
본 시리즈는 팀 내 작디 작은 세미나에서 발표했던 내용으로 이루어져 있습니다.
우아한 테코톡의 던님의 영상과 Aaron Yoo 유튜버의 영상 내용을 주로 참고했습니다!
오류가 있다면 댓글로 남겨주시면 감사하겠습니다!

오늘 제가 이야기해 볼 주제는 가비지 컬렉터 입니다. 개발일을 하면서 가비지 컬렉터에 대해 많이 들어보셨을 거고, 대충 어떤 일을 하는 애 인지 알고 계실거에요. 가비지 컬렉터는 쉽게 말해 메모리에 굳이 남아있을 필요없는 쓰레기들을 주워가는 쓰레기 콜렉터죠. 우리가 쓰는 언어들 대부분 가비지 컬렉터가 구현되어 있어서 굳이 이걸 왜 알아야할까 싶기도 합니다. 우리가 가비지 컬렉터를 알아야 하는 이유는 명확합니다.가비지 컬렉터의 작동 방식을 이해하면 메모리 누수나 성능 저하, 오버플로우와 같은 문제를 미리 예방할 수 있기 때문입니다.

메모리 관리에 소홀하게 되면 정말 크나큰 문제가 생기기도 하는데, 극단적인 사례가 하나있습니다. 1996년 '아리안 5'라는 로켓 하나가 폭발하게 됩니다. 유럽도 인간을 우주에 보낼 수 있다는 꿈을 안고 프랑스를 주축으로 유럽 12개국이 약 6조 7천억 원을 투자해 로켓하나를 쏩니다. 하지만 40초도 안돼서 꿈이 산산조각 나버리게 됩니다. 손해액과 자존심에 금이 간 것에 비해서 원인은 참 간단했습니다. 프로그래머들이 아리안 4호 코드를 복붙했기 때문인데요, 당시 학자들은 아리안 4호의 속도가 16비트 정수형의 최댓값(32,767)을 넘지못할 것이라고 예측하고 코드를 작성했는데 아리안 5호에도 똑같은 코드를 복붙해버렸죠. 이 값은 로켓의 방향제어 시스템에서 사용되었는데, 이렇게 저장한 값이 너무 크게 되어버려서 오버플로우가 났고, 결과적으로 로켓은 날아가다가 폭발해버렸습니다.
이 사건의 문제는 우리에게 다양한 가르침을 주죠. 그 중 하나의 큰 깨달음은 개발자 자신이 작성한 코드가 메모리를 어떻게 사용하는지 정확히 이해하고 있어야 한다는거죠. 메모리 해제를 철저하게 수행하면 시스템의 안정성을 확보할 수 있고, 이를 통해 이런 심각한 사고를 방지할 수도 있겠죠. 따라서 가비지 컬렉터의 방식을 이해하고 적절히 활용할 수 있어야합니다.
이 가비지 컬렉터가 어디에 존재하는지부터 살펴보도록 하겠습니다. 우리가 쓰고 있는 대부분의 언어는 매니지드 언어라고 불리죠. 흔히 매니지드 언어, 매니지드 코드라고 하는 건 쉽게 말해 언어에 런타임 환경이 더해진 언어인데요. 언매니지드 언어는 하드웨어에서 직접 실행될 수 있지만 매니지드 언어는 런타임 환경에 의존적인 코드입니다.

런타임 환경은 개발자를 위해 많은 서비스를 제공해주는데, 이 중 가장 대표적인 것이 가비지 콜렉션 입니다.
가비지가 수집되는 과정은 두가지 쓰레드로 나눠볼 수가 있습니다. 하나는 뮤테이터고 하나는 콜렉터입니다.

뮤테이터는 객체를 할당하고 참조에 따라 그래프를 변형시키는 역할을 합니다. 즉 쉽게말해 뮤테이터는 우리가 작성하는 코드 그 자체라고 할 수 있습니다. 따라서 우리가 작성하는 코드이기 때문에 참조되고 변화하는 이 과정은 잘 이해하고 있죠. 이 콜렉터는 뮤테이터 쓰레드에서 접근할 수 없는 쓰레기 메모리가 된 것들을 찾아 저장공간을 회수하는 역할을 합니다. 실질적인 가비지 컬렉터라고 할 수 있는 해당 쓰레드 과정의 알고리즘은 정확히 알기가 어렵죠.
그래서 오늘은 이 콜렉터 쓰레드에서 일어나는 대표적인 알고리즘을 세가지인 레퍼런스 카운팅, 마크앤 스윕, 제너레이션 가비지 컬렉션에 대해 알아보고, 각 언어들이 어떤 방식을 채택하고 있는지, 어떤 장단점이 있는지 알아보는 시간을 갖도록 하겠습니다.

레퍼런스 카운팅은 Garbage의 Detection, 즉 쓰레기를 찾는 것에 초점이 맞추어진 초기 Algorithm입니다. 각 Object마다 Reference Count를 관리하여 Reference Count가 0이 되면 GC를 수행하죠.
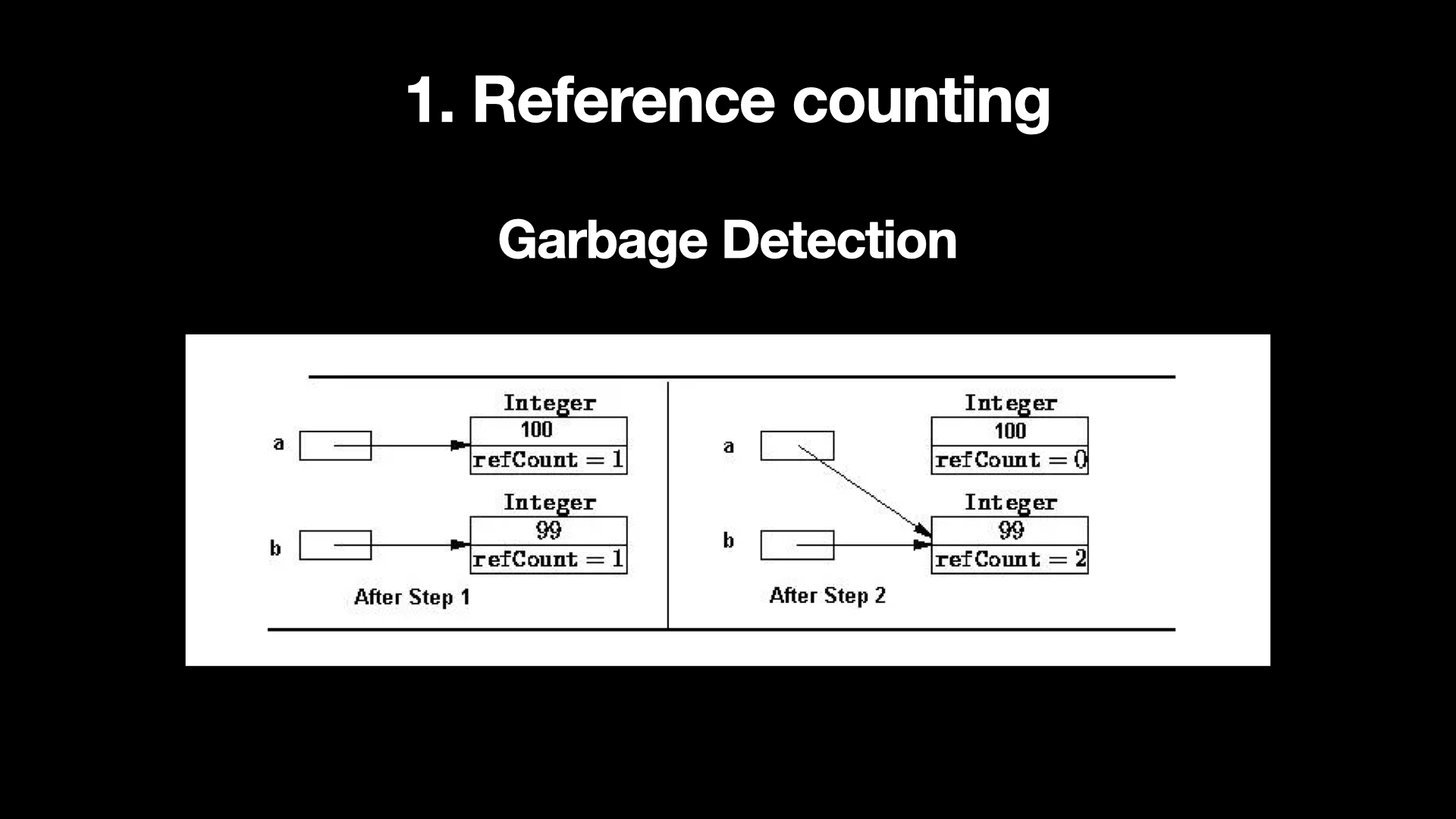
이 그림에서 a와 b는 각각 100, 99의 값을 갖는 Integer Object로 선언되어 있는데요, 각 Integer Object는 Referece Count가 1로 설정되어 있습니다. 이 상태에서 a=b 로 변경하게 되면 a가 참조하고 있던 100의 값을 갖는 Integer Object는 참조가 없어지기 때문에 Reference Count가 0으로 감소하게 되고 GC가 수행됩니다.
이 단순한 방식은 Reference Count가 0이 될 때마다 GC가 발생하기 때문에 시간 작업에도 거의 영향을 주지 않고 즉시 메모리에서 해제된다는 장점이 있으나 각 Object마다 Reference Count를 변경해 주어야 하고 참조를 많이 하고 있는 Object의 Reference Count가 0이 될 경우 연쇄적으로 GC가 발생할 수 있는 문제가 있고 Reference Count의 관리 비용도 큽니다.
또한 대표적인 문제는 Linked List와 같은 순환 참조 구조에서 Memory Leak이 발생할 가능성도 크다는 것입니다. 이러한 이유로, 레퍼런스 카운팅 방식만으로는 모든 경우에 대응하기 어렵습니다. 따라서 다른 가비지 컬렉션 방식들이 필요하게 되었습니다.

Reference Counting Algorithm의 단점을 극복하기 위해 나온 Algorithm으로 대표적인건 마크앤 스윕 방식입니다. 이 방식은 Root에서 시작해 참조의 관계를 추적해나갑니다. 그래서 Tracing Algorithm이라고도 하구요 이름에서 유추할 수 있듯이 Mark Phase와 Sweep Phase로 나뉘게 됩니다. 이 알고리즘은 죽은 객체와 산 객체의 판단을 힙 영역이 아닌 객체로 부터 닿을 수 있는가로 판단하게 됩니다.
다시 말해서, 힙이 아닌 영역에서 참조를 하고 있으면 해당 객체는 산 객체, 힙이 아닌 영역에서 부터 닿을 수 없는 애는 죽은 애로 판단합니다. 이 논힙 영역을 루트라고 부르며 이 루트는 실행중인 쓰레드가 될 수 있고, 전역 변수, 정적변수 로컬변수 등이 있습니다. 마크단계에서는 이 루트에서 시작하여 접근 가능한 모든 객체를 탐색하며 사용 중인 객체에 마크를 표시합니다.
그 다음, '스윕' 단계에서는 마크되지 않은 객체를 해제합니다. 이렇게 하면, 사용 중인 객체가 아닌 객체는 자동으로 해제되어 메모리를 확보할 수 있습니다. 이 마크앤 스윕 알고리즘을 코드로 표현하면 다음과 같습니다.

마크 단계에서 도달할 수 있는 객체들을 넣어두는 곳을 이 파란 worklist라고 하고
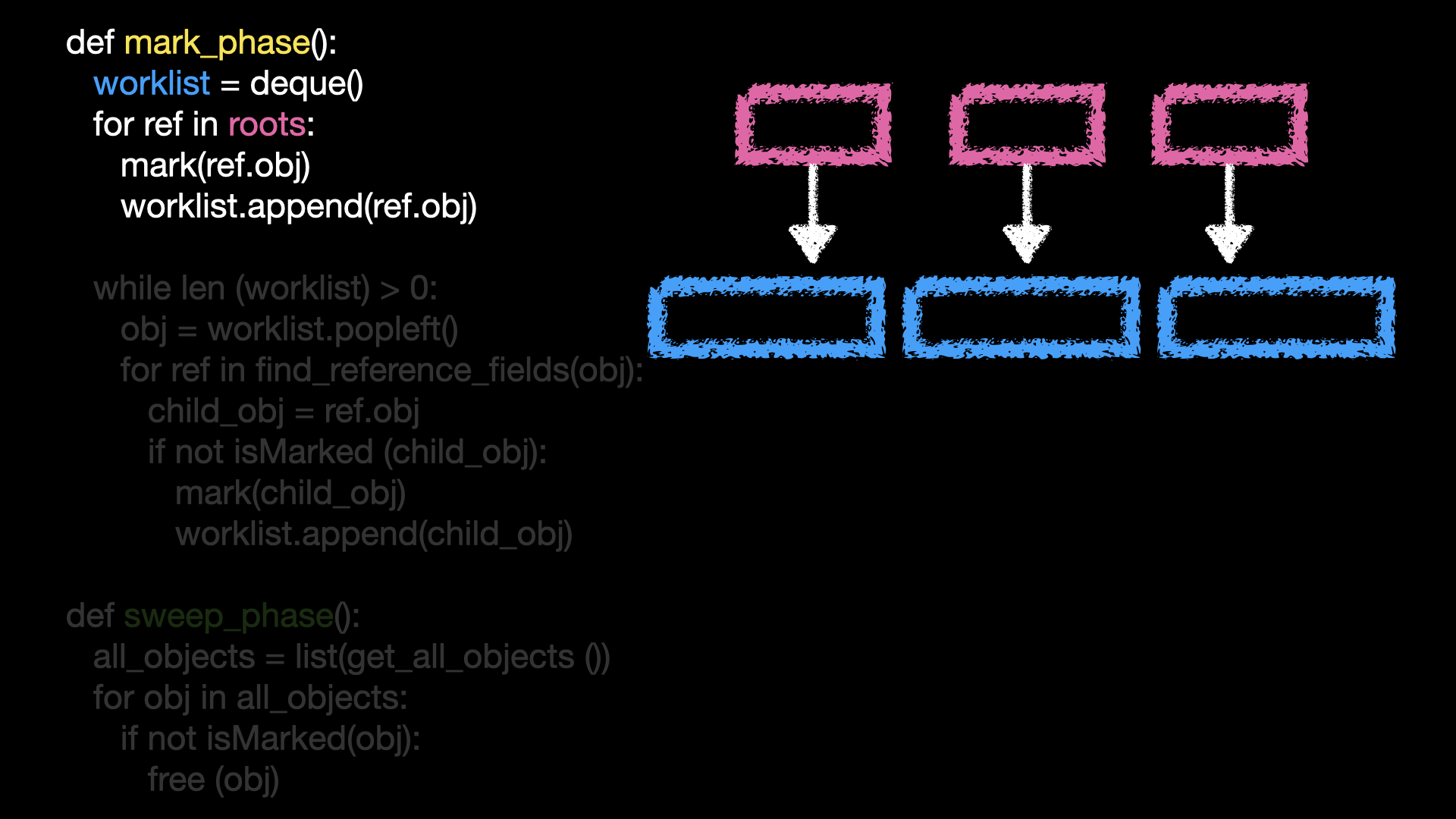
루트를 돌면서 도달할 수 있는 객체들에 마크를 하고 worklist에 넣습니다. 이 분홍색 roots의 정보들은 가비지 컬렉터가 가지고 있습니다.
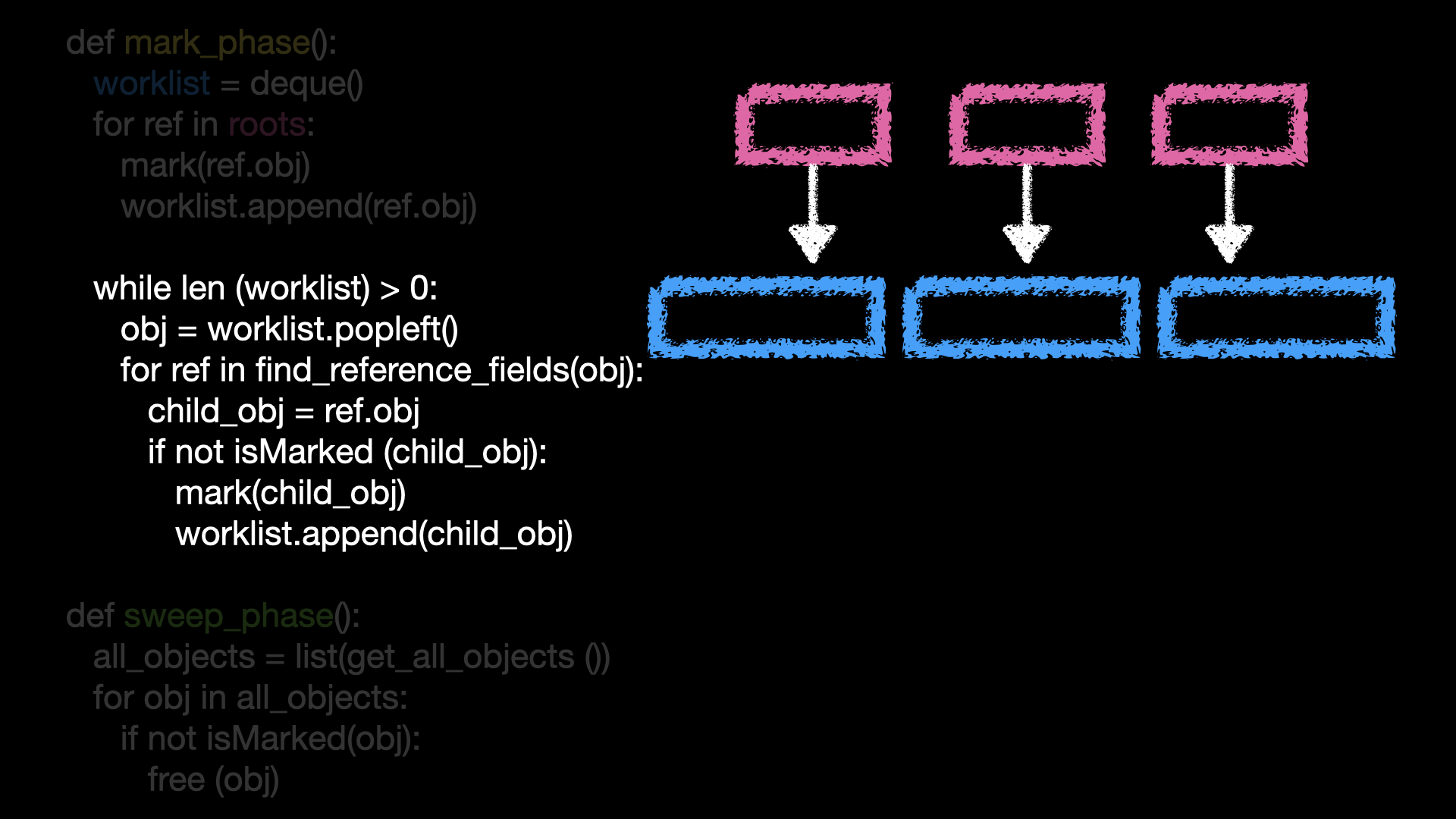
그 다음으로는 워크 리스트를 하나씩 돌며 여기서는 obj에 해당하겠죠
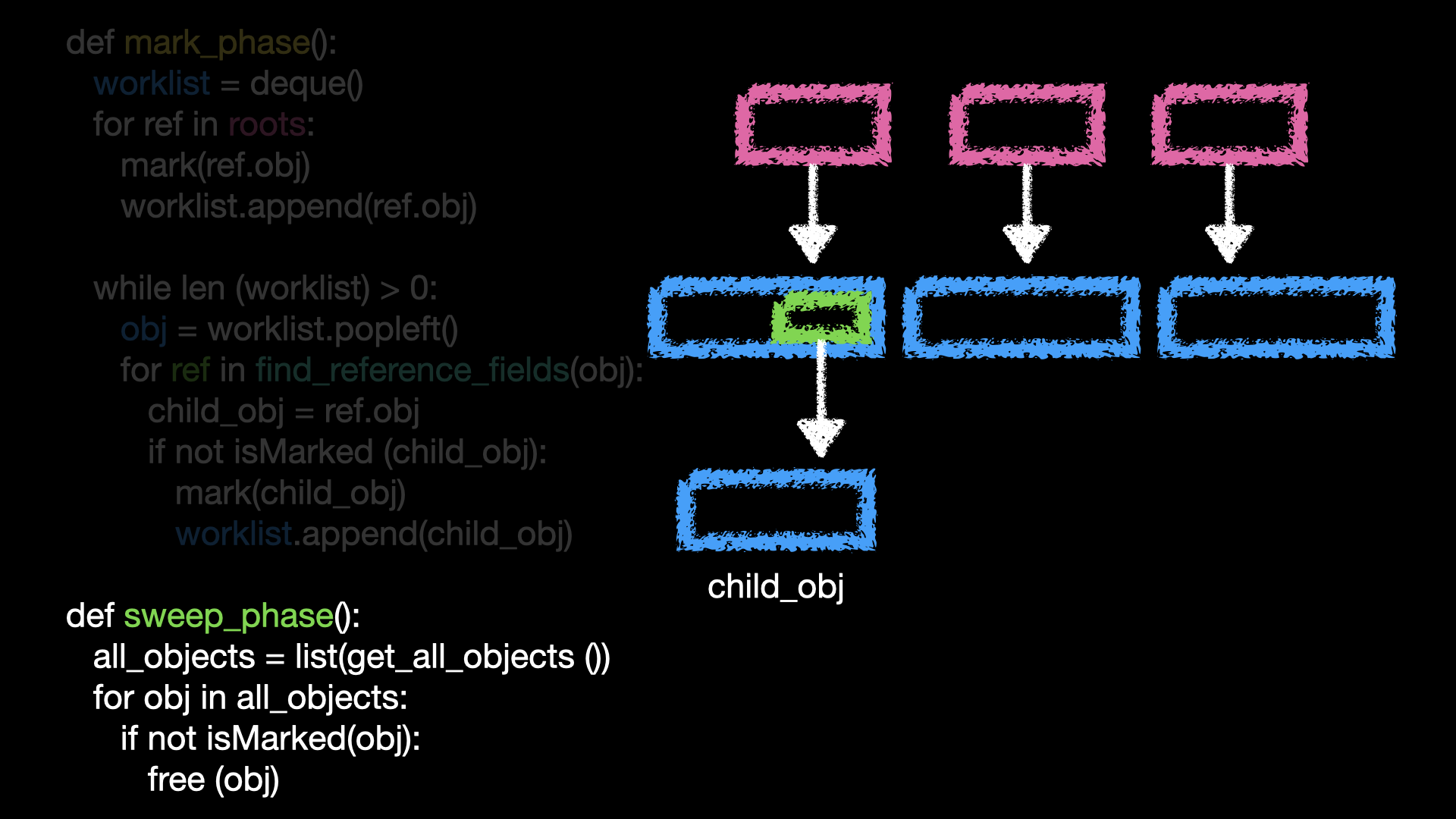
해당 객체가 참조하는 것이 있는지, 해당 객체에 참조 공간이 있는지 확인해주고 있다면,
해당 객체가 참조하는 객체 또한 도달가능한 객체이기 때문에 마크를 해주고 워크리스트에 넣어줍니다.
마지막으로 스윕단계에서는 워크리스트에 해당하지 않는, 닿을 수 없는 객체들을 free를 통해 해제시켜줍니다.
마크 앤 스윕 방식은 레퍼런스 카운팅 방식보다 강력합니다. 레퍼런스 카운팅 방식에서는 순환 참조 문제를 해결하지 못하는데, 마크 앤 스윕 방식은 순환 참조 문제도 해결할 수 있습니다. 하지만 큰 단점으로는 마크 앤 스윕 방식은 메모리 해제를 위해 일시적으로 프로그램 실행을 중지해야 하는 'Stop the World' 상황이 발생할 수 있다는 것입니다.

현재 뮤테이터 스레드가 멈추어야 현재 메모리에서 살아있는 객체를 잘 식별할 수 있기 때문입니다. 이것을 stop the world라고 합니다. 물론 마크앤스윕 방식 말고도 모든 가비지 컬렉션 알고리즘이 stop the world 상황이 발생합니다. stop the world 의 시간을 줄이기 위해 여러가지 알고리즘을 사용한 여러 종류의 가비지 컬렉션들이 개발되었습니다. 이건 추후 더 이야기를 하도록 하겠습니다. 결론적으로 이야기하자면, 마크앤 스윕 방식은 레퍼런스 카운팅의 단점을 보완해주지만 스탑더월드 상태를 야기시킨다 정도로 정리하면 될 것 같습니다.

다음은 세대별 가비지 컬렉션입니다. 메모리 내의 객체를 여러 세대로 분류하여, 각 세대마다 다른 가비지 컬렉션 알고리즘을 적용하는 방식입니다. 이 방식은 빈번한 객체 생성과 동시에 짧은 생명주기를 가진 객체가 많은 경우에 효과적입니다. 위클리 플러터 때 다트의 가비지 컬렉션에 대해 이야기할 때도 해당 알고리즘을 소개했었죠.
일반적으로, 영 제너레이션에서는. 복사 방식을 사용하고, 올드 제너레이션에서는 아까 설명드린 마크앤 스윕 방식을 채택해 사용합니다. 객체가 막 생성된 시점에는 첫 번째 세대(Young Generation)에 속합니다. 이 이유 기억나시나요? 대부분의 객체는 생성된 후 짧은 시간 동안만 유효하며 오랫동안 유효한 객체는 일부에 불과하다는 약한 세대 가설을 전제로 해당 gc알고리즘이 만들어졌기 때문에 일단 생성됐다? 하면 영 제너레이션으로 들어가는 것입니다.
Young Generation에서는 가비지 컬렉션이 빈번하게 발생하는 이유도 대부분의 객체가 짧은 생명 주기를 가진다는 전제 때문입니다. 가비지 컬렉션의 주요 기술 중 하나인 "복사(Copying)" 방식은 Young Generation을 두 영역으로 나눈 후, 객체를 한쪽에 할당하고, 그 공간이 가득 차면 살아있는 객체를 판단하고 나머지 영역으로 살아있는 객체를 이동시킵니다. 이렇게 이동하는 것을 반복하게 됩니다.

이 방식의 장점 중 하나는 메모리를 사용한 후, 쓰지 않는 객체들을 모아 한 번에 삭제할 수 있다는 것이고, 객체를 복사하는 과정에서 객체가 사용될 때마다 카운팅하는 레퍼런스 카운팅 방식보다 훨씬 간단하게 처리할 수 있다는 것입니다. 또한, 한 영역이 가득 찰 때마다 전체 객체를 검사하고 이동시키기 때문에 가비지 컬렉터가 언제 메모리를 회수할지 미리 알 수 있으므로, 전체적인 메모리 관리의 성능을 예측 가능합니다.

하지만 이 방식 역시 단점이 존재하는데요. 가장 큰 단점은 메모리 공간이 두 배로 필요하다는 것입니다. 또한, 객체가 복사되는 과정에서 영역이 이동하므로, 포인터가 가리키는 위치를 계속해서 업데이트해주어야 한다는 것입니다. 이는 다소 부하를 유발할 수 있습니다. 또한, 큰 객체가 복사될 때는 메모리 복사 시간이 길어질 수 있습니다.
일부 객체는 짧은 생명 주기를 가지지 않고, 오랫동안 살아남아야 할 필요가 있습니다. 이런 객체는 Old Generation으로 이동하게 됩니다. Old Generation에서는 Young Generation과는 달리, 가비지 컬렉션이 적게 발생합니다. 따라서, Old Generation에서는 'Mark and Sweep'이라는 알고리즘이 사용됩니다.객체가 Mark되면서 사용되고 있는지 여부를 확인하고, 사용되지 않는 객체는 Sweep하여 해제합니다. 해당 알고리즘은 뒤에 언어와 함께 더 자세히 어떻게 언어들에서 쓰이고 있는지 설명드리겠습니다.
참고한 글
https://luavis.me/python/dismissing-python-garbage-collection-at-instagram
https://medium.com/dmsfordsm/garbage-collection-in-python-777916fd3189
