
📌 01. NLP의 기본 용어
- 말뭉치 (corpus) 와 토큰 (token)
- 모든 NLP 작업은 말뭉치라 부르는 텍스트 데이터로 시작
- 말뭉치(데이터셋): 원시텍스트(ASCII, UTF-8 등의 문자 시퀀스) + 메타 데이터(텍스트와 연관된 메타데이터) -> 이걸 샘플 or 데이터 포인트라 부름
- 원시 텍스트는 문자를 토큰이라는 연속된 단위로 묶었을 때 유용
- 토큰: 공백 문자나 구두점으로 구분되는 단어와 숫자
- 토큰화 (tokenization)
- 텍스트를 토큰으로 나누는 과정
- 교착어(ex. 터키어)는 공백 문자와 구두점으로 나누는 것으로는 충분하지 않다. -> 텍스트를 바이트 스트림으로 신경망에 표현
- 토큰화의 기준은 저마다 다름, 하지만 토큰화 과정이 정확도에 큰 영향을 미침
- 오픈소스 NLP 패키지는 대부분 기본적인 토큰화를 제공
ex) NLTK tokenizer
from nltk.tokenize import TweetTokenizer
tweet = u"Snow White and the Seven Degrees #MakeAMovieCold@midnight:-)"
tokenizer = TweetTokenizer()
print(tokenizer.tokenize(tweet.lower()))
# output : ['snow', 'white', 'and', 'the', 'seven', 'degrees', '#makeamoviecold', '@midnight', ':-)']- n-그램
- 텍스트에 있는 고정길이(n)의 연속된 토큰 시퀀스
유니그램 : 토큰 1개로 이루어짐
바이그램 : 토큰 2개로 이루어짐
트라이그램 : 토큰 3개로 이루어짐
- 부분 단어 자체가 유용한 정보를 전달한다면 문자 n-gram 생성 가능
ex. 'methanol'의 '-ol'은 알코올 종류를 나타냄 -> 유기 화합물 이름을 구분하는 작업에서는 n-gram으로 찾은 부분 단어의 정보가 유용
- spaCy와 NLTK 같은 패키지로 구현 가능
- 텍스트에 있는 고정길이(n)의 연속된 토큰 시퀀스
def n_grams(text, n):
return [text[i:i+n] for i in range(len(text)-n+1)]
cleaned = ['mary', ',' ,"n't", 'slap', 'green', 'witch', '.']
print(n_grams(cleaned, 3))
# output
# [['mary', ',' "n't"], [',', "n't", 'slap'], ["n't", 'slap', 'green'],
# ['slap', 'green', 'witch'], ['green', 'witch', '.']]- 표제어
- 단어의 기본형
ex.) fly(표제어) -> flow, flew, flies, flown, flowing
- 표제어 추출 : 토큰을 표제어로 바꿔 벡터 표현의 차원 축소
- spaCy는 WordNet 사전을 사용해 표제어 추출
- 표제어 추출은 언어의 형태론을 이해하려는 머신러닝의 문제로 나타날 수 있다. -> 어간 추출 사용
- 어간 추출 : 수동을 ㅗ만든 규칙을 사용해 단어의 끝을 잘라 어간이라는 공통 형태로 축소
- 잘라진 단어는 현존하는 단어가 아닐 수 있다.
- 각 알고리즘 마다 결과가 다르다
- ex.) 오픈소스 Porter, Snowball 어간 추출기
- 단어의 기본형
📌 02. NLP 응용 작업
-
문장과 문서 분류
- TF와 TF-IDF 표현이 긴 텍스트 뭉치를 분류할 때 유용
- TF와 TF-IDF 표현이 긴 텍스트 뭉치를 분류할 때 유용
-
단어 분류
- 문서에 레이블을 할당하는 개념을 단어나 토큰으로 확장할 수 있다.
- ex) 품사 태깅 (토큰화한 단어에 품사를 태깅)
import spacy
nlp = spacy.load('en')
doc = nlp(u"Mary slapped the green witch.")
for token in doc:
print('{} - {}'.format(token, token.pos_))
# output
# Mary - PROPN (고유명사)
# slapped - VERB (동사)
# the - DET (한정사)
# green - ADJ (형용사)
# witch - NOUN (명사)
# . - PUNCT (구두점)- 청크 나누기
- 연속된 여러 토큰으로 구분되는 텍스트 구에 레이블을 할당
- 부분 구문 분석이라고도 한다.
- 부분 구문 분석에 사용할 데이터가 없다면 품사 태깅에 정규식을 적용
- 명사구(NP) 부분 구문 분석
👉 품사 태깅 코드에서 output이 Mary - NP, the green witch - NP
- 구 단위 외에 개체명 단위도 유용하다.
개체명 단위는 사람, 장소, 회사, 약 이름과 같은 실제 세상의 개념을 의미하는 문자열

📌 03. 문장 구조
-
구문 분석 : 구 사이의 관계를 파악
-
구분 분석 트리 : 문장 안의 문법 요소가 계층적으로 어떻게 관련되는지를 보여준다.
✔ 구성 구문 분석 트리
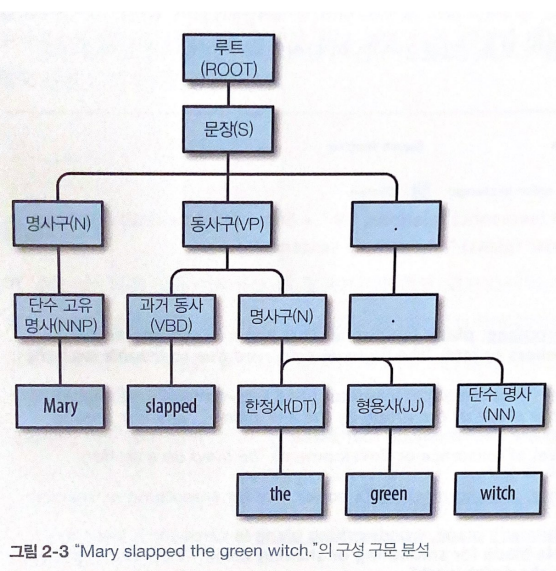
✔ 의존 구문 분석

