코드스쿼드 마스터프로젝트 중 이슈트래커 작업 중 테이블 설계와 JPA로 구현하면서 관계맵핑 관련한 부분들을 정리 해봤습니다.
설계와 테이블 관계 맵핑
이번에는 설계가 한번에 바로 나오지 않았습니다.
JDBC 라면 크케 고민 하지 않았을 부분이었지만, JPA 로 관계맵핑 하기 좋은 테이블 구조는 무엇일지 고민하는 시간을 밤새 가져 보았습니다.
이전 작업에서 팀원이 단순하게 설계해놓은 ERD를 그냥 작업했지만, 이번에 혼자 진행하는 만큼 쓰여야 할 부분들을 제외시키고 싶진 않았고, 3주 기간 동안 할 수 있는 정도의 복잡성에 대해 고민이 있었습니다.
이슈트래커는 뭐지?
-
처음에는 단순하게 이슈 목록들을 나열하는 걸로 생각하고 시작하였는데요, 사용 용도를 생각하면서 이슈목록에서 보여져야 하는 관계되는 테이블들을 생각안 할 수 없었습니다.
-
여러개가 있는 라벨, 하나만 있는 마일스톤
- 라벨은 예시로 팀별 작업단위에 쓰입니다.
- 마일스톤은 해당 이슈의 작업기간으로 다른 작업기간은 다른 이슈로 생성하면서 구분지어 작업할 수 있거나, 하나의 마일스톤으로 정해진 작업 기간내에 여러 이슈들이 생성되어 목표단위로 작업될 수 있습니다.
-
초반에 살짝 캘린더 구현을 시도해 봤습니다. 일정관리와 차이가 무엇일지 좀더 구체적으로 보고서 이슈트래커의 비즈니스 로직을 들여다 봐야겠다 싶었습니다.
- 구글 캘린더를 보면, 날짜를 작업기간으로 공유 할 수 있습니다.
- 23일,24일 내가 배포한다면, 23일날 FE에서 UI header 작업을 진행하는 등, 날짜 중심으로 보여집니다.
- 구글 캘린더를 보면, 날짜를 작업기간으로 공유 할 수 있습니다.
-
이슈 트래커는 작업단위 중심으로 팀별, 기간별 구분 하여 이용하고, 처리되는 이슈는 open 상태에서 close 하여 처리할 작업에 집중도를 높일 수 있다고 생각했습니다. (🤡..이런게 새로운 서비스 구현 재미)
-
그래서, 라벨, 마일스톤이 쓰이는 상황이라면...
- 이슈는 팀별로 별도로 각자가 쓰일 수 있다.
- 라벨과 마일스톤은 공유 될 수 있다.
- 팀이라는 개념이 각각의 사람들이 접근하고 작업하는데 있어야 한다.
-
어려웠던게 팀이란게 보통 생각하는 개념과 달랐던 점이예요. 라벨 하나로 팀을 구별할 수 있는 점이죠.
- 프로젝트 단위로 멤버 구성되고, 전체 이슈 관리, 라벨, 마일스톤이 나뉘어 진다고 정리했습니다.
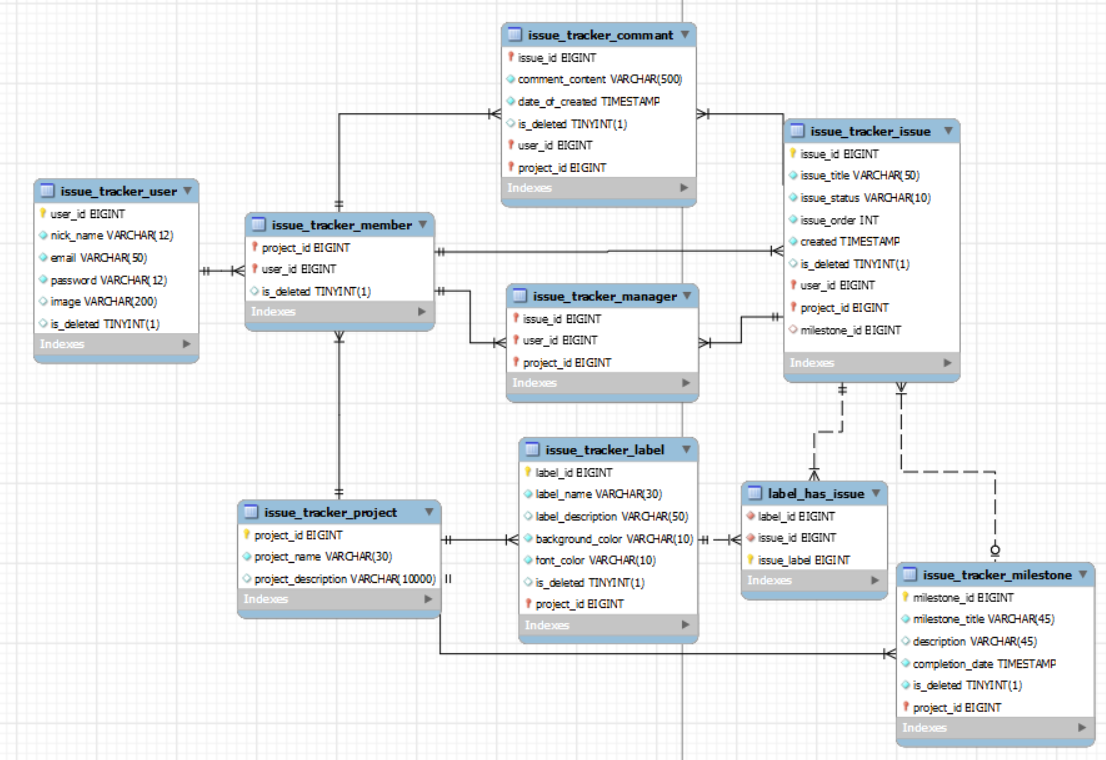
-
이때는 로그인을 나중으로 미루면서 세션로그인을 생각한 user 테이블만있다.
- 사용자 관련 부분이 애매하다보니 AuthUser 클래스를 생성해서 userId, projectId를 담아 모든 요청시 이용하도록 작업했다.
마일스톤과 라벨의 차이
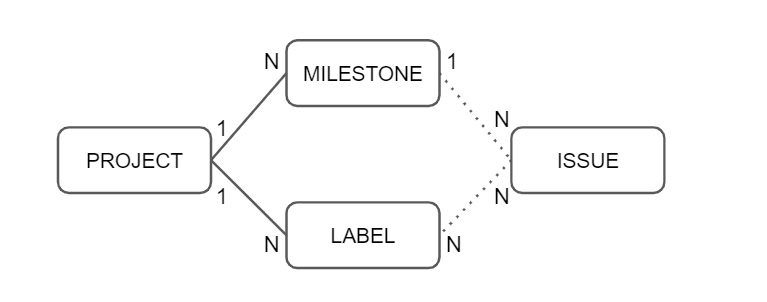
테이블에서 n:m의 관계를 풀기 위해
label_has_issue라는 테이블을 추가했다. 여기서는 부모키를 참조한 외래키를 기본키로 하지 않고, 기본키를 추가하면서 비식별자 관계로 맵핑 했다.
- JPA에서 이슈 목록 조회시 라벨을 어떻게 가져올까?
issue_tracker_label테이블에는 필수관계인 project만을 FK로 참조하고 있따.label_has_issue를 통해 라벨을 가져온다.- 엔티티
Label은Issue와 연관관계 갖지 않는다.
@OneToMany(mappedBy = "issue")
private List<IssueLabel> issueLabels = new ArrayList<>();마일스톤은 이슈와는 1:n의 관계로
issue_tracker_issue테이블이 mileston를 FK로 참조하고 있다.
- JPA에서는
Issue에서 다대일 단방향 연관관계 매핑 했다. - 나중에 마일스톤 조회 목록에서 이슈의 상태별 진행과정 처리히
Issue를 갖게 오고자 한다면 다대일 양방향도 가능하다.
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "milestone_id")
private Milestone milestone;이슈 중심으로 관계맵핑들을 정리하고 그외는 분리되도록 했습니다. 마일스톤 조회시 이슈 상태별 마일스톤 progress bar 위한 이슈 상태 개수 조회는 어떻게 할지 고민이었습니다.

1. 일대다 양방향 연관관계 맵핑
- right outer join 으로 가져오면 중복 많고, 개수외에는 Issue의 정보가 필요하지도 않고 다른 방법을 찾아 봤습니다.
2. 쿼리 작업해보니, JPQL ?
select
issue_status, count(issue_status) as status_count
from
(
select issue_status, milestone_id from issue_tracker_issue a where milestone_id in (3,4)
) b
group by b.issue_status, milestone_id;
JPA의 최대 걸림돌이 from절의 서브쿼리인 인라인뷰(inlineview)
- 그래도 답이 안나오면 네이티브 쿼리를 사용한다. 😮 (잘못 온걸까?)
3. 그럼 서브쿼리 없애보자, JPA Group by는 어떻게 ?
select
issue_status, count(issue_status) as status_count, milestone_id
from
issue_tracker_issue
where milestone_id in (3,4)
group by issue_status, milestone_id;- Spring Data JPA에서 Group by 처리하기
- 결국, 네이티브 쿼리 🙄
- 잘쓴 건지 모르겠지만 생각보다 간단했습니다.
- 내가 조회해올 컬럼에 대한 메서드를 interface로 정의해서 dto로 가져와 사용하면 돼요.
public interface NumberOfIssueStatus {
String getIssueStatus();
Long getStatusCount();
Long getMilestoneId();
}@Query(value =
"select issue_status as issueStatus, count(issue_status) as statusCount, milestone_id as milestoneId"
+ " from issue_tracker_issue"
+ " where milestone_id in :milestoneIds"
+ " group by issue_status, milestone_id", nativeQuery = true)
List<NumberOfIssueStatus> findGroupBy(@Param("milestoneIds") List<Long> milestoneId);조회 → 끝? 😭
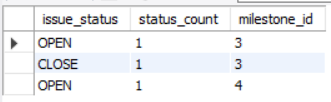
마일스톤 목록에 필요한 IssueStatus 정보는 milestonId별 OPEN 상태의 IssusStatus 개수와 CLOSE 상태의 IssueStatus 개수
- IssueService
- milestone_id 별로 OPEN과 CLOSE의 개수를 묶어 전달할 필요가 생겼습니다. (설계는 멀어졌고, 앞만본다...)
- 상태별 개수를 담을 클래스를 하나 생성 :
NumberOfIssueStatusDto - milestoneId를 키로 각각의 값들을 Map에 담았습니다. :
NumberOfIssueStatusAndMilestoneDto
- 상태별 개수를 담을 클래스를 하나 생성 :
- milestone_id 별로 OPEN과 CLOSE의 개수를 묶어 전달할 필요가 생겼습니다. (설계는 멀어졌고, 앞만본다...)
public NumberOfIssueStatusAndMilestoneDto readByMilestones(List<Long> milestoneIds) {
List<NumberOfIssueStatus> numberOfIssueStatuses = issueRepository.findGroupBy(milestoneIds);
return NumberOfIssueStatusAndMilestoneDto.from(numberOfIssueStatuses);
}- MilestoneService
- 조회해온 Milestone들의 id별 IssueStatus 개수를 가져와서 application 단에서 join
@Transactional(readOnly = true)
public List<MilestoneResponse> readAll(AuthUser authUser) {
List<Milestone> milestoneInfo = milestoneRepository.findAllByProjectId(authUser.getProjectId());
Milestones milestones = Milestones.from(milestoneInfo);
NumberOfIssueStatusAndMilestoneDto numberOfIssueStatusMap = issueService.readByMilestones(
milestones.getMilestoneIds());
return milestones.toResponses(numberOfIssueStatusMap);
}검색시에는 어떻게 할까?
사실 검색부터 구현 했었는데, 이때부터 제가 outer join을 하지 않는 방향에서의 구현을 시도해보게 됐습니다. 🙃
검색기능은 이슈목록에서 각각 필터 버튼을 누르면 검색어 입력란에 추가되어지면서 검색 조회 요청합니다. ref
ex.is:open+author:sally+label:"feature"
- 검색키들은 생략 가능하다.
Issue:label= 1:n 으로 null 이거나 여러개 가져올 수 있다. +none이라는 검색이 가능하다.none?- 라벨이 없는 이슈조회 검색에 해당
- 여러개의 이슈목록 조회결과를 가져오면서
label의 개수가 각각 다를 때, 이슈의 중복 개수가 늘어날 수 있다. (거기에 마일스톤 등) - 페이징 처리하면서 일정개수만 조회해온다면 성능 이점을 생각해 중복도 괜찮지 않을까 싶기도 합니다.
- 결론은 ❕❔
- outer join을 안써본다면 구현은 먼저 해당 검색어에대한
Issue의 id 목록들을 통해 관련된label을 조회 해오게 하는데,- 앞서 말한 m:n 관계 풀기위해 비식별자로 기본키를 가지는
label_has_issue를 이용해 조회해오게 했습니다.- 라벨이 검색어로
none이거나 없다면 null, label 검색어가 있다면 검색어를 넣어 조회
- 라벨이 검색어로
- 앞서 말한 m:n 관계 풀기위해 비식별자로 기본키를 가지는
public List<IssueResponse.Row> search(AuthUser authUser, IssueSearchRequest request) {
IssueSearchParam searchParam = IssueSearchParam.from(request);
List<IssueLabelDto> issueLabels = issueSearchRepository.findIssueLabels(searchParam.labelName());
List<IssueSearchDto> resultOfSearch = issueSearchRepository.search(
authUser,
searchParam,
toIssueIds(issueLabels));
IssueLabelMapper issueLabelMapper = IssueLabelMapper.from(issueLabels);
return resultOfSearch.stream()
.parallel()
.map(issue -> IssueResponse.Row.from(issue, issueLabelMapper.getValue(issue.getIssueId())))
.collect(Collectors.toList());
}- 그 후에는
none이면 차집합으로, 검색어가 없다면 null, 있다면 해당 검색어가 포함된 label과 관련된 issueId만 조회하게 한다.
private BooleanExpression labelsFrom(String labelName, List<Long> issueIds) {
if (SearchKeyType.isNone(labelName)) {
return issue.id.notIn(issueIds);
}
return Strings.isBlank(labelName) ? null : issue.id.in(issueIds);
}결론은, 구현과정은 재미있었지만, 검색어에 따른 조회로직을 간단히 하고자 querydsl을 썼는데, 복잡해져서 그 장점이 사라진 것도 같다.
1. 코드를 개선 😐
2. outer join도... 😑
