1. 해시 테이블이란?
-
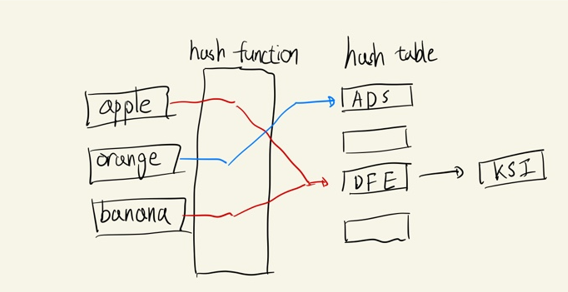
해시 테이블이란 키를 해시 함수를 이용해 연산함으로써 고정된 길이의 결과값을 얻을 수 있고 이 결과값을 이용하여 키와 값을 매핑할 수 있는 형태의 자료구조이다.
-
이처럼 해시 함수를 이용해 키와 값을 매핑하는 것을 해싱이라 하며 해싱은 정보를 빠르게 저장하고 검색하기 위해 사용되는 중요한 기법이다.
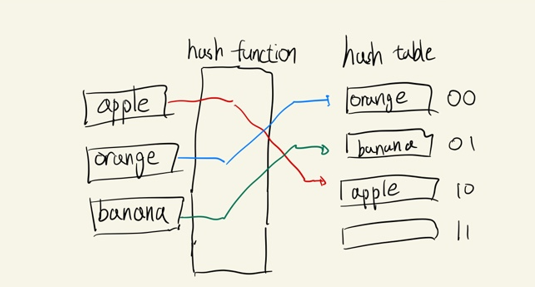
- apple -> 10
orange -> 00
banana -> 01
이처럼 key값을 넣었을 때 고정된 길이의 해시된 값을 얻고 해당 값을 이용해 데이터를 저장하고 검색한다.
2. 해시 값이 충돌할 경우
-
충돌
서로 다른 값의 키를 계산했을 때 같은 결과의 해시값이 나오는 경우를 충돌했다고 표현한다.
그렇다면 충돌이 발생할 확률은 얼마나될까?
충돌에 대해 설명할 때 자주 사용하는 예로 생일 문제를 들 수 있다. -
생일 문제
1년은 365일로 사람이 가질 수 있는 생일은 365가지나 된다.
그렇다면 같은 생일을 가진 사람이 존재하려면 몇 명의 사람이 필요할까? 100명? 200명?
보통 못해도 100명 이상은 되어야 같은 생일을 가진 사람이 존재할 것이라고 생각한다.
하지만 23명만 모이더라도 같은 생일을 가진 사람이 존재할 확률이 50%를 넘는다고 한다.
또한, 57명이 넘는 경우 99%를 넘어선다.
이것을 해시에 대입해보면 해시를 통해 나올 수 있는 결과값이 365개가 존재한다면 23개의 데이터를 넣었을 경우 충돌이 발생할 확률이 50%이상이고 57개의 데이터를 입력한다면 거의 100%의 확률로 충돌이 발생한다고 볼 수 있다. -
충돌이 날 경우
그렇다면 충돌이 발생할 경우 어떻게 어떻게 대처할 것인가?
해시 테이블에서 충돌의 해결법은 크게 2가지로 볼 수 있다.
chaining과 open addressing 방식이다.
2-1. chaining
- 먼저 chaining 방식은 충돌이 발생한 데이터를 linked list 자료구조로 만들어 저장하는 방식이다.
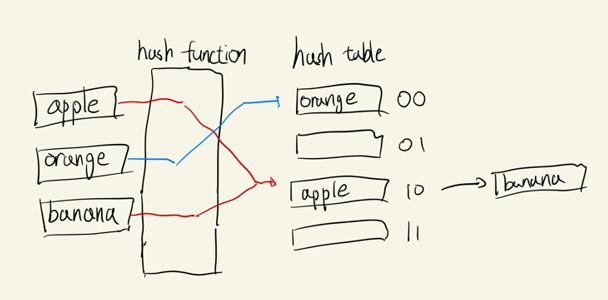
- apple과 banana가 충돌이 발생하여 해시 테이블(10)에서 링크드 리스트로 banana를 저장한다.
2-2. open addressing
- 충돌이 일어날 경우 hash table의 비어있는 공간에 값을 저장하는 방식이다.
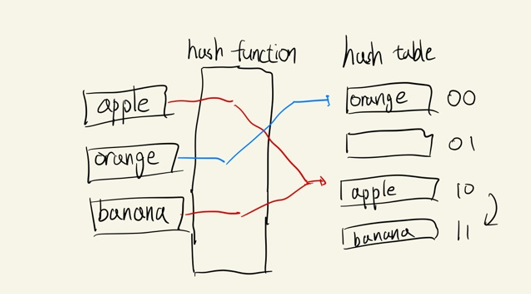
- apple과 banana가 충돌이 발생하여 해시 테이블에서 비어있는 공간을 확인한 뒤 해당 공간(11)에 banana를 저장한다.
3. hash table[python]
-
백준 1920번 수찾기 문제를 통해 해시 테이블이란 무엇인지 알아보자
1920번 문제는 4번째 줄에 입력으로 들어오는 값들이 2번째 줄에 입력으로 받은 값들 사이에 포함되어 있는지 확인하고 포함되어 있다면 1을 없다면 0을 출력하는 프로그램이다. -
초기 제출코드
다음 코드를 백준에 제출하면 문제없이 동작한다.
하지만 걸린 시간이 4000ms를 넘어갈 정도로 오래 걸리는 것을 확인할 수 있다.
# 정수 A의 개수 n 입력
n = int(input())
# 정수 A 입력
a = list(map(int,input().split(" ")))
# A안에 존재하는지 확인할 정수의 개수
m = int(input())
# 확인할 정수 입력
values = list(map(int, input().split(" ")))
# list의 정수를 하나씩 a에 존재하는지 확인
# 존재한다면 1 존재하지 않는다면 0을 출력
for v in values:
if v in a:
print('1')
else:
print('0')- hash table을 이용한 코드
위에서 사용한 코드와 동작하는 방식은 유사하지만 걸린 시간이 200ms로 크게 줄어들었다.
하지만 다음 코드에서 2번째 줄의 입력값을 받는 자료형이 list에서 set으로 바뀐 것을 확인할 수 있다.
여기서 사용한 set이 hash table이다.
python에서 기본 자료형인 set은 hash table로 만들어진 자료형으로 기존 list에선 list안에 해당 숫자가 포함되어 있는지 확인하기 위해서는 list안의 값을 하나씩 비교하여 같은 값이 있는지 확인하는 방법으로 시간 복잡도가 O(n)의 시간이 걸린다.
하지만 set 자료형을 사용함으로써 입력받은 key값을 해시하여 값에 바로 접근하기 때문에 O(1)의 시간 복잡도를 가지게된 것이다.
# 정수 A의 개수 n 입력
n = int(input())
# 정수 A 입력
a = set(map(int,input().split(" ")))
# A안에 존재하는지 확인할 정수의 개수
m = int(input())
# 확인할 정수 입력
values = list(map(int, input().split(" ")))
# list의 정수를 하나씩 a에 존재하는지 확인
# 존재한다면 1 존재하지 않는다면 0을 출력
for v in values:
if v in a:
print('1')
else:
print('0')- 문제에서 입력값이 많지 않기 때문에 20배 정도의 속도차이가 나지만 만약 입력값의 수가 증가한다면 그에 따라 속도의 차이는 더 벌어지게 되어있다.
