1. 문제
2. 입출력
3. 문제 풀이
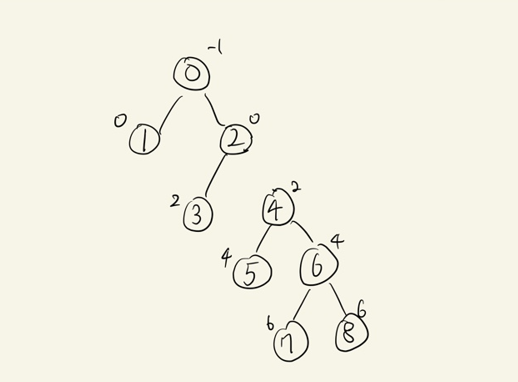
트리 구성 예시
- 9
-1 0 0 2 2 4 4 6 6
4
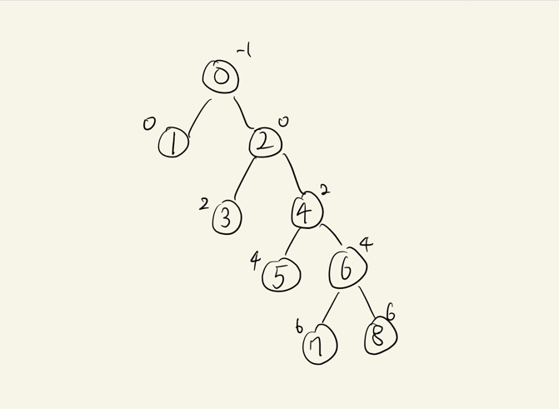
부모의 값과 자식(index)를 매핑해서 트리 구성(dictionary)
-
dictionary를 사용한 트리 구성
-1:[0]
0:[1,2]
2:[3,4]
4:[5,6]
6:[7,8] -
dictionary 사용 이유
굳이 Tree구조를 만들고 탐색할 필요가 없음
list를 사용할 경우 입력받은 노드의 수(n)만큼의 2차원 배열을 생성해줘야함
방법 1
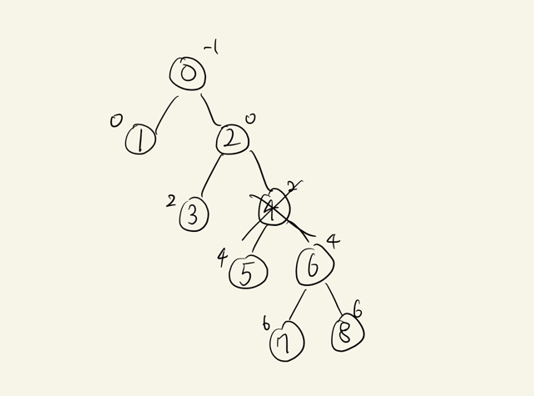
- 노드 제거
import sys
input = sys.stdin.readline
from collections import defaultdict
# 입력값을 저장하고 트리를 구성할 defaultdict 생성
n = int(input())
li = list(map(int,input().split()))
m = int(input())
d = defaultdict(list)
# 입력값들로 dictionary를 이용한 트리 생성
for i in range(n):
d[li[i]].append(i)- dictionary(d)의 값
-1:[0]
0:[1,2]
2:[3,4]
4:[5,6]
6:[7,8]
def dfs(index):
# default로 list를 선언했기 때문에 자식으로 빈 배열을 가지고 있는 노드가 리프
if d[index] == []:
return 1
# 해당 노드까지의 리프 갯수(num)
num = 0
for i in d[index]:
# 탐색할 노드가 삭제할 노드라면 탐색을 진행하지 않는다.
if i==m:
# 자식 노드가 삭제할 노드뿐이라면 리프이기 때문에 1을 반환한다.
if len(d[index])==1:
return 1
continue
num += dfs(i)
return num
- 조건
리프 노드라면 1을 반환한다.
자식 노드가 있다면 자식 노드의 리프 노드의 수를 구해 반환한다.
자식 노드 중 삭제할 노드가 있다면 해당 노드를 제외하고 진행한다.
(자식 노드를 제거했을 때 해당노드의 자식이 없다면 리프노드가 되고 1을 반환한다.)
방법 2
- 간선 제거
import sys
input = sys.stdin.readline
from collections import defaultdict
# 입력값을 저장하고 트리를 구성할 defaultdict 생성
n = int(input())
li = list(map(int,input().split()))
m = int(input())
d = defaultdict(list)
# 입력값들로 dictionary를 이용한 트리 생성
# 삭제하게될 노드와의 간선 절단
for i in range(n):
if i == m:
continue
d[li[i]].append(i)- dictionary(d)의 값
-1:[0]
0:[1,2]
2:[3]
4:[5,6]
6:[7,8]
def dfs(index):
# default로 list를 선언했기 때문에 자식으로 빈 배열을 가지고 있는 노드가 리프
if d[index] == []:
return 1
# 해당 노드까지의 리프 갯수(num)
num = 0
for i in d[index]:
num += dfs(i)
return num- 조건
리프 노드라면 1을 반환한다.
자식 노드가 있다면 자식 노드의 리프 노드의 수를 구해 반환한다.
실행 및 결과 출력
print(dfs(-1))예외 처리
- 설마 루트를 주지 않는 예제가 있을거란 생각을 못했습니다.
if d[-1]==[]:
print(0)
else:
print(dfs(-1))결과(성공)
import sys
input = sys.stdin.readline
from collections import defaultdict
n = int(input())
li = list(map(int,input().split()))
m = int(input())
d = defaultdict(list)
for i in range(n):
if i == m:
continue
d[li[i]].append(i)
def dfs(index):
if d[index] == []:
return 1
num = 0
for i in d[index]:
num += dfs(i)
return num
if d[-1]==[]:
print(0)
else:
print(dfs(-1))시간 복잡도 - O(n)
dictionary를 이용한 트리 구성 - O(n)
dfs 함수를 이용한 리프 노드 탐색 - O(n)

개발자