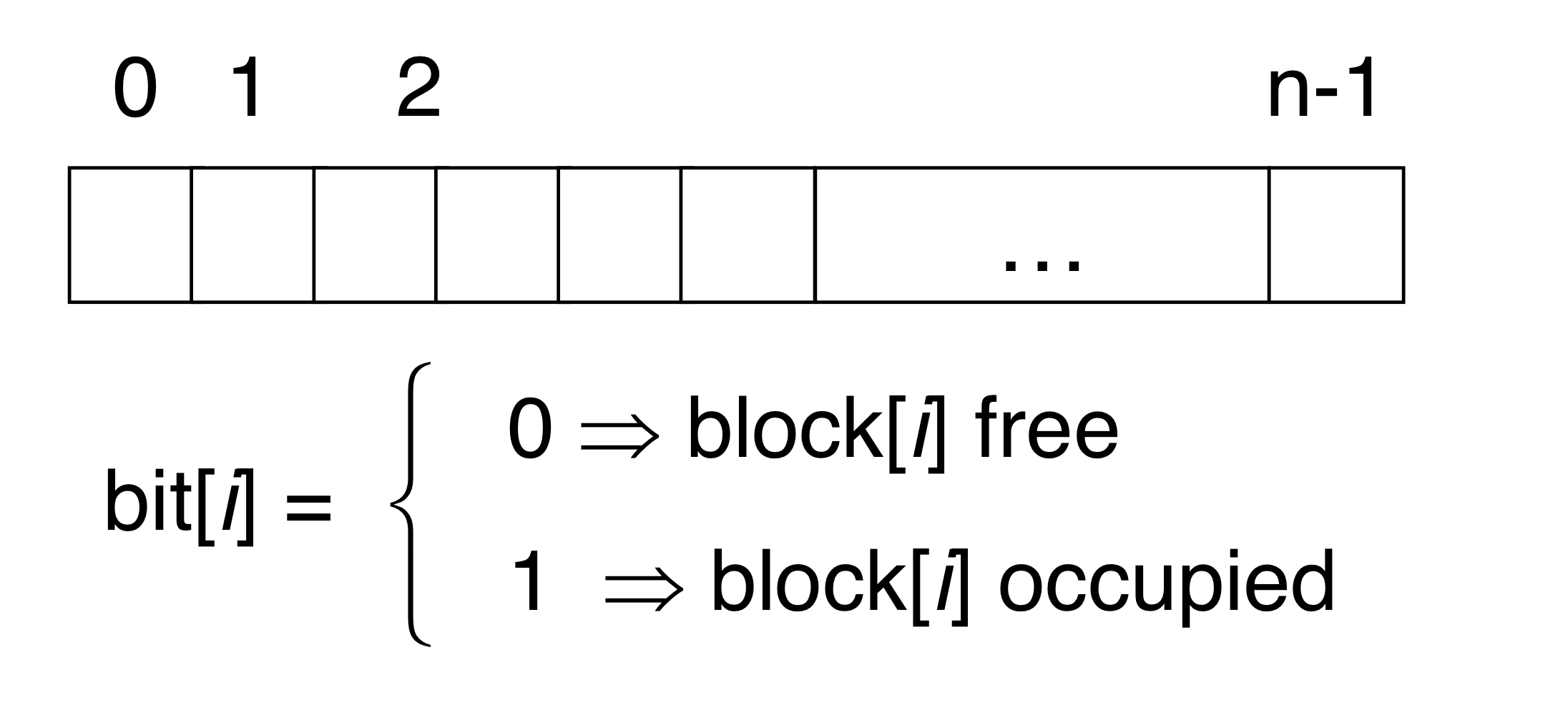
- 간단하지만 추가적인 공간이 필요하다.
- block size = 2^12 bytes
- disk size = 2^30 bytes (1 gigabyte)
- n = 2^30/2^12 = 2^18 bits (or 32K bytes)
- 전체 vector가 main memory에서 유지되지 않는다면 비효율 적이다.
b) Counting and Grouping
- Counting
- contiguous allocation의 장점을 갖는다.
- 첫 번째 free 블록 주소와 뒤에 따라오는 n free block의 개수를 유지한다.
- Grouping
- 첫 번째 빈 블록에 n-1개의 비연속적인 빈 블록의 주소를 저장한다.
- 마지막 블록은 다른 n개의 빈 블록 주소를 저장한다.
- 큰 숫자의 free block들이 쉽고 빠르게 찾을 수 있다.
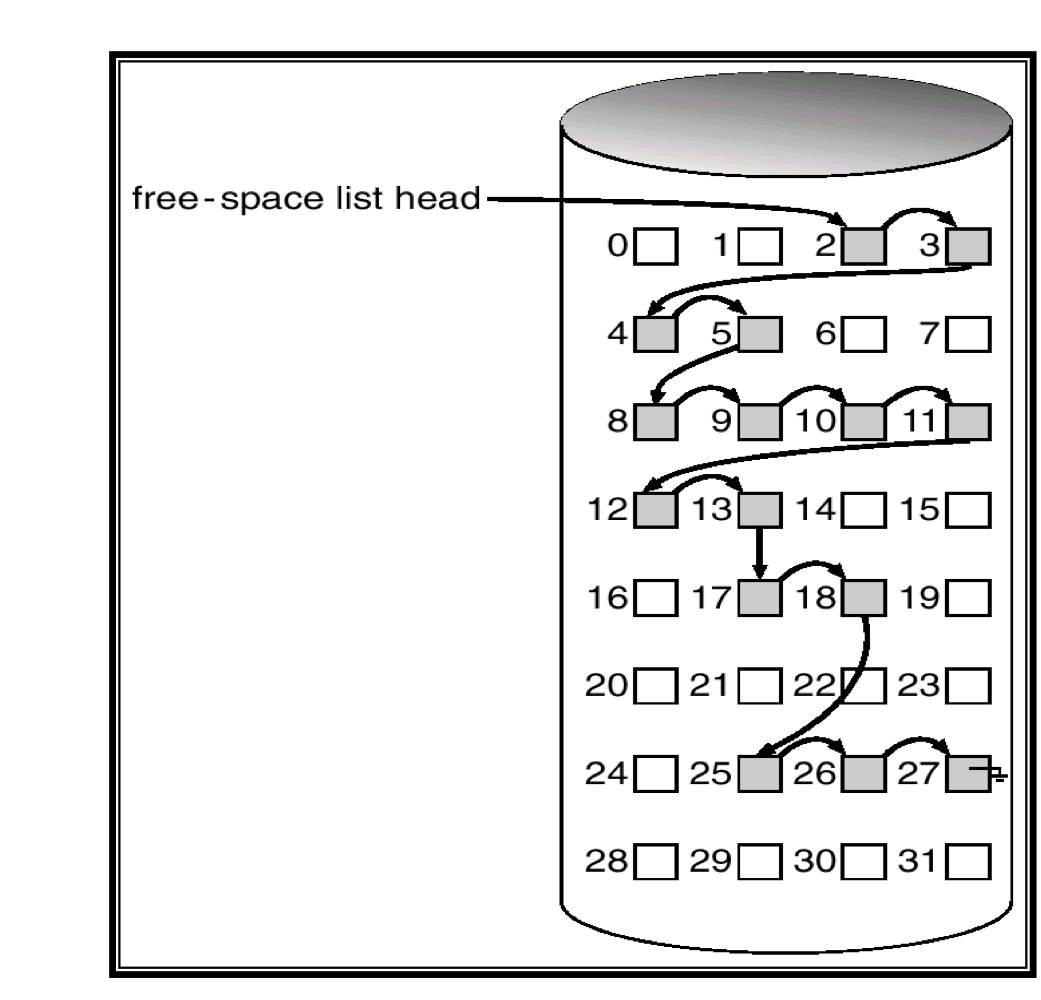
c) Linked list
- Linked list(free list)
- 모든 빈 disk block을 연결하여 첫번째 block에 대한 pointer를 disk의 특정 위치에 유지하고 이를 메모리에 caching하는 방법이다.
- 쉽게 연속적인 공간을 얻을 수 없다.
- 빈 블록의 목록을 순회하기 위해서는 각 블록을 읽어야한다.
- 다행히도 순회하는 작업은 빈번하지 않다.
3. More Topics
1) Page Cache and Buffer Cache
- 일부 시스템은 disk cache를 위해서 별도의 main memory section을 유지한다.
- buffer cache or block cache
- file system을 통한 routine I/O는 buffer (disk) cache를 이용해서 이루어진다.
- 일부 시스템은 page cache를 유지한다.
- virtual memory기술을 사용하여 disk block이 아닌 page를 cache한다.
- virtual memory techniques and memory-mapped I/O는 page cache를 사용한다.
2) I/O Without a Unified Buffer Cache
- 가상 메모리 시스템은 buffer cache와 interface할 수 없다.
- 가상 메모리는 page 단위, buffer cache는 block 단위
- buffer cache에 있는 file의 내용을 page table로 복사해야한다.
- 이것은 두번의 캐싱 작업이기에 double caching problem
- Caching file system data twice
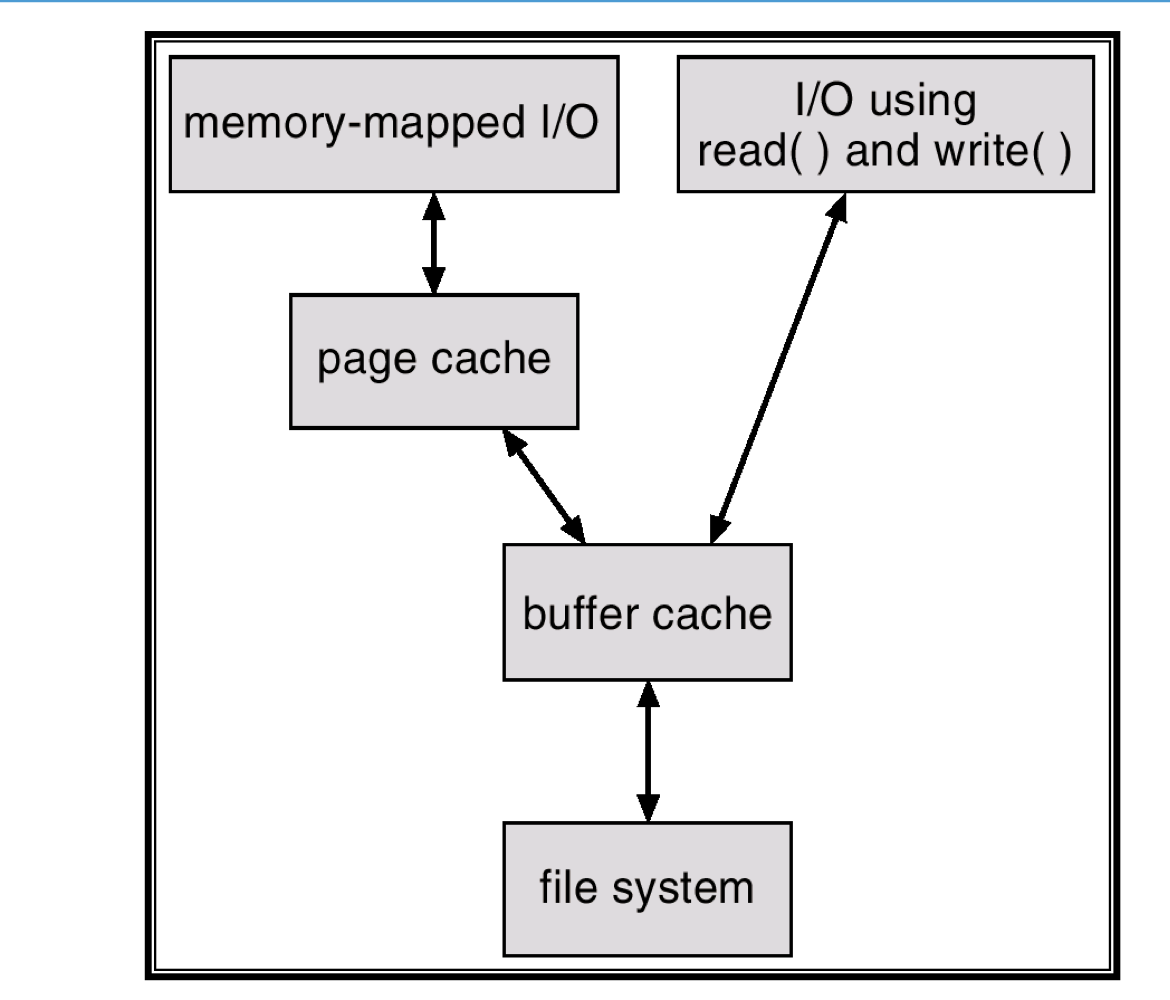
3) Unified Buffer Cache
- unified buffer cache는 memory-mapped page와 일반 파일 시스템 I/O에 동일한 버퍼 캐시를 사용한다.
4) Journaling File System
- 파일 시스템을 업데이트 하며 파일과 디렉토리의 변경 사항을 반영하는 것은 일반적으로 별개의 쓰기 작업이 필요하다.
- 이것은 interruption(like a power failure or system crash) 상황일 때에 데이터 구조가 유효하지 않은 상태로 남을 수 있다.
- 예를 들어서 UNIX file system에서 file을 삭제하는 과정은 세 단계로 이루어진다.
- directory entry제거
- inode를 free inode poll로 반환
- 사용된 disk block을 free disk block로 반환
- 만약 단계 1이 수행된 후 단계 2 이전에 시스템이 중단된다면, orphaned inode가 생길 수 있고, 이는 storage leak를 유발한다.
- 만약 단계 2만 수행된 후 중단이 발생한다면, 아직 삭제되지 않은 파일이 자유롭게 표시되고 다른 누군가에 의해 덮어질 가능성이 있다.
- 즉, 파일이 삭제되었지만 해당 공간이 다른 파일에 의해 덮어쓰일 가능성이 있다.
- 이러한 불일치를 감지하고 복구하는 작업은 일반적으로 fsck(파일 시스템 체크)와 같은 도구를 사용하여서 data structures를 완전히 탐색해야한다.
- 이러한 작업은 주로 file system이 다음 read-write access를 위해 mount 되기 전에 수행되어야한다.
- 만약 file system이 크고, I/O bandwidth가 상대적으로 작은 경우, 이것은 오랜 시간 걸리고 긴 downtime을 유발한다.
- 이것을 막기 위해서는, journaling file system은 사전에 만들 변경 사항을 기록하는 특별한 영역 “journal”을 할당한다.
- journal은 on-disk structure (file)로, 로그 형식으로 메타 데이터 변경 사항을 포함한다.
- 시스템이 충돌한 후, 복구작업은 journal을 읽고 이 journal에서 변경 사항을 다시 실행하여 파일 시스템이 다시 일관된 상태가 될 때 까지 진행한다.
- 이러한 변경은 atomic 하다고 말할 수 있다, 즉 변경 사항은 성공적으로 완료 되었거나 복구 중에 완전히 다시 실행되거나, 전혀 다시 실행되지 않는다. (충돌 발생 전에 저널에 완전히 기록되지 않기 때문에)
