
NoSQL
문서 데이터베이스는 데이터가 문서 자체에 포함돼 있으면서 하나의 문서와 다른 문서 간 관계가 거의 없는 사용 사례를 대상으로 한다.
대표적으로 log structured storage engine 방식이 있고 로그는 특정값을 수정하는게 아닌 append 방식으로 쓰기성능이 o(1)이고 읽기 성능이 o(n)이다 이때 조회성능을 올리기 위해 여러 방법들과 색인전략들을 활용한다.
Hash Index
Hash Index는 해시 함수를 사용하여 각 항목의 키 값을 해시 코드로 변환하고, 이 해시 코드를 인덱스로 사용하여 데이터를 빠르게 찾을 수 있게 해줍니다.
속도
-
조회 속도 : Hash Index의 조회 속도는 평균적으로 O(1) 이는 해시 함수를 사용하여 키 값을 해시 코드로 변환하고, 이 해시 코드를 바탕으로 직접적으로 데이터의 위치를 찾을 수 있기 때문에 발생하는 시간 복잡도입니다.
-
쓰기 속도: Hash Index의 쓰기 속도는 평균적인 경우 O(1) 새로운 데이터를 추가할 때 해시 함수를 통해 계산된 위치에 데이터를 저장하기 때문에, 빠르게 처리할 수 있습니다.
그러나 해시 테이블에서 해시키 충돌이 발생하면 추가적인 시간이 소요될 수 있으며, 이는 최악의 경우 O(n)까지 증가할 수 있습니다.
작동원리
| 사용자 ID | 이름 | 나이 | 이메일 |
|---|---|---|---|
| 001 | 상규 | 22 | tkdrb@example.com |
| 002 | 형준 | 27 | gudwns@example.com |
| 003 | 보성 | 52 | qhtjd@example.com |
위와 같은 데이터가 파일에 로그 방식으로 데이터가 저장되어 있다고 가정합시다.
[{"사용자 ID": 001,"이름": "상규","나이": 22,"이메일": "tkdrb@example.com"},{"사용자 ID":
002,"이름": "형준","나이": 27,"이메일":"gudwns@example.com"},{"사용자 ID": 003,"이름": "qhtjd",
"나이": 52,"이메일":"qhtjd@example.com"}]각 사용자의 시작위치를 파일에서의 바이트 offset으로 기록하여 인메모리 해시맵에 기록합니다.
예를들어 상규 데이터의 시작위치가 0바이트, 형준의 시작위치가 50바이트, 보성의 시작 위치가 100바이트라고 한다면 인메모리 HashMap에는 Key값에 사용자의 식별값, Value값엔 오프셋이 기록됩니다.
{
001: 0,
002: 50,
003: 100
}이렇게 사용자의 데이터가 있는 시작 위치를 빠르게 찾아내고 데이터를 읽어옵니다.
특징
- 해시값을 인덱스로 활용하기 때문에 원본 데이터를 활용하는 연산이 어렵습니다.(정렬, 범위 연산 등).
- 유니크한 데이터의 검색에 최적화된 인덱스이다.
- HashMap에 모든 Key들이 들어가 있기 때문에 메모리에 전부 들어갈 수 있어야 합니다.
Segment
log structured storage engine 방식을 사용해서 데이터를 append해서 저장하다보면 나중엔 디스크 공간이 부족해집니다.
그렇기 때문에 데이터를 특정크기의 세그먼트로 나눕니다.
그리고 Active하지 않은 세그먼트를 컴팩션하는 과정을 거칩니다.
Active 세그먼트는 현재 데이터가 쓰여지고 있는 세그먼트를 의미합니다. 이 세그먼트는 여전히 열려 있어 데이터베이스가 추가 데이터를 계속해서 저장할 수 있습니다.
컴팩션
컴팩션이란 데이터가 세그먼트에서 계속 추가됨에 따라, 일부 데이터는 더 이상 유효하지 않게 되거나 더 최신의 값으로 대체될 수 있습니다. 이전 데이터는 불필요하게 공간을 차지하게 되므로, 이를 merge하거나 삭제하는 방식으로 정리합니다.
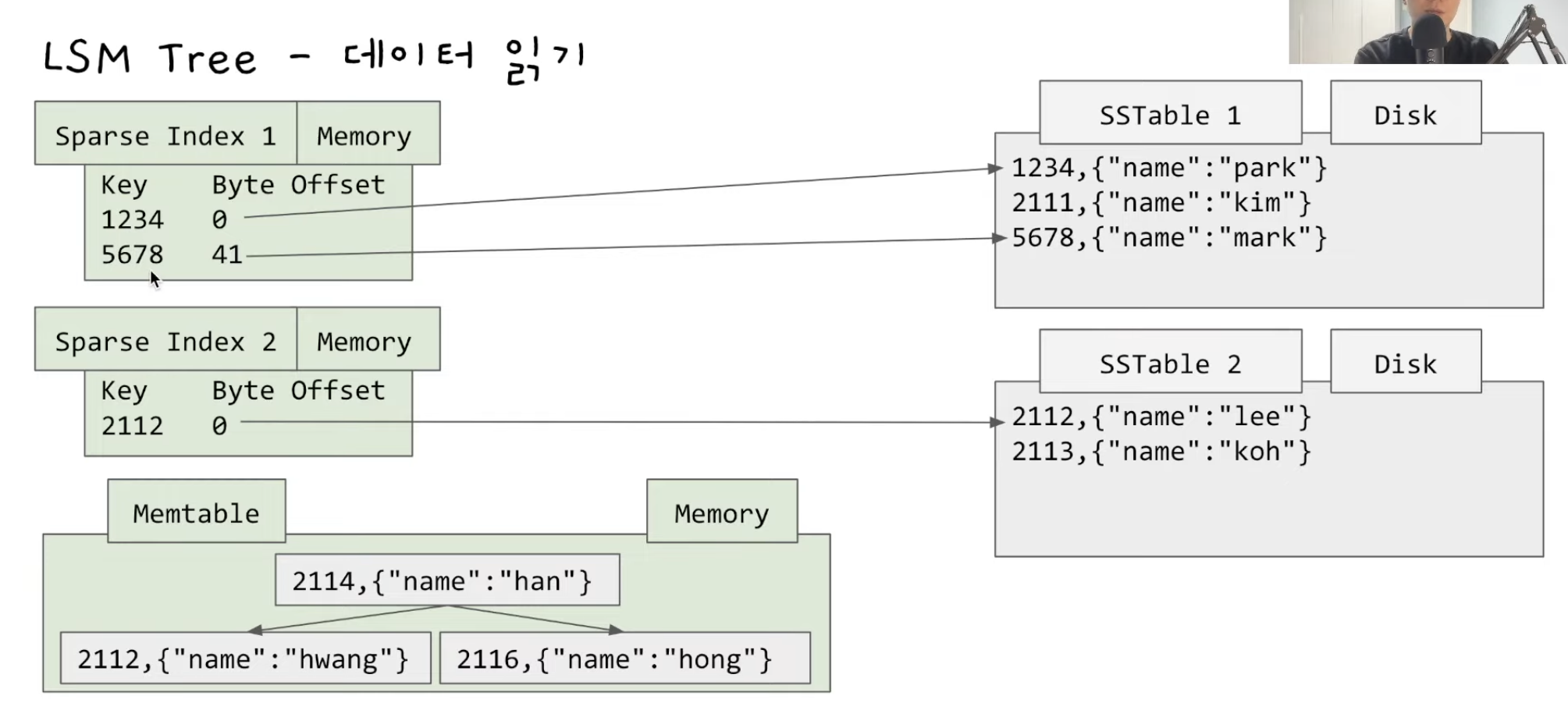
LSM Tree (Sorted string table)
해시인덱스의 단점으로는 range query가 불가능합니다.
이걸 보완하기 위해 SS table을 사용하고 데이터가 저장된 바이트의 오프셋의 위치가 저장된 해시맵의 키가 정렬이 되어있습니다.
SS Table의 특징
SS Table은 키-값 쌍을 키의 순서대로 정렬하여 저장합니다. 정렬된 구조는 범위 검색을 지원합니다. 또한 한 번 디스크에 쓰여진 후, SS Table은 수정되지 않고 불변한 상태를 유지합니다.(Active하지 않은 세그먼트)
NoSQL 데이터베이스가 빠른 이유 | LSM Tree 완전정복 | DB 의 데이터 저장 방법 - 코맹탈출 - 실리콘밸리 개발이야기
Memtable(인 메모리)이 Balanced Binary Tree를 이루며 정렬이 되어있고 특정 사이즈만큼 커지면 SS table로 flush됩니다.
Memtable은 메모리에 위치하므로 데이터베이스 쓰기 연산은 매우 빠르게 처리될 수 있습니다. 이는 디스크 I/O를 필요로 하지 않기 때문입니다.
만약 Memtable에 데이터가 있고 SS Table에 flush하기 전 DB가 Down되게 된다면 로그파일을 통해 Memtable의 데이터를 복구할 수 있습니다.
LSM Tree 정리
- Write가 빠름
- Memtable과 logfile만 업데이트 하면됨
- Sparse Index
- Memtable이 모든 키 값을 가지고 있지 않아 적은 공간을 사용함
- 하지만 주어진 레코드의 키를 찾는데 Memtable에 있지 않다면 조금 더 시간이 걸림
- 참고 블로그
- SS Table이 정렬되어 있어 컴팩션 과정에서 merge하기 쉬움
reference:
