자료구조는 프로그래밍의 기초입니다.
어떤 자료구조를 선택하느냐에 따라 코드의 성능이 크게 달라질 수 있습니다.
📌 들어가며
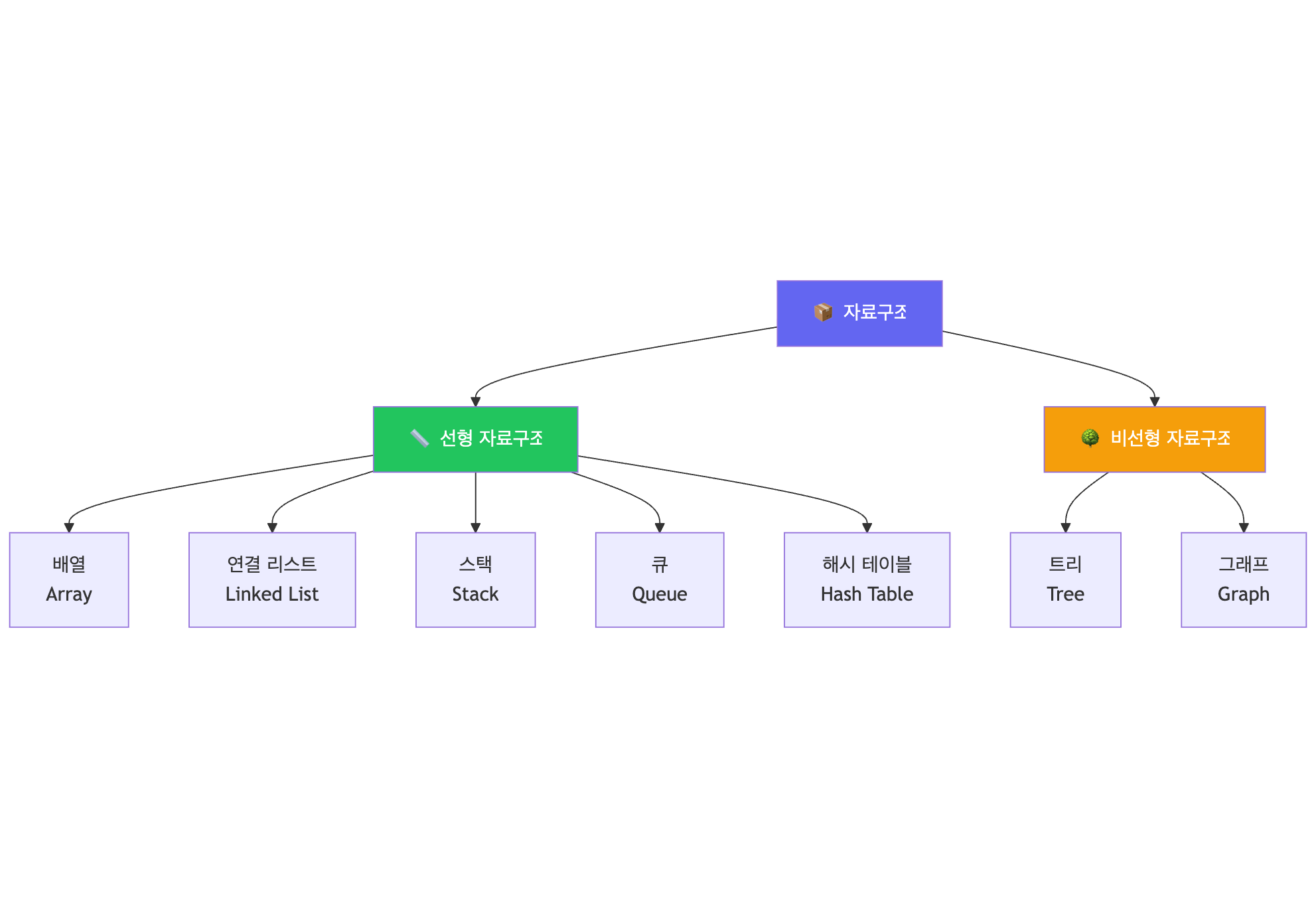
이번 포스팅에서는 개발할 때 반드시 알아야 할 7가지 핵심 자료구조를 다루고자 합니다:
- 배열 (Array)
- 연결 리스트 (Linked List)
- 스택 (Stack)
- 큐 (Queue)
- 해시 테이블 (Hash Table)
- 트리 (Tree)
- 그래프 (Graph)
각 자료구조의 작동 원리, Python/Java 코드 예시, 시간 복잡도, 장단점을 정리했습니다.
🗺️ 자료구조 전체 맵
1️⃣ 배열 (Array)
개념
배열은 연속된 메모리 공간에 같은 타입의 데이터를 순차적으로 저장하는 자료구조입니다.
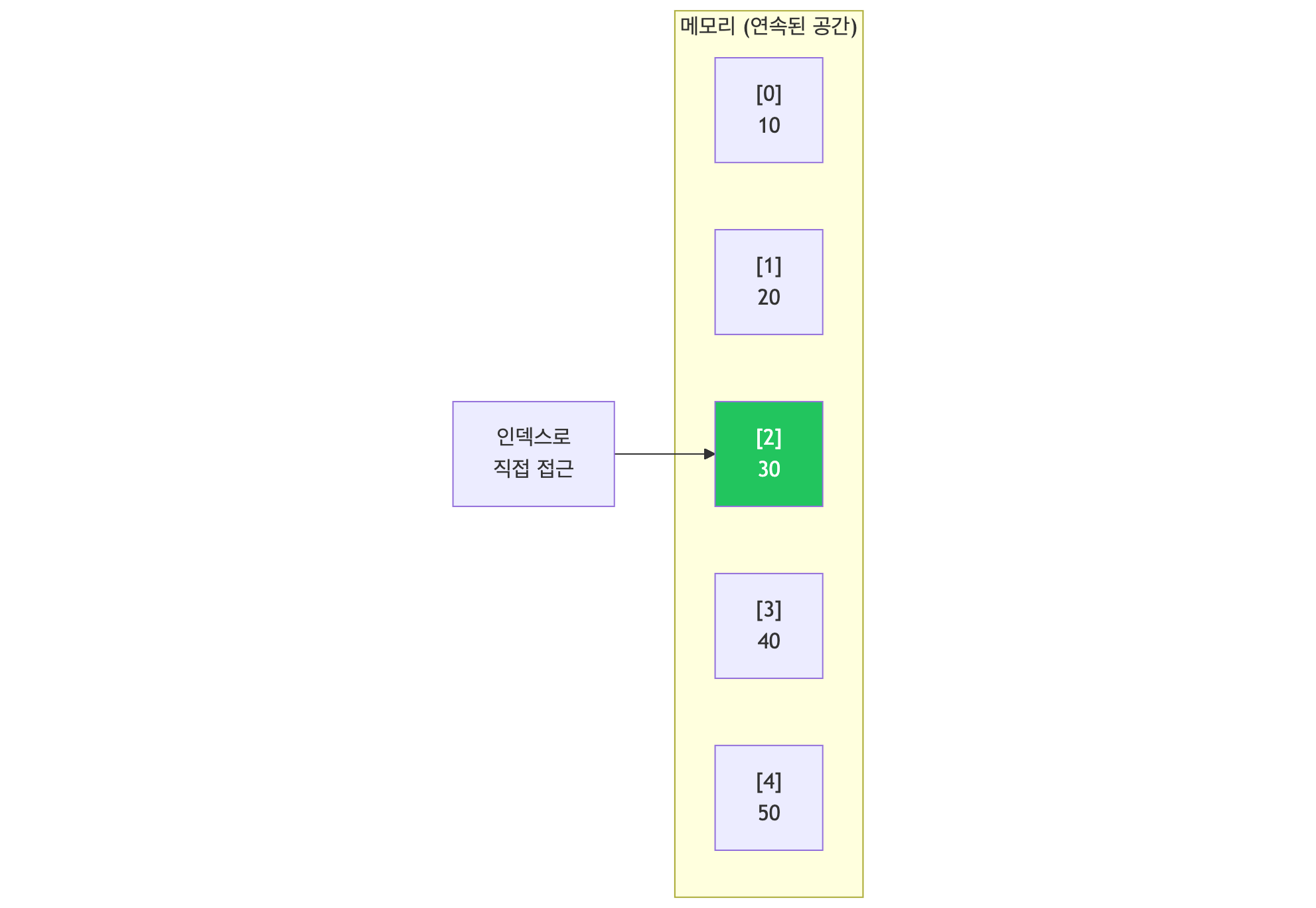
핵심 특징
| 특징 | 설명 |
|---|---|
| 인덱스 접근 | O(1) - 즉시 접근 가능 |
| 메모리 | 연속된 공간에 저장 |
| 크기 | 고정 (정적 배열) 또는 가변 (동적 배열) |
Python 코드
# 리스트 (동적 배열)
arr = [10, 20, 30, 40, 50]
# 접근: O(1)
print(arr[2]) # 30
# 맨 뒤 삽입: O(1)
arr.append(60) # [10, 20, 30, 40, 50, 60]
# 중간 삽입: O(n) - 뒤의 요소들을 밀어야 함
arr.insert(2, 25) # [10, 20, 25, 30, 40, 50, 60]
# 삭제: O(n)
arr.remove(25) # [10, 20, 30, 40, 50, 60]
# 검색: O(n)
index = arr.index(30) # 2Java 코드
import java.util.ArrayList;
import java.util.Arrays;
public class ArrayExample {
public static void main(String[] args) {
// 정적 배열
int[] staticArr = {10, 20, 30, 40, 50};
System.out.println(staticArr[2]); // 30
// 동적 배열 (ArrayList)
ArrayList<Integer> arr = new ArrayList<>(Arrays.asList(10, 20, 30, 40, 50));
// 접근: O(1)
System.out.println(arr.get(2)); // 30
// 맨 뒤 삽입: O(1)
arr.add(60);
// 중간 삽입: O(n)
arr.add(2, 25);
// 삭제: O(n)
arr.remove(Integer.valueOf(25));
// 검색: O(n)
int index = arr.indexOf(30); // 2
}
}시간 복잡도
| 연산 | 시간 복잡도 |
|---|---|
| 접근 (Access) | O(1) |
| 검색 (Search) | O(n) |
| 맨 뒤 삽입 | O(1) |
| 중간 삽입 | O(n) |
| 삭제 | O(n) |
장단점
| 장점 ✅ | 단점 ❌ |
|---|---|
| 인덱스로 즉시 접근 O(1) | 중간 삽입/삭제 느림 O(n) |
| 메모리 효율적 (연속 저장) | 정적 배열은 크기 변경 불가 |
| 캐시 친화적 | 동적 배열 확장 시 비용 발생 |
2️⃣ 연결 리스트 (Linked List)
개념
연결 리스트는 노드들이 포인터로 연결된 자료구조입니다. 각 노드는 데이터와 다음 노드를 가리키는 포인터를 가집니다.


핵심 특징
| 특징 | 설명 |
|---|---|
| 메모리 | 비연속적 (노드가 흩어져 있음) |
| 삽입/삭제 | O(1) - 포인터만 변경 |
| 접근 | O(n) - 처음부터 탐색 필요 |
Python 코드
# 노드 정의
class Node:
def __init__(self, data):
self.data = data
self.next = None
# 연결 리스트 정의
class LinkedList:
def __init__(self):
self.head = None
# 맨 앞 삽입: O(1)
def insert_front(self, data):
new_node = Node(data)
new_node.next = self.head
self.head = new_node
# 맨 뒤 삽입: O(n)
def insert_back(self, data):
new_node = Node(data)
if not self.head:
self.head = new_node
return
current = self.head
while current.next:
current = current.next
current.next = new_node
# 삭제: O(n) - 탐색 후 O(1) 삭제
def delete(self, data):
if not self.head:
return
if self.head.data == data:
self.head = self.head.next
return
current = self.head
while current.next and current.next.data != data:
current = current.next
if current.next:
current.next = current.next.next
# 출력
def display(self):
current = self.head
while current:
print(current.data, end=" -> ")
current = current.next
print("NULL")
# 사용
ll = LinkedList()
ll.insert_front(30)
ll.insert_front(20)
ll.insert_front(10)
ll.display() # 10 -> 20 -> 30 -> NULLJava 코드
import java.util.LinkedList;
public class LinkedListExample {
public static void main(String[] args) {
// Java 내장 LinkedList (이중 연결 리스트)
LinkedList<Integer> list = new LinkedList<>();
// 맨 앞 삽입: O(1)
list.addFirst(10);
list.addFirst(20);
// 맨 뒤 삽입: O(1) - 이중 연결 리스트라 tail 참조 있음
list.addLast(30);
// 접근: O(n)
System.out.println(list.get(1)); // 10
// 삭제: O(1) - 위치를 알면
list.removeFirst();
list.removeLast();
System.out.println(list); // [10]
}
}시간 복잡도
| 연산 | 시간 복잡도 |
|---|---|
| 접근 (Access) | O(n) |
| 검색 (Search) | O(n) |
| 맨 앞 삽입/삭제 | O(1) |
| 맨 뒤 삽입 | O(n) 또는 O(1)* |
| 중간 삽입/삭제 | O(1)** |
*tail 포인터가 있으면 O(1)
맨 뒤 삽입 시, tail 포인터 유무에 따라 성능이 달라집니다.

- tail 없으면: Head부터 끝까지 순회해야 마지막 노드를 찾음 → O(n)
- tail 있으면: 바로 마지막 노드에 접근 가능 → O(1)
# tail 포인터가 있는 연결 리스트
class LinkedListWithTail:
def __init__(self):
self.head = None
self.tail = None # tail 포인터 추가
# 맨 뒤 삽입: O(1)
def insert_back(self, data):
new_node = Node(data)
if not self.head:
self.head = new_node
self.tail = new_node
else:
self.tail.next = new_node # 바로 접근!
self.tail = new_node**위치를 알고 있을 때
중간 삽입/삭제는 탐색 시간과 실제 삽입/삭제 시간을 구분해야 합니다.
# 위치를 모르면 → 탐색 O(n) + 삽입 O(1) = O(n)
current = head
while current.data != target: # O(n) 탐색
current = current.next
# 위치(노드 참조)를 알고 있으면 → O(1)
# 포인터만 변경하면 끝
new_node.next = current.next # O(1)
current.next = new_node # O(1)- 위치 모르면: 탐색 O(n) + 삽입 O(1) = O(n)
- 위치 알면: 포인터 변경만 = O(1)
이것이 배열 대비 연결 리스트의 핵심 장점입니다. 배열은 위치를 알아도 삽입 시 요소들을 밀어야 하므로 O(n)이지만, 연결 리스트는 포인터만 바꾸면 됩니다.
장단점
| 장점 ✅ | 단점 ❌ |
|---|---|
| 삽입/삭제 빠름 O(1) | 인덱스 접근 느림 O(n) |
| 크기 동적 변경 용이 | 추가 메모리 (포인터) 필요 |
| 메모리 연속성 불필요 | 캐시 비친화적 |
3️⃣ 스택 (Stack)
개념
스택은 LIFO (Last In, First Out) 원칙을 따르는 자료구조입니다. 마지막에 넣은 데이터가 가장 먼저 나옵니다.
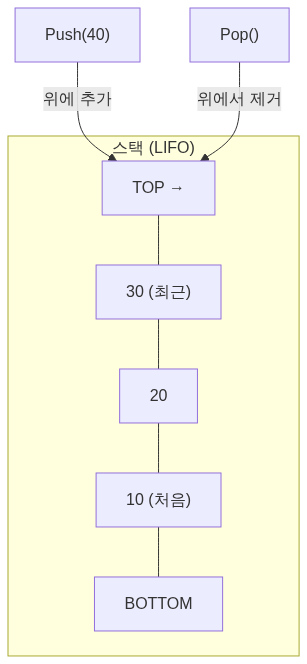
핵심 연산
| 연산 | 설명 | 시간 복잡도 |
|---|---|---|
| push | 맨 위에 삽입 | O(1) |
| pop | 맨 위에서 제거 | O(1) |
| peek/top | 맨 위 요소 확인 | O(1) |
| isEmpty | 비어있는지 확인 | O(1) |
Python 코드
# 리스트로 스택 구현
stack = []
# Push: O(1)
stack.append(10)
stack.append(20)
stack.append(30)
print(stack) # [10, 20, 30]
# Peek: O(1)
print(stack[-1]) # 30
# Pop: O(1)
top = stack.pop()
print(top) # 30
print(stack) # [10, 20]
# isEmpty
print(len(stack) == 0) # False
# collections.deque 사용 (더 효율적)
from collections import deque
stack = deque()
stack.append(10)
stack.append(20)
stack.pop() # 20Java 코드
import java.util.Stack;
import java.util.ArrayDeque;
import java.util.Deque;
public class StackExample {
public static void main(String[] args) {
// Stack 클래스 (레거시, 동기화됨)
Stack<Integer> stack = new Stack<>();
// Push: O(1)
stack.push(10);
stack.push(20);
stack.push(30);
// Peek: O(1)
System.out.println(stack.peek()); // 30
// Pop: O(1)
int top = stack.pop();
System.out.println(top); // 30
// isEmpty
System.out.println(stack.isEmpty()); // false
// ArrayDeque 사용 권장 (더 빠름)
Deque<Integer> betterStack = new ArrayDeque<>();
betterStack.push(10);
betterStack.push(20);
betterStack.pop(); // 20
}
}활용 사례
📚 사용 예시:
• 브라우저 뒤로 가기
• 실행 취소 (Undo)
• 함수 호출 스택 (Call Stack)
• 괄호 짝 맞추기
• DFS (깊이 우선 탐색)장단점
| 장점 ✅ | 단점 ❌ |
|---|---|
| 모든 연산 O(1) | 중간 요소 접근 불가 |
| 구현 간단 | LIFO만 가능 |
| 재귀 대체 가능 | 크기 제한 (고정 크기 시) |
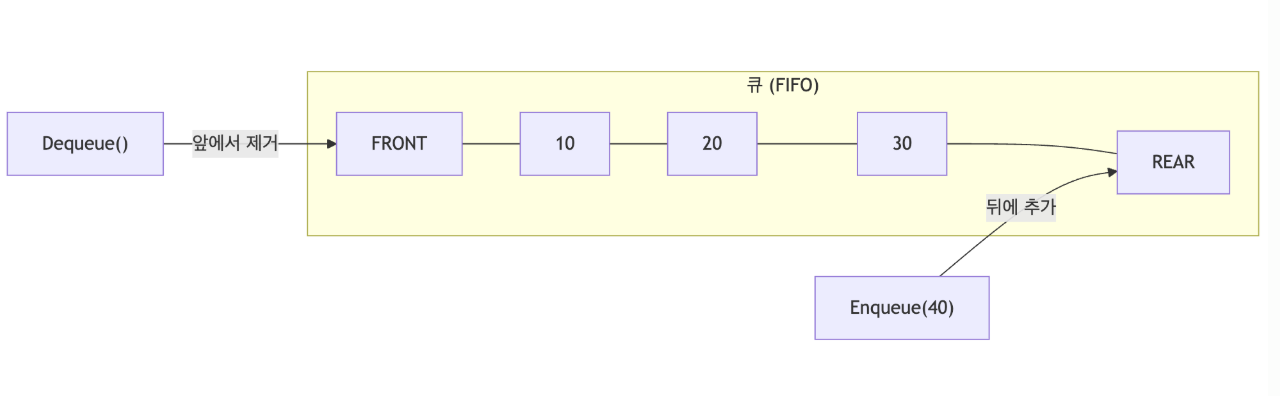
4️⃣ 큐 (Queue)
개념
큐는 FIFO (First In, First Out) 원칙을 따르는 자료구조입니다. 먼저 넣은 데이터가 먼저 나옵니다.
큐의 종류
핵심 연산
| 연산 | 설명 | 시간 복잡도 |
|---|---|---|
| enqueue | 뒤에 삽입 | O(1) |
| dequeue | 앞에서 제거 | O(1) |
| front/peek | 앞 요소 확인 | O(1) |
| isEmpty | 비어있는지 확인 | O(1) |
Python 코드
from collections import deque
# deque로 큐 구현 (권장)
queue = deque()
# Enqueue: O(1)
queue.append(10)
queue.append(20)
queue.append(30)
print(queue) # deque([10, 20, 30])
# Peek: O(1)
print(queue[0]) # 10
# Dequeue: O(1)
front = queue.popleft()
print(front) # 10
print(queue) # deque([20, 30])
# 우선순위 큐
import heapq
pq = []
heapq.heappush(pq, 30)
heapq.heappush(pq, 10)
heapq.heappush(pq, 20)
print(heapq.heappop(pq)) # 10 (최소값 먼저)
print(heapq.heappop(pq)) # 20Java 코드
import java.util.LinkedList;
import java.util.Queue;
import java.util.ArrayDeque;
import java.util.PriorityQueue;
public class QueueExample {
public static void main(String[] args) {
// Queue 인터페이스 - LinkedList 구현
Queue<Integer> queue = new LinkedList<>();
// Enqueue: O(1)
queue.offer(10);
queue.offer(20);
queue.offer(30);
// Peek: O(1)
System.out.println(queue.peek()); // 10
// Dequeue: O(1)
int front = queue.poll();
System.out.println(front); // 10
// ArrayDeque (더 빠름)
Queue<Integer> betterQueue = new ArrayDeque<>();
betterQueue.offer(10);
betterQueue.poll();
// 우선순위 큐
PriorityQueue<Integer> pq = new PriorityQueue<>();
pq.offer(30);
pq.offer(10);
pq.offer(20);
System.out.println(pq.poll()); // 10 (최소값 먼저)
System.out.println(pq.poll()); // 20
}
}활용 사례
📚 사용 예시:
• 프린터 작업 대기열
• 프로세스 스케줄링
• BFS (너비 우선 탐색)
• 메시지 큐 (Kafka, RabbitMQ)
• 캐시 (LRU)장단점
| 장점 ✅ | 단점 ❌ |
|---|---|
| 모든 연산 O(1) | 중간 요소 접근 불가 |
| 순서 보장 (FIFO) | 일반 배열 구현 시 메모리 낭비 |
| 비동기 처리에 적합 | - |
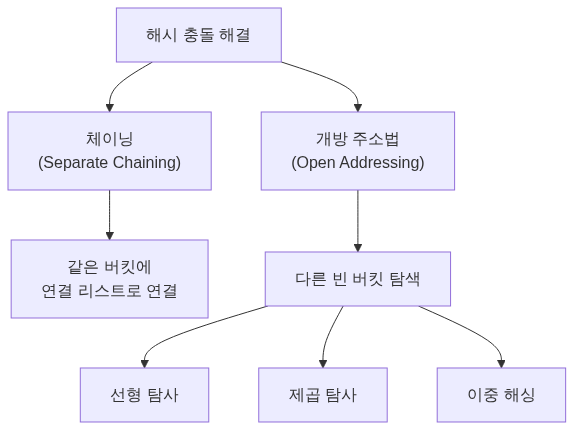
5️⃣ 해시 테이블 (Hash Table)
개념
해시 테이블은 Key-Value 쌍을 저장하는 자료구조입니다. 해시 함수를 사용하여 키를 인덱스로 변환하고, 평균 O(1) 시간에 데이터에 접근합니다.

해시 충돌 해결
Python 코드
# 딕셔너리 (해시 테이블)
hash_table = {}
# 삽입: O(1)
hash_table["apple"] = 100
hash_table["banana"] = 200
hash_table["cherry"] = 300
print(hash_table) # {'apple': 100, 'banana': 200, 'cherry': 300}
# 접근: O(1)
print(hash_table["apple"]) # 100
# 키 존재 확인: O(1)
print("apple" in hash_table) # True
# 삭제: O(1)
del hash_table["banana"]
# 안전한 접근
print(hash_table.get("grape", 0)) # 0 (기본값)
# 순회
for key, value in hash_table.items():
print(f"{key}: {value}")
# defaultdict (키가 없을 때 기본값)
from collections import defaultdict
counter = defaultdict(int)
counter["a"] += 1
counter["b"] += 1
counter["a"] += 1
print(counter) # defaultdict(<class 'int'>, {'a': 2, 'b': 1})
# Counter (빈도 계산)
from collections import Counter
words = ["apple", "banana", "apple", "cherry", "apple"]
word_count = Counter(words)
print(word_count) # Counter({'apple': 3, 'banana': 1, 'cherry': 1})
print(word_count.most_common(2)) # [('apple', 3), ('banana', 1)]Java 코드
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.TreeMap;
import java.util.Map;
public class HashTableExample {
public static void main(String[] args) {
// HashMap (순서 보장 X)
Map<String, Integer> map = new HashMap<>();
// 삽입: O(1)
map.put("apple", 100);
map.put("banana", 200);
map.put("cherry", 300);
// 접근: O(1)
System.out.println(map.get("apple")); // 100
// 키 존재 확인: O(1)
System.out.println(map.containsKey("apple")); // true
// 삭제: O(1)
map.remove("banana");
// 기본값 반환
System.out.println(map.getOrDefault("grape", 0)); // 0
// 순회
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// LinkedHashMap (삽입 순서 유지)
Map<String, Integer> linkedMap = new LinkedHashMap<>();
// TreeMap (키 정렬)
Map<String, Integer> treeMap = new TreeMap<>();
// 빈도 계산
String[] words = {"apple", "banana", "apple", "cherry", "apple"};
Map<String, Integer> counter = new HashMap<>();
for (String word : words) {
counter.put(word, counter.getOrDefault(word, 0) + 1);
}
System.out.println(counter); // {banana=1, cherry=1, apple=3}
}
}시간 복잡도
| 연산 | 평균 | 최악 |
|---|---|---|
| 삽입 | O(1) | O(n) |
| 접근 | O(1) | O(n) |
| 삭제 | O(1) | O(n) |
| 검색 | O(1) | O(n) |
최악의 경우: 모든 키가 같은 버킷에 충돌할 때
장단점
| 장점 ✅ | 단점 ❌ |
|---|---|
| 평균 O(1) 접근/삽입/삭제 | 해시 충돌 시 성능 저하 |
| Key-Value 매핑 | 순서 보장 X (HashMap) |
| 빠른 검색 | 메모리 오버헤드 |
| 유연한 키 타입 | 해시 함수 설계 중요 |
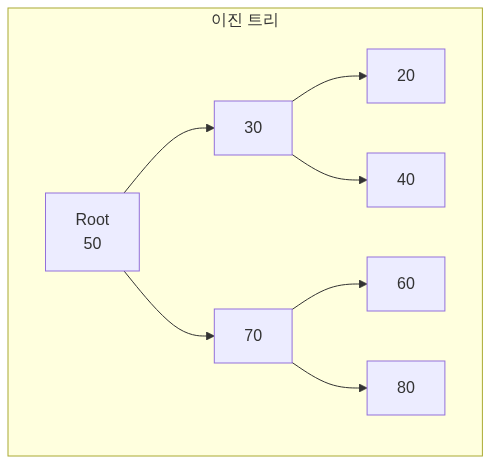
6️⃣ 트리 (Tree)
개념
트리는 계층적 구조를 가진 비선형 자료구조입니다. 하나의 루트 노드에서 시작하여 자식 노드들로 뻗어나갑니다.
트리 용어
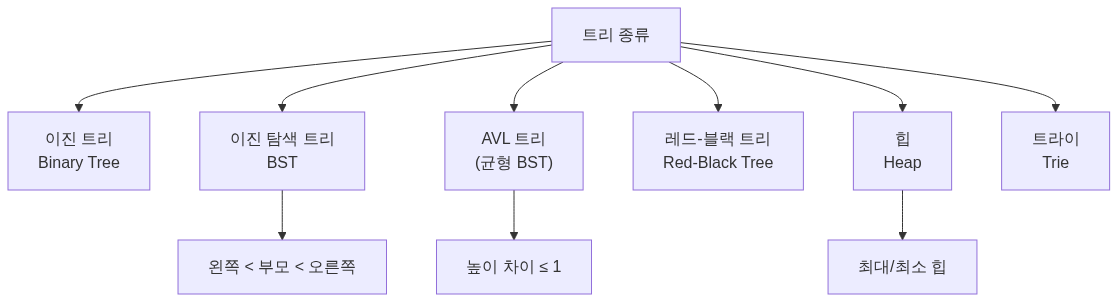
트리의 종류
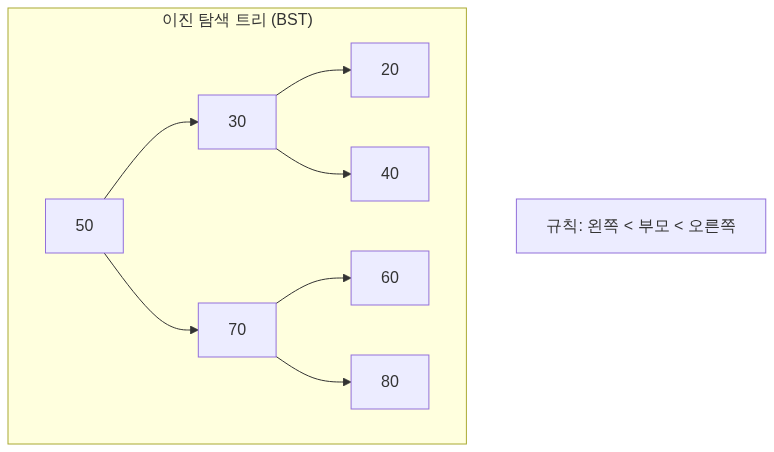
이진 탐색 트리 (BST)
Python 코드
# 이진 탐색 트리 (BST) 구현
class TreeNode:
def __init__(self, val):
self.val = val
self.left = None
self.right = None
class BST:
def __init__(self):
self.root = None
# 삽입: O(log n) 평균, O(n) 최악
def insert(self, val):
if not self.root:
self.root = TreeNode(val)
return
self._insert_recursive(self.root, val)
def _insert_recursive(self, node, val):
if val < node.val:
if node.left:
self._insert_recursive(node.left, val)
else:
node.left = TreeNode(val)
else:
if node.right:
self._insert_recursive(node.right, val)
else:
node.right = TreeNode(val)
# 검색: O(log n) 평균, O(n) 최악
def search(self, val):
return self._search_recursive(self.root, val)
def _search_recursive(self, node, val):
if not node:
return False
if val == node.val:
return True
elif val < node.val:
return self._search_recursive(node.left, val)
else:
return self._search_recursive(node.right, val)
# 중위 순회 (정렬된 순서)
def inorder(self):
result = []
self._inorder_recursive(self.root, result)
return result
def _inorder_recursive(self, node, result):
if node:
self._inorder_recursive(node.left, result)
result.append(node.val)
self._inorder_recursive(node.right, result)
# 사용
bst = BST()
for val in [50, 30, 70, 20, 40, 60, 80]:
bst.insert(val)
print(bst.search(40)) # True
print(bst.search(45)) # False
print(bst.inorder()) # [20, 30, 40, 50, 60, 70, 80]
# heapq로 힙 사용
import heapq
# 최소 힙
min_heap = []
heapq.heappush(min_heap, 50)
heapq.heappush(min_heap, 30)
heapq.heappush(min_heap, 70)
print(heapq.heappop(min_heap)) # 30 (최소값)
# 최대 힙 (음수 사용)
max_heap = []
for val in [50, 30, 70]:
heapq.heappush(max_heap, -val)
print(-heapq.heappop(max_heap)) # 70 (최대값)Java 코드
<import java.util.TreeSet;
import java.util.TreeMap;
import java.util.PriorityQueue;
import java.util.Collections;
public class TreeExample {
public static void main(String[] args) {
// TreeSet (레드-블랙 트리 기반, 정렬된 Set)
TreeSet<Integer> treeSet = new TreeSet<>();
treeSet.add(50);
treeSet.add(30);
treeSet.add(70);
treeSet.add(20);
System.out.println(treeSet); // [20, 30, 50, 70]
System.out.println(treeSet.first()); // 20 (최소)
System.out.println(treeSet.last()); // 70 (최대)
System.out.println(treeSet.floor(35)); // 30 (35 이하 최대)
// TreeMap (레드-블랙 트리 기반, 정렬된 Map)
TreeMap<String, Integer> treeMap = new TreeMap<>();
treeMap.put("banana", 2);
treeMap.put("apple", 1);
treeMap.put("cherry", 3);
System.out.println(treeMap); // {apple=1, banana=2, cherry=3}
// 최소 힙
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
minHeap.offer(50);
minHeap.offer(30);
minHeap.offer(70);
System.out.println(minHeap.poll()); // 30 (최소값)
// 최대 힙
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(Collections.reverseOrder());
maxHeap.offer(50);
maxHeap.offer(30);
maxHeap.offer(70);
System.out.println(maxHeap.poll()); // 70 (최대값)
}
}트리 순회

시간 복잡도
| 연산 | BST 평균 | BST 최악 | 균형 트리 |
|---|---|---|---|
| 삽입 | O(log n) | O(n) | O(log n) |
| 삭제 | O(log n) | O(n) | O(log n) |
| 검색 | O(log n) | O(n) | O(log n) |
장단점
| 장점 ✅ | 단점 ❌ |
|---|---|
| 계층 구조 표현 | 균형이 깨지면 O(n) |
| 정렬된 데이터 유지 (BST) | 구현 복잡 |
| O(log n) 연산 (균형 시) | 포인터 메모리 오버헤드 |
7️⃣ 그래프 (Graph)
개념
그래프는 정점(Vertex)과 간선(Edge)으로 이루어진 자료구조입니다. 네트워크, 관계, 경로 등을 표현합니다.
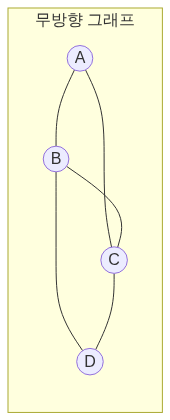
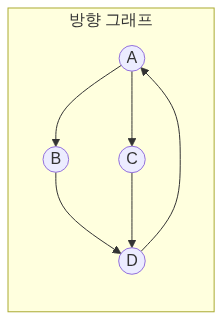
그래프 표현 방법
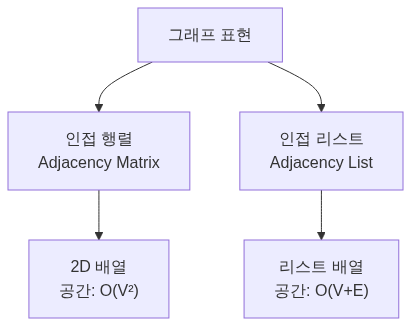
인접 행렬 vs 인접 리스트:
| 특성 | 인접 행렬 | 인접 리스트 |
|---|---|---|
| 공간 복잡도 | O(V²) | O(V+E) |
| 간선 확인 | O(1) | O(V) |
| 모든 간선 순회 | O(V²) | O(V+E) |
| 적합한 경우 | 밀집 그래프 | 희소 그래프 |
Python 코드
from collections import defaultdict, deque
# 인접 리스트로 그래프 구현
class Graph:
def __init__(self):
self.graph = defaultdict(list)
# 간선 추가 (무방향)
def add_edge(self, u, v):
self.graph[u].append(v)
self.graph[v].append(u)
# BFS (너비 우선 탐색)
def bfs(self, start):
visited = set()
queue = deque([start])
result = []
while queue:
vertex = queue.popleft()
if vertex not in visited:
visited.add(vertex)
result.append(vertex)
for neighbor in self.graph[vertex]:
if neighbor not in visited:
queue.append(neighbor)
return result
# DFS (깊이 우선 탐색)
def dfs(self, start):
visited = set()
result = []
self._dfs_recursive(start, visited, result)
return result
def _dfs_recursive(self, vertex, visited, result):
visited.add(vertex)
result.append(vertex)
for neighbor in self.graph[vertex]:
if neighbor not in visited:
self._dfs_recursive(neighbor, visited, result)
# 사용
g = Graph()
g.add_edge('A', 'B')
g.add_edge('A', 'C')
g.add_edge('B', 'C')
g.add_edge('B', 'D')
g.add_edge('C', 'D')
print("BFS:", g.bfs('A')) # ['A', 'B', 'C', 'D']
print("DFS:", g.dfs('A')) # ['A', 'B', 'C', 'D']
# 인접 행렬
V = 4 # 정점 수
adj_matrix = [[0] * V for _ in range(V)]
# 간선 추가 (0-indexed)
def add_edge_matrix(u, v):
adj_matrix[u][v] = 1
adj_matrix[v][u] = 1 # 무방향
add_edge_matrix(0, 1) # A-B
add_edge_matrix(0, 2) # A-C
add_edge_matrix(1, 3) # B-D
# 간선 확인: O(1)
print(adj_matrix[0][1]) # 1 (연결됨)
print(adj_matrix[0][3]) # 0 (연결 안됨)Java 코드
import java.util.*;
public class GraphExample {
// 인접 리스트
private Map<String, List<String>> adjList = new HashMap<>();
public void addEdge(String u, String v) {
adjList.computeIfAbsent(u, k -> new ArrayList<>()).add(v);
adjList.computeIfAbsent(v, k -> new ArrayList<>()).add(u);
}
// BFS
public List<String> bfs(String start) {
List<String> result = new ArrayList<>();
Set<String> visited = new HashSet<>();
Queue<String> queue = new LinkedList<>();
queue.offer(start);
while (!queue.isEmpty()) {
String vertex = queue.poll();
if (!visited.contains(vertex)) {
visited.add(vertex);
result.add(vertex);
for (String neighbor : adjList.getOrDefault(vertex, new ArrayList<>())) {
if (!visited.contains(neighbor)) {
queue.offer(neighbor);
}
}
}
}
return result;
}
// DFS
public List<String> dfs(String start) {
List<String> result = new ArrayList<>();
Set<String> visited = new HashSet<>();
dfsRecursive(start, visited, result);
return result;
}
private void dfsRecursive(String vertex, Set<String> visited, List<String> result) {
visited.add(vertex);
result.add(vertex);
for (String neighbor : adjList.getOrDefault(vertex, new ArrayList<>())) {
if (!visited.contains(neighbor)) {
dfsRecursive(neighbor, visited, result);
}
}
}
public static void main(String[] args) {
GraphExample g = new GraphExample();
g.addEdge("A", "B");
g.addEdge("A", "C");
g.addEdge("B", "C");
g.addEdge("B", "D");
g.addEdge("C", "D");
System.out.println("BFS: " + g.bfs("A")); // [A, B, C, D]
System.out.println("DFS: " + g.dfs("A")); // [A, B, C, D]
}
}BFS vs DFS
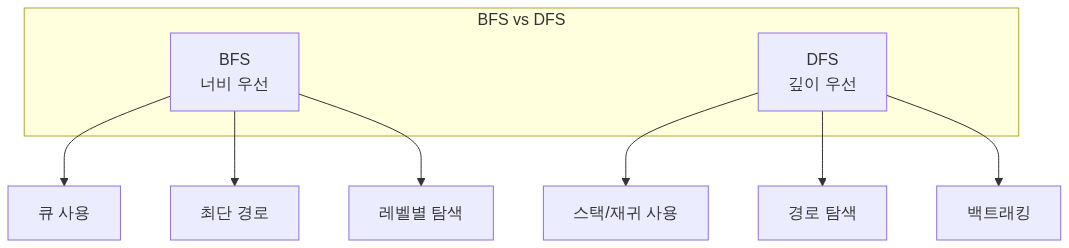
활용 사례
📚 그래프 사용 예시:
• 소셜 네트워크 (친구 관계)
• 지도 / 네비게이션 (최단 경로)
• 웹 크롤링
• 추천 시스템
• 의존성 분석 (패키지 매니저)장단점
| 장점 ✅ | 단점 ❌ |
|---|---|
| 복잡한 관계 표현 | 구현 복잡 |
| 다양한 알고리즘 적용 | 메모리 사용량 높음 |
| 네트워크 문제 해결 | 순회 복잡 |
📊 Map vs List 비교
핵심 차이
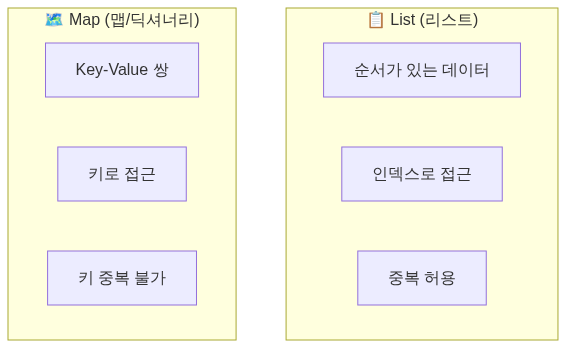
비교표
| 특성 | List | Map |
|---|---|---|
| 접근 방식 | 인덱스 (0, 1, 2...) | 키 (문자열, 객체 등) |
| 순서 | 보장 | HashMap: X, LinkedHashMap: O |
| 중복 | 허용 | 키: 불가, 값: 허용 |
| 검색 | O(n) | O(1) 평균 |
| 인덱스 접근 | O(1) | 불가 |
| 메모리 | 효율적 | 오버헤드 있음 |
언제 무엇을 사용할까?
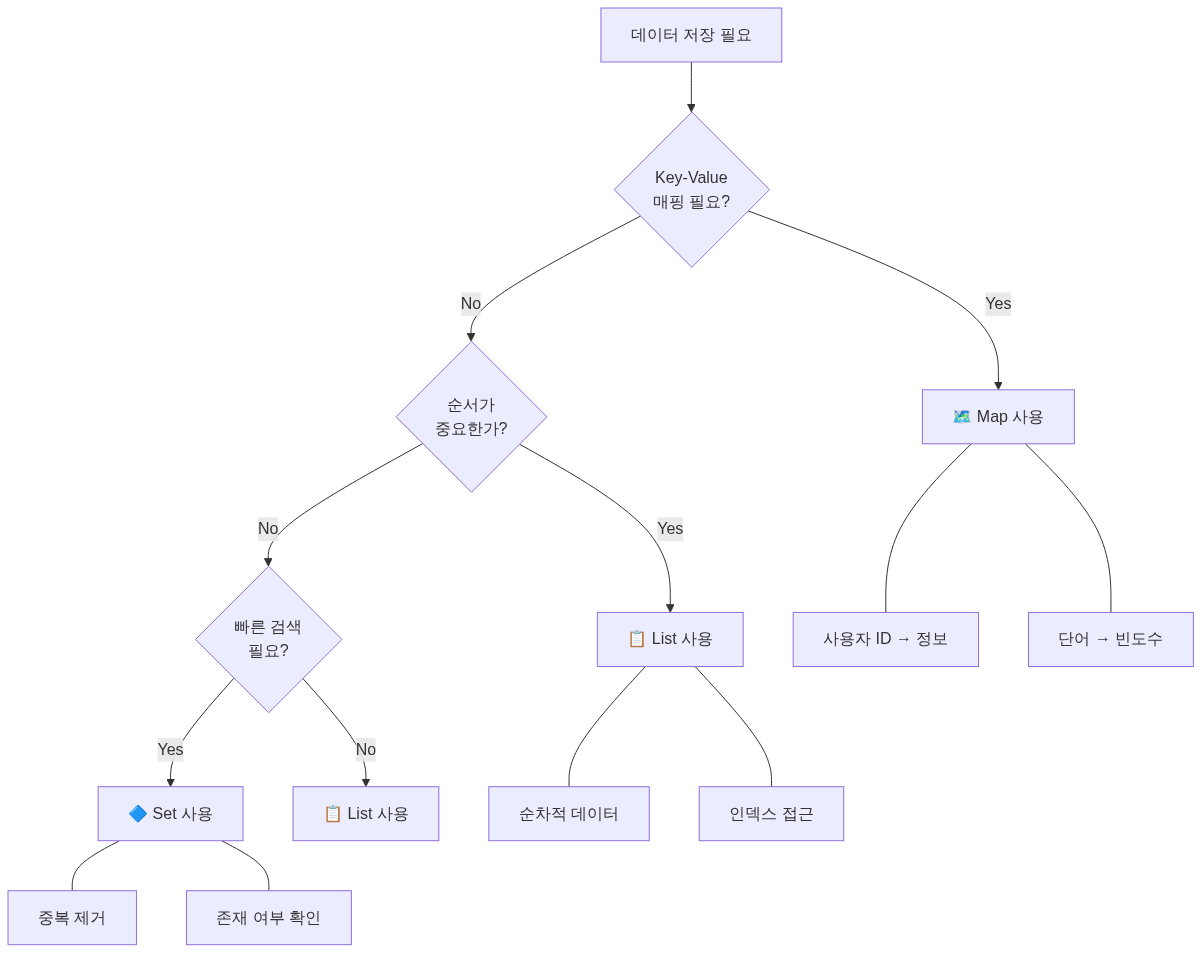
Python 예시
# List - 순서가 중요한 데이터
scores = [85, 90, 78, 92, 88]
print(scores[2]) # 78 (인덱스 접근)
print(78 in scores) # True (검색: O(n))
# Map (dict) - Key-Value 매핑
student_scores = {
"Alice": 85,
"Bob": 90,
"Charlie": 78
}
print(student_scores["Bob"]) # 90 (키 접근: O(1))
print("Bob" in student_scores) # True (검색: O(1))
# 실전 예시: 빈도수 계산
words = ["apple", "banana", "apple", "cherry", "banana", "apple"]
# List로 하면 비효율적
# O(n²) - 매번 count 해야 함
# Map으로 하면 효율적
word_count = {}
for word in words:
word_count[word] = word_count.get(word, 0) + 1
# O(n) - 한 번 순회로 끝
print(word_count) # {'apple': 3, 'banana': 2, 'cherry': 1}Java 예시
<import java.util.*;
public class ListVsMap {
public static void main(String[] args) {
// List - 순서가 중요한 데이터
List<Integer> scores = Arrays.asList(85, 90, 78, 92, 88);
System.out.println(scores.get(2)); // 78
System.out.println(scores.contains(78)); // true (O(n))
// Map - Key-Value 매핑
Map<String, Integer> studentScores = new HashMap<>();
studentScores.put("Alice", 85);
studentScores.put("Bob", 90);
studentScores.put("Charlie", 78);
System.out.println(studentScores.get("Bob")); // 90 (O(1))
System.out.println(studentScores.containsKey("Bob")); // true (O(1))
// 빈도수 계산 예시
String[] words = {"apple", "banana", "apple", "cherry", "banana", "apple"};
Map<String, Integer> wordCount = new HashMap<>();
for (String word : words) {
wordCount.put(word, wordCount.getOrDefault(word, 0) + 1);
}
System.out.println(wordCount); // {banana=2, cherry=1, apple=3}
}
}선택 가이드
| 상황 | 선택 | 이유 |
|---|---|---|
| 순차 데이터 저장 | List | 순서 유지, 인덱스 접근 |
| 빠른 검색 필요 | Map/Set | O(1) 검색 |
| Key-Value 매핑 | Map | 자연스러운 표현 |
| 중복 허용 필요 | List | Map 키는 중복 불가 |
| 빈도수 계산 | Map | 키: 항목, 값: 개수 |
| 캐시 구현 | Map | 키로 빠른 접근 |
| 정렬된 순회 필요 | List 또는 TreeMap | 순서 보장 |
🎯 자료구조 선택 가이드
시간 복잡도 총정리
| 자료구조 | 접근 | 검색 | 삽입 | 삭제 |
|---|---|---|---|---|
| 배열 | O(1) | O(n) | O(n) | O(n) |
| 연결 리스트 | O(n) | O(n) | O(1)* | O(1)* |
| 스택 | O(n) | O(n) | O(1) | O(1) |
| 큐 | O(n) | O(n) | O(1) | O(1) |
| 해시 테이블 | - | O(1) | O(1) | O(1) |
| 이진 탐색 트리 | - | O(log n) | O(log n) | O(log n) |
| 그래프 (인접 리스트) | - | O(V) | O(1) | O(E) |
*위치를 알고 있을 때
상황별 최적 선택
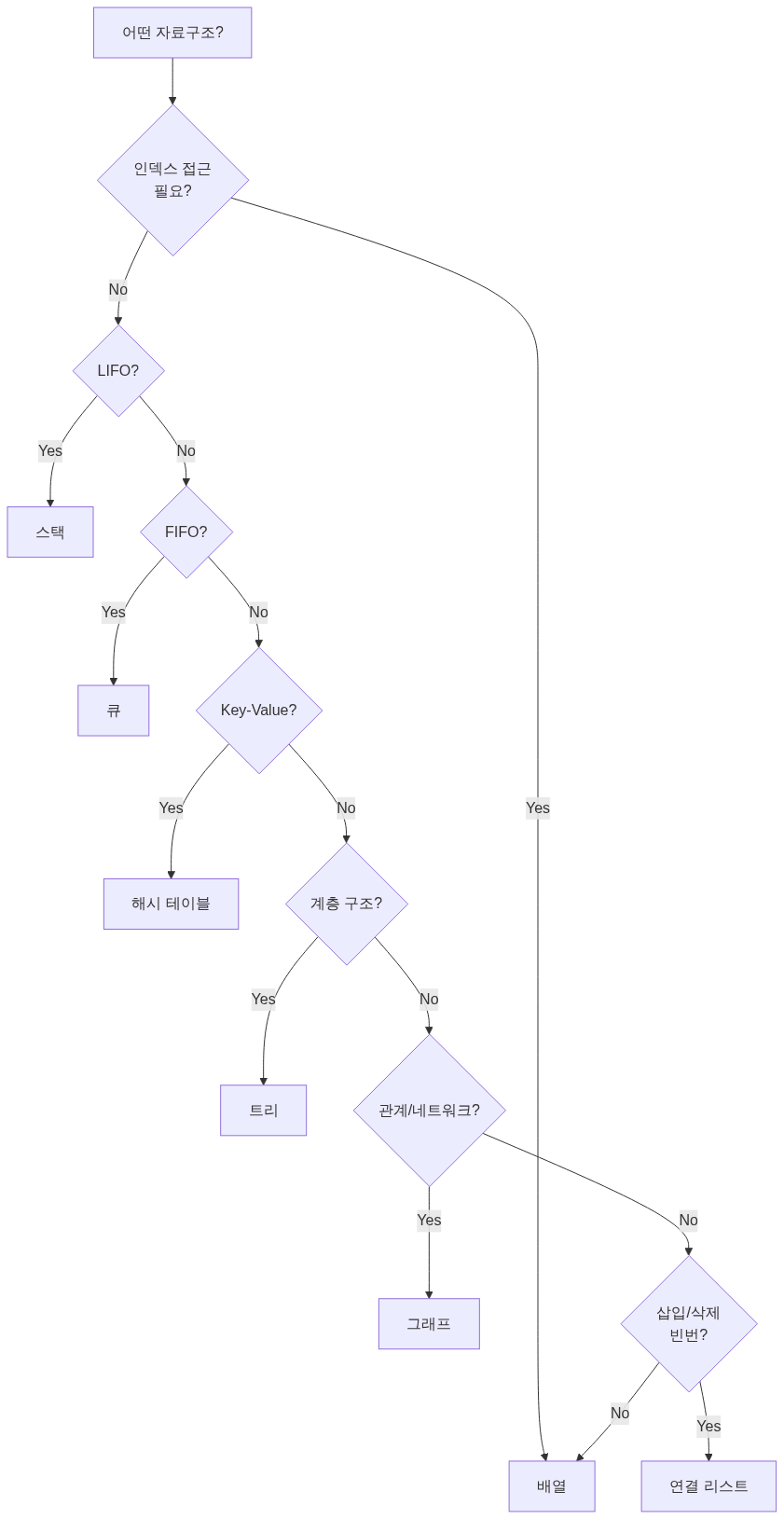
💡 결론
핵심 정리
"자료구조를 알면 알고리즘이 보인다."
| 자료구조 | 한 줄 요약 | 대표 사용 |
|---|---|---|
| 배열 | 인덱스로 빠른 접근 | 순차 데이터 |
| 연결 리스트 | 삽입/삭제 빠름 | 동적 크기 데이터 |
| 스택 | LIFO | Undo, DFS |
| 큐 | FIFO | 작업 대기열, BFS |
| 해시 테이블 | O(1) 검색 | 캐시, 중복 체크 |
| 트리 | 계층 + 정렬 | DB 인덱스, 파일 시스템 |
| 그래프 | 관계 표현 | 네트워크, 경로 탐색 |
📚 참고 자료
