
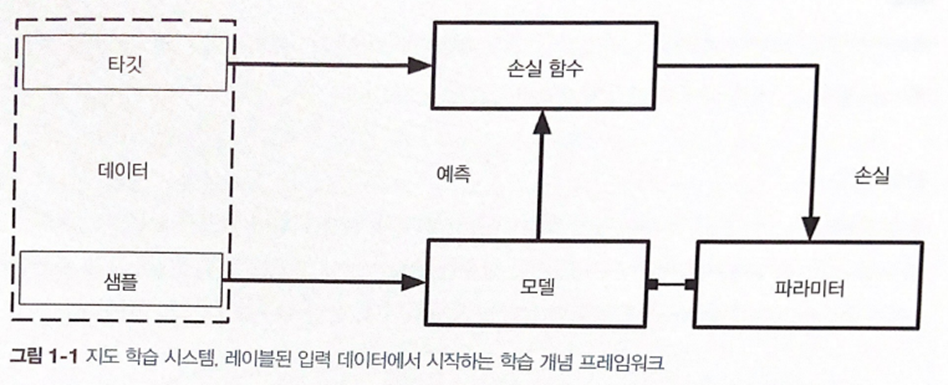
📌 01. 지도 학습이란?
-
샘플에 대응하는 예측값(타깃)의 정답을 제공하는 방식
샘플이 문서면 타깃은 범주형 레이블 -
목적 : 주어진 데이터셋에서 손실 함수를 최소화하는 파라미터 값을 고르는 것 👉 경사 하강법 사용
<동작 과정>
1. 샘플을 파라미터를 가진 모델에 넣으면 예측을 합니다.
2. 예측한 값과 타깃이 손실함수를 거치고, 거기서 나온 손실로 파라미터를 업데이트 합니다.
파라미터를 반복적으로 업데이트하는 과정을 역전파,
예측값과 타깃으로 손실함수를 계산하는 과정을 정방향 계산,
손실로 파라미터를 업데이트 하는 과정을 역방향 계산 이라고 합니다.
📌 02. 그렇다면 경사 하강법은 뭘까?
- 경사 하강법 (GD)
- 파라미터의 초깃값을 추측한 다음에 손실 함수의 값이 임계점 아래로 내려갈때까지 파라미터를 반복적으로 업데이트
- 데이터셋이 너무 크면 시간과 비용이 많이 든다는 문제 존재
- 확률적 경사 하강법 (SGD)
- 무작위로 뽑은 하나의 훈련 데이터에 대해 gradient를 계산
- 실행 속도가 빠르지만, 무작위로 뽑기 때문에 성능이 들쑥날쑥하다는 문제 존재
✔ GD와 SGD의 절충안으로 나온 것이 미니 배치 확률적 경사 하강법 (MSGD)
- 미니 배치 확률적 경사 하강법 (MSGD)
- 전체 데이터를 batch_size 개씩 나눠 batch로 학습
- 최근 사용하는 방법
📌 03. 원-핫 인코딩
from sklearn.feature_extraction.text import CountVectorizer
import seaborn as sns
corpus = ['Time flies like an arrow.',
'Fruit flies like a banana.']
one_hot_vectorizer = CountVectorizer(binary=True)
one_hot = one_hot_vectorizer.fit_transform(corpus).toarray()
vocab = one_hot_vectorizer.get_feature_names()
sns.heatmap(one_hot, annot=True,
cbar=False, xticklabels=vocab,
yticklabels=['Sentence 1', 'Sentence 2'])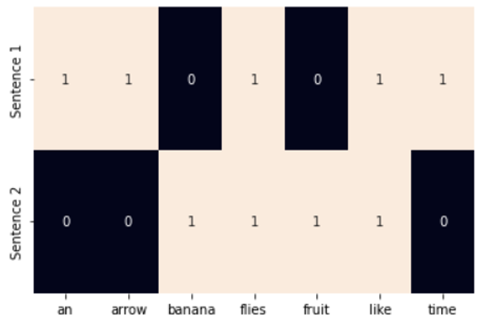
👉 문장이나 단어에 상응하는 원소를 1, 상응하지 않는 원소를 0 으로 표현 (CountVectorizer 클래스는 글자 하나로 이루어진 단어는 무시하기 때문에 a 단어는 히트맵에 나오지 않는다.)
📌 04. TF와 TF-IDF
- TF 표현 (Term-Frequency : 문서 빈도)

- 만약 문서 묶음에서 'A를 주장했다.', '핵심을 주장했다.', 'B를 주장했다.' 등이 있으면 ‘주장했다’라는 단어는 빈도수가 높지만 크게 중요한 말은 아니고, ‘핵심’이란 단어가 빈도수는 1로 낮지만 ‘주장했다’보다는 훨씬 중요한 말이다.
- 이런 경우에, 문서 빈도 방식을 사용하면 빈도수에 비례하여 가중치를 부여하기 때문에 중요하지 않은 말에 큰 가중치가 부여될 수 있다. 따라서, 이런 경우에는 역문서 빈도 방식인 IDF 방식을 사용한다.
- 만약 문서 묶음에서 'A를 주장했다.', '핵심을 주장했다.', 'B를 주장했다.' 등이 있으면 ‘주장했다’라는 단어는 빈도수가 높지만 크게 중요한 말은 아니고, ‘핵심’이란 단어가 빈도수는 1로 낮지만 ‘주장했다’보다는 훨씬 중요한 말이다.
-
IDF 표현 (Inverse-Document-Frequency : 역문서 빈도)
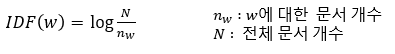
-
TF-IDF 표현
- TF-IDF 는 TF(w) * IDF(w)
from sklearn.feature_extraction.text import TfidfVectorizer
import seaborn as sns
corpus = ['Time flies like an arrow.',
'Fruit flies like a banana.']
tfidf_vectorizer = TfidfVectorizer()
tfidf = tfidf_vectorizer.fit_transform(corpus).toarray()
sns.heatmap(tfidf, annot=True, cbar=False, xticklabels=vocab,
yticklabels = ['Sentence 1', 'Sentence 2'])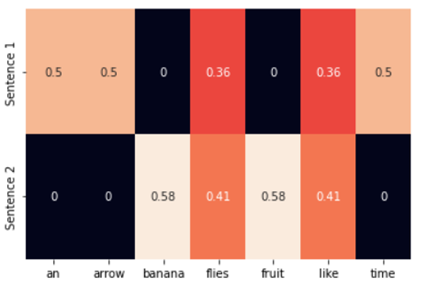
🤔 왜 이런 숫자가 나올까?

-> heatmap의 Sentence 1에서 flies와 like의 값은 0.3552를 반올림한 값이 0.36
