TL;DR
- 문제: PDF 업로드 후 LLM 파싱까지 2분 소요 → 사용자 이탈
- 해결: OCR, LLM 파싱 병렬 처리 + 스트리밍으로 17초로 단축, 성능 7배 개선
- 결과: 첫 결과 표시 시간 9초, 사용자 체감 10배 개선
- 핵심: 완벽한 최적화보다 균형을 맞춰 빠른 실험-학습 사이클을 돌리자
앱 개발 배경
카페나 음식점에서 알바를 시작한 신입생들이 가장 힘들어하는 게 뭘까요? 바로 메뉴 외우기입니다.
"아메리카노는 에스프레소 2샷, 흑당라떼는 흑당시럽 3P에 우유 250ml, 카푸치노는 뭐고..."
레시피북을 보면서 하나하나 외워야 하는데, 메뉴가 매우 많아서 헷갈립니다. 그래서 게임처럼 재미있게 레시피를 외울 수 있는 앱을 만들고자 했습니다.
핵심 가치 제안
- AI 자동 메뉴 생성: 레시피 PDF/이미지 업로드 → 플래시카드 자동 생성
- 랜덤 암기 게임: 플래시카드를 뒤집으며 게임처럼 재미있게 암기
문제 발견: "니즈 확실한데 왜 안 쓰지?"
초기 가설
"니즈가 강력하면 UX 구려도 기능이 working하기만 하면 쓸 거다"
메뉴 생성에 2분이 걸려도 결국엔 쓸 사람은 쓸 거라 생각했습니다. 레시피를 외워야 하는 니즈가 크다고 생각했기 때문이었어요.
현실
메타 광고로 실험해봤습니다.
- 일일 예산: 5,000원 × 3일 x 크리에이티브 A/B
- 총 31명 랜딩페이지 방문
- 앱 설치: 4명
- 핵심 기능(랜덤 암기) 도달: 1명
- 리텐션: 거의 0%
사용자 행동 분석
결과적으로 실제 사용자 여정은 다음과 같았습니다.
1. 앱 설치 ✅
2. PDF 업로드 ✅
3. 메뉴 생성 대기... (2분) ⏳
4. 중간에 나감 ❌Amplitude로 전환율을 확인했더니 문제를 발견할 수 있었어요.
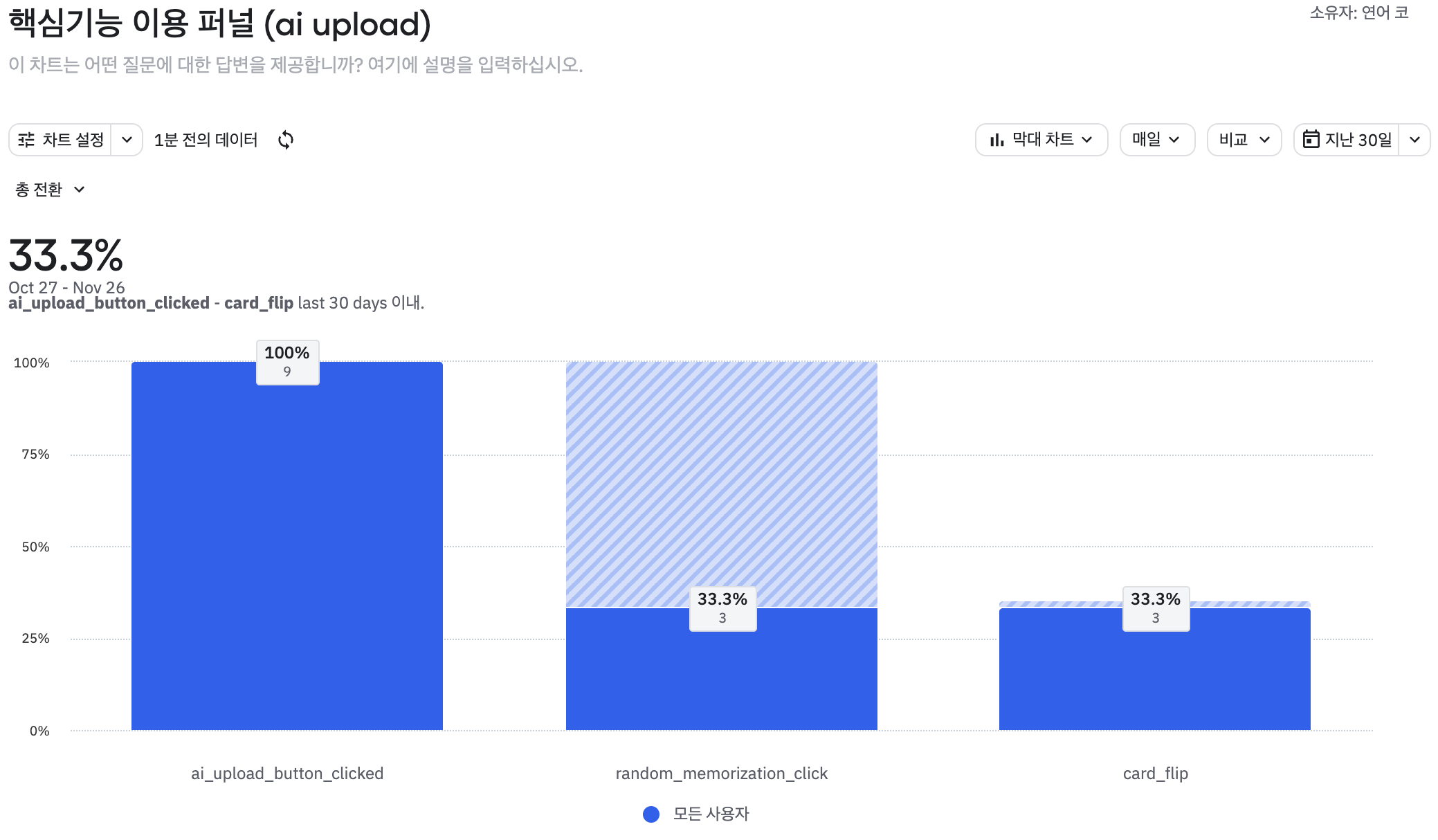
모수가 작긴한데(9명) 메뉴 생성 → 랜덤 암기로 이어지는 전환율이 33%밖에 안 됐습니다 (11.25 기준).
문제 진단: 왜 사용자가 이탈했을까?
1. 성능 문제
LLM 파싱 > OCR 처리 순으로 오래 걸렸습니다 (PDF 9페이지 기준).
총 처리 시간: 111초 (약 2분)
세부 분석:
1. PDF → 이미지 변환: 3초
2. OCR 텍스트 추출: 36초 (4초/페이지 × 9페이지) ⚠️ 병목 #2
3. LLM 파싱: 63초 (7초/페이지 × 9페이지) ⚠️ 병목 #1
4. 번역: 9초문제 발견
- LLM 파싱이 가장 오래 걸림 (전체의 57%)
- OCR 처리가 두 번째 (전체의 32%)
- 합치면 전체 시간의 89%를 차지
각 페이지를 순차적으로 처리하니까 로딩 시간이 길어졌어요
# 순차 처리 방식
for i, page_text in enumerate(recipe_text_list): # 9번 반복
# 1. OCR (4초) - 동기 작업
text = pytesseract.image_to_string(image)
# 2. LLM 파싱 (7초) - API 호출 대기
menu_response = await generate_menus_from_text(text)
# 총 11초 × 9페이지 = 99초2. UX 문제
실시간 피드백 없이 결과물이 나타나서 기다리다 못해 이탈한다고 판단했습니다.
로그인 → 레시피 업로드 → (메뉴 생성 111초) → 메뉴 리스트 → 랜덤 암기
↑
여기서 90% 이탈가장 오래 걸리는 LLM 파싱과 OCR을 병렬 처리할 필요성을 느꼈습니다.
사용자에게는 실시간으로 피드백을 줘서 체감 시간을 단축하고자 했습니다.
해결 과정: 단계별 성능 개선
Phase 1: LLM 파싱 병렬 처리 (시간 2분 → 1분)
문제 파악
병목 지점 #1: LLM 파싱이 전체 시간의 57%를 차지
기존 코드는 순차 처리였습니다.
# as-is: 순차 처리
for page_text in recipe_text_list:
menu_response = await generate_menus_from_text(page_text)
all_menus.extend(menu_response.menus)- PDF 9페이지: 각 페이지당 평균 7초 × 9 = 63초
- OpenAI API 호출 대기 시간이 누적됨
- 페이지 1 완료 → 페이지 2 시작 → ... → 페이지 9 완료
왜 이렇게 오래 걸릴까?
- OpenAI API 응답 대기: 평균 5~7초
- 각 페이지를 순차적으로 처리
- 페이지 간 의존성이 없는데도 기다림
해결책: asyncio.gather로 병렬 처리
# to-be: 병렬 처리
async def generate_menus_from_text_util(recipe_text_list: List[str]):
# 단일 페이지는 순차 처리가 더 빠름 (병렬 오버헤드 방지)
if len(recipe_text_list) == 1:
menu_response = await generate_menus_from_text(recipe_text_list[0])
return menu_response
# 다중 페이지는 병렬 처리로 성능 향상
# 모든 페이지를 동시에 처리
tasks = [generate_menus_from_text(text) for text in recipe_text_list]
results = await asyncio.gather(*tasks)
# 결과 합치기
all_menus = []
for menu_response in results:
all_menus.extend(menu_response.menus)
return MenuResponse(menus=all_menus)결과
| 파일 | 페이지 | Before (초) | After (초) | 개선율 |
|---|---|---|---|---|
| 빽다방 | 9p | 111.85 | 51.73 | 54% 개선 ⚡ |
| 컴포즈 | 9p | 47.67 | 29.99 | 37% 개선 |
| 메가커피 | 5p | 41.37 | 27.01 | 35% 개선 |
인사이트
- 다중 페이지(5p 이상): 1.5~2.2배 개선
- 단일 페이지(1p): 오히려 느려짐 -> 병렬 처리 오버헤드
추가 최적화: 단일 페이지 분기 처리
async def generate_menus_from_text_util(recipe_text_list: List[str]):
# 단일 페이지는 순차 처리가 더 빠름
if len(recipe_text_list) == 1:
menu_response = await generate_menus_from_text(recipe_text_list[0])
return MenuResponse(menus=menu_response.menus)
# 다중 페이지는 병렬 처리
tasks = [generate_menus_from_text(text) for text in recipe_text_list]
results = await asyncio.gather(*tasks)
# ...Phase 2: OCR 병렬 처리 (시간 1분 → 19초)
문제 파악
병목 지점 #2: OCR 텍스트 추출이 전체 시간의 32%를 차지
OCR도 기존에 순차 처리를 했었습니다.
# as-is: OCR 순차 처리
for i, image in enumerate(images):
page_text = pytesseract.image_to_string(image) # 4초/페이지
recipe_text_list.append(page_text)- PDF 9페이지: 4초 × 9 = 36초
- Tesseract OCR이 각 페이지마다 블로킹
- 이미지 → 텍스트 변환 작업도 독립적인데 순차 처리
현재 상태
- LLM 병렬화로 63초 → 52초 (11초 단축)
- 하지만 OCR 36초는 여전히 순차 처리
- 전체: 36초(OCR) + 52초(LLM) = 88초
해결책: OCR도 병렬 처리
# to-be: OCR 병렬 처리
async def extract_text_from_pdf(file_content: bytes) -> List[str]:
# PDF를 이미지로 변환
images = convert_from_bytes(file_content)
# 각 페이지를 병렬로 OCR 처리
async def ocr_single_page(index: int, image):
# pytesseract는 동기 함수이므로 asyncio.to_thread로 비동기 실행
text = await asyncio.to_thread(
pytesseract.image_to_string,
image,
'kor+eng'
)
return (index, text)
# 모든 페이지를 병렬로 OCR 처리
tasks = [ocr_single_page(i, image) for i, image in enumerate(images)]
results = await asyncio.gather(*tasks)
# 순서대로 정렬
text_list = [text for index, text in sorted(results, key=lambda x: x[0])]
return text_list핵심 포인트
asyncio.to_thread: 동기 함수(pytesseract)를 비동기로 실행- 페이지별로 독립적인 OCR 작업을 병렬 실행
- 결과를 순서대로 정렬하여 반환
결과
| 파일 | Before | After | 개선율 |
|---|---|---|---|
| 빽다방 9p | 51.73초 | 18.97초 | 63% 개선 ⚡ |
총 개선: 111초 → 19초로 6배 빨라졌습니다.
시간 분배 변화 (빽다방 9p 기준)
Before (순차 처리):
┌─────────────────────────────────────────────────────────┐
│ OCR: 36초 (32%) │ LLM: 63초 (57%) │ 기타: 12초 (11%) │
└─────────────────────────────────────────────────────────┘
총: 111초
After Phase 1 (LLM 병렬):
┌───────────────────────────────────────────┐
│ OCR: 36초 (69%) │ LLM: 7초 (14%) │ 기타: 9초 (17%) │
└───────────────────────────────────────────┘
총: 52초
After Phase 2 (LLM + OCR 병렬):
┌─────────────────┐
│ 병렬: 15초 (79%) │ 기타: 4초 (21%) │
└─────────────────┘
총: 19초인사이트
- Phase 1: LLM 63초 → 7초 (가장 긴 페이지만큼만 소요)
- Phase 2: OCR 36초 → 병렬 처리로 LLM과 동시 실행
- 두 병목을 모두 제거 → 6배 개선
Phase 3: LLM 파싱 일관성 개선 (변동폭 34% → 13%)
문제 발견
똑같은 PDF를 여러 번 업로드하면 매번 다른 개수의 메뉴가 생성되었습니다.
메가커피_5p 테스트:
1회: 70개 메뉴
2회: 74개 메뉴
3회: 94개 메뉴 ← 왜 이렇게 다를까?원인 분석
Temperature란 LLM이 다음 단어를 선택할 때의 무작위성 정도입니다.
temperature=0.0: 항상 가장 확률 높은 답변 선택 (결정적)temperature=0.7(기본값): 확률적으로 다양한 답변 (창의적)temperature=2.0: 매우 무작위 (극도로 창의적)
기존 코드:
llm = ChatOpenAI(model="gpt-3.5-turbo") # temperature 기본값 0.7해결책 1: Temperature 0으로 설정
llm = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0.0 # 일관된 결과
)해결책 2: 프롬프트 규칙 명확화
prompt = f"""
다음 레시피 텍스트에서 메뉴를 추출하세요.
중요 규칙:
1. 각 메뉴는 정확히 한 번만 포함하세요 (중복 제거)
2. "아이스"와 "핫"은 별도 메뉴로 분리하지 마세요
(예: "아이스 아메리카노", "핫 아메리카노" → "아메리카노" 하나로)
3. 사이즈 차이(Tall, Grande, Venti)는 별도 메뉴로 분리하지 마세요
4. 명확하게 구분되는 메뉴만 추출하세요
5. 모든 내용은 한국어여야 합니다
레시피 텍스트:
{recipe_text}
"""결과
| 지표 | Before | After | 개선 |
|---|---|---|---|
| 변동폭 | ±34% | ±13% | 2.6배 개선 ⚡ |
| 메뉴 일관성 | 낮음 | 중간-높음 | 향상 |
Phase 4: 스트리밍으로 UX 개선 (체감 시간 10배 개선)
문제 재정의
성능을 19초로 줄였지만, 여전히 문제가 있었습니다.
- 사용자는 19초 동안 아무것도 볼 수 없음
- "이거 작동하는 건가?" 의심하며 앱 종료
해결책: 실시간 병렬 스트리밍
전체 아키텍처
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Mobile │ SSE │ Express │ SSE │ FastAPI │
│ React Native│ ◄─────► │ Server │ ◄─────► │ (Python) │
│ │ │ (Node.js) │ │ │
└─────────────┘ └─────────────┘ └─────────────┘
│ │ │
│ │ │
└──── FormData ────────►│ │
│ │
├─── S3 Upload ─────────►│
│ │
│ ├── PDF → Images
│ │
│ ├── OCR (병렬)
│ │
│◄── data: ocr_start ────┤
│ │
│◄── data: progress ─────┤ (페이지별)
│ │
├── DB 저장 (메뉴/재료) │
│ │
│◄── data: complete ─────┤
│
├── recipe_created ─────►│
│
└── data: progress ─────►│ Mobile
사용자는 실시간으로 메뉴가 추가되는 것을 확인핵심 기술
asyncio.as_completed: 완료되는 순서대로 결과 처리- 버퍼링: 페이지 3이 먼저 완료되면 버퍼에 저장, 1→2 완료 시 1→2→3 순서대로 전송
- Server-Sent Events (SSE): 서버→클라이언트 단방향 실시간 통신
핵심 구현 포인트
XMLHttpRequest.onprogress: 스트리밍 데이터를 실시간으로 받음- 청크 버퍼링: 불완전한 줄을 버퍼에 보관 후 다음 청크와 합쳐서 파싱
- 점진적 파싱:
processedResponseLength로 이미 처리한 부분 추적 - React Native는 EventSource를 지원하지 않아 XMLHttpRequest 사용
스트리밍 전략 비교
3가지 전략 테스트 (빽다방 9페이지 기준)
| 모드 | 첫 결과 | 전체 시간 | UX 평가 |
|---|---|---|---|
| 병렬 처리 (기존) | 18.97초 | 18.97초 | ⭐⭐⭐ |
| 순차 스트리밍 | 12.72초 ⚡ | 47.70초 | ⭐⭐⭐⭐⭐ |
| 병렬 스트리밍 | 16.73초 | 17.04초 ⚡ | ⭐⭐⭐⭐ |
최종 선택: 병렬 스트리밍
선택 이유
- 빠른 전체 시간 (17초)
- 첫 결과가 순차보다 약간 느리지만(17초 vs 13초) 실용적 범위
- 진행률 표시로 답답함 해소 가능
- 순서 보장 가능:
asyncio.as_completed+ 버퍼링으로 1→2→3 순서 유지
구현 핵심 - 버퍼링 알고리즘
# 완료되는 순서대로 받되, 순서대로 전송
buffer = {} # 완료됐지만 아직 전송 못한 페이지들
next_page_to_send = 1 # 다음에 전송해야 할 페이지 번호
for coro in asyncio.as_completed(tasks):
result = await coro # 페이지 3이 먼저 완료될 수 있음
buffer[result['index']] = result # 버퍼에 저장
# 순서대로 전송 가능한 것들 모두 전송
# 예: 1,3이 완료 → 1만 전송, 3은 대기
# 2 완료 → 2,3 연속 전송
while next_page_to_send in buffer:
send_result(buffer.pop(next_page_to_send))
next_page_to_send += 1동작 시나리오
시간 0초: 페이지 1,2,3 병렬 처리 시작
시간 5초: 페이지 3 완료 → buffer[3] 저장, 전송 보류 (1이 없음)
시간 7초: 페이지 1 완료 → 즉시 전송, next=2
시간 9초: 페이지 2 완료 → 2 전송 후 buffer의 3도 연속 전송왜 WebSocket이 아닌 SSE를 선택했나?
| 기준 | WebSocket | SSE | 선택 이유 |
|---|---|---|---|
| 통신 방향 | 양방향 | 단방향 (서버→클라이언트) | 메뉴 생성은 단방향만 필요 |
| 구현 복잡도 | 높음 | 낮음 | 간단한 구현으로 빠른 개발 |
| 프로토콜 | WS:// | HTTP/HTTPS | 기존 인프라 활용 가능 |
| 재연결 | 수동 구현 | 자동 재연결 | 네트워크 안정성 향상 |
| 오버헤드 | 작음 | 약간 큼 | 메뉴 생성은 실시간성 덜 중요 |
추가 최적화: 진행률 UI 표시 (답답함 해소 위함)
최종 결과
성능 지표
실제 측정 결과 (빽다방 9페이지 기준)
| 단계 | 처리 시간 | 첫 결과 | 개선율 | 사용자 체감 |
|---|---|---|---|---|
| 초기 (순차 처리) | 111초 (약 2분) | 111초 | - | 😫 |
| Phase 1 (LLM 병렬) | 52초 | 52초 | 53% ↑ | 😐 |
| Phase 2 (OCR 병렬) | 19초 | 19초 | 83% ↑ | 🙂 |
| Phase 3 (일관성) | 17초 | 17초 | 85% ↑ | 😊 |
| Phase 4 (순차 스트리밍) | 47초 | 9초 ⚡ | 92% ↑ | 🎉 |
| Phase 4 (병렬 스트리밍) | 17초 ⚡ | 17초 | 85% ↑ | 🎉 |
핵심 지표
- 전체 처리 시간: 111초 → 17초 (85% 개선, 6.5배 빨라짐)
- 첫 결과 시간: 111초 → 9초 (순차 스트리밍), 17초 (병렬 스트리밍)
- 사용자 체감: "2분 기다림" → "9초에 결과 확인" (12배 개선)
화면 비교
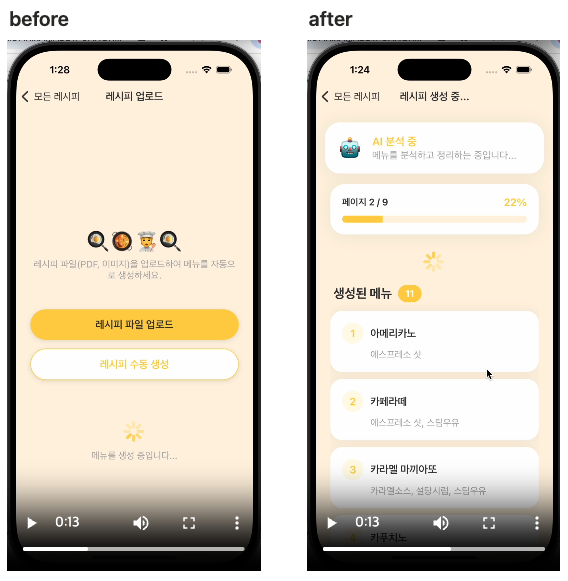
Before (컴포즈 9p)
- 로딩 시작 → 아무 반응 없음 → 111초(약 2분) 후 모든 메뉴 한번에 표시
- 사용자: "이거 먹통인가?" → 앱 종료
After (컴포즈 9p)
- 로딩 시작 → 9초 후 첫 메뉴 표시 → 실시간으로 메뉴 추가 → 17초 완료
- 사용자: "오 작동하네!" → 계속 사용
교훈
1. 성능과 실험의 균형을 맞추자
이전 생각 1 (조금 극단적)
1. 핵심 기능 성능 구림. 로딩 시간 2분 걸림
2. 그래도 기능 working하니까 리텐션 나오겠지?
3. 홍보해서 알아보자이전 생각 2 (극단적)
1. 핵심 기능 성능 완벽 최적화
2. 액티베이션, UX 완벽 최적화
3. 그 다음에 홍보 ← 시간 낭비깨달은 것 (균형)
1. 핵심 기능이 "쓸만한 수준"이 되면
2. 소규모로 빠르게 실험
3. 결과 보고 개선 방향 결정
4. 개선 후 재실험원칙
- "일단 만들고 바로 홍보" → 성능 때문에 리텐션 안 나옴
- "완벽한 최적화 후 실험" → 시간 낭비, 방향 틀릴 수 있음
- "적절한 수준에서 실험, 결과 보고 개선" → 빠른 학습
적절한 수준이란?
- 핵심 기능이 작동은 함 (2분 걸려도 메뉴는 생성됨)
- 사용자가 기다릴 만한 시간 (2분은 너무 길어서 개선 필요)
- 최소한의 UX 갖춤 (로딩 표시 정도는 있어야)
실제 적용한 방법
첫 실험 (v1):
- 성능: 2분 소요
- 예산: 5,000원 × 3일
- 결과: 리텐션 안 나옴
- 학습: "일단 성능 문제를 개선해야 근본 문제를 알아볼 수 있겠다"
개선 후 재실험 (v2):
- 성능: 17초 + 실시간 피드백
- 예산: 다시 소규모
- 목표: 리텐션 30% 검증2. 병렬 처리는 만능이 아니다
배운 점
- 단일 작업: 병렬 처리 오히려 느림 (오버헤드)
- 다중 작업 (5개 이상): 병렬 처리 압도적 (2~4배 개선)
- 작업 크기에 따라 전략을 다르게!
실제 구현
# 단일 페이지는 순차 처리
if len(recipe_text_list) == 1:
return await generate_menus_from_text(recipe_text_list[0])
# 다중 페이지는 병렬 처리
tasks = [generate_menus_from_text(text) for text in recipe_text_list]
return await asyncio.gather(*tasks)3. UX는 실제 성능보다 체감 성능이 중요하다
깨달음
- 실제 시간: 47초 (순차 스트리밍) vs 17초 (병렬 스트리밍)
- 사용자 체감: "12초에 결과 나옴!" vs "17초 기다림"
해결책
- 병렬 스트리밍 (17초) + 진행률 UI
- 실제 성능 + 체감 성능 모두 개선
결론
처음에는 "성능 많이 안좋아도 기능 돌아가니 실험해보자", 아니면 "완벽하게 최적화한 후 실험해보자"고 생각했지만, 기능이 working한다는 전제하에 균형을 맞춰나가야겠다는 생각으로 변화했습니다.
- 핵심 기능이 쓸만한 수준이 되면
- 소규모로 빠르게 실험하고
- 데이터를 근거로 근본 문제를 파악하고
- 개선 후 재실험하는 방식입니다.
만약 첫 실험을 하지 않았다면 "2분이면 괜찮겠지"하면서 혼자 착각하고 6개월 동안 엉뚱한 기능을 개발했을 수도 있을 것 같아요.
결국 약 2분짜리 로딩을 17초로 줄여서 병목을 해소했지만, 아직 근본 문제에 닿지 않았다고 생각합니다.
이제 막 발견한 문제를 해소했으니 다시 소규모 예산으로 실험해보고
만약에 그래도 리텐션이 안 생긴다 싶으면 두 가지 방법 중 하나를 선택할 계획입니다.
- 액티베이션 최적화하기
- 새로운 기능 생각하기 → 기존 기능의 기본체력이 안 좋다고 판단
이 경험이 같은 고민을 하는 분들께 도움이 되길 바랍니다!
결과 3줄 요약
- 전체 시간: 2분 → 17초 (85% 개선) - OCR, LLM 파싱 병렬 처리
- 첫 결과: 2분 → 9초 (92% 개선) - 병렬 스트리밍
- 핵심: 완벽한 최적화보다 균형을 맞춰 빠른 실험-학습 사이클을 돌리자
레시피 암기 앱은 현재 100% 무료로 이용 가능!
👉 iOS 앱 다운로드


잘 보고 갑니다 !