
"ChatGPT가 내 문서를 읽고 답변하게 하려면?"
Vector DB는 AI 애플리케이션의 기억 저장소입니다.
📌 들어가며
AI 애플리케이션을 만들다 보면 이런 상황을 마주합니다.
- ChatGPT에게 우리 회사 문서를 학습시키고 싶다.
- 사용자 질문과 유사한 FAQ를 찾고 싶다.
- 이미지로 비슷한 상품을 검색하고 싶다.
이 모든 것의 핵심에 Vector Database가 있습니다.
이 글에서는 Vector DB가 무엇인지, 왜 필요한지, 그리고 ChromaDB, Pinecone, Milvus, Qdrant 등 주요 Vector DB를 비교해보겠습니다.
🤔 Vector Database란?
한 줄 정의
Vector Database는 데이터를 벡터(숫자 배열) 형태로 저장하고, 유사도 검색을 수행하는 데이터베이스입니다.
기존 DB vs Vector DB
📊 기존 데이터베이스:
"사과가 들어간 레시피 찾아줘"
→ WHERE ingredient LIKE '%사과%'
→ 정확히 "사과"가 포함된 것만 검색
🧠 Vector Database:
"사과가 들어간 레시피 찾아줘"
→ "사과" → [0.12, -0.34, 0.56, ...] (벡터로 변환)
→ 비슷한 의미의 벡터 검색
→ "애플파이", "사과잼", "과일 샐러드" 등 의미적으로 유사한 결과벡터(Embedding)란?
Embedding은 텍스트, 이미지, 오디오 등을 숫자 배열로 변환한 것입니다.
# 텍스트를 벡터로 변환하는 예시
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
text = "오늘 날씨가 좋네요"
vector = model.encode(text)
# → [0.023, -0.156, 0.089, ..., 0.234] (384차원 벡터)핵심 원리:
- 의미가 비슷한 문장 → 비슷한 벡터
- 의미가 다른 문장 → 다른 벡터
"오늘 날씨가 좋네요" ≈ "오늘 하늘이 맑아요" (벡터 유사도 높음)
"오늘 날씨가 좋네요" ≠ "어제 야근했어요" (벡터 유사도 낮음)🎯 왜 Vector DB가 필요한가?
1. RAG (Retrieval-Augmented Generation)
LLM에게 외부 지식을 주입하는 기술

RAG가 필요한 이유?
- LLM은 학습 데이터 이후의 정보를 모름
- 회사 내부 문서, 최신 뉴스 등 커스텀 지식 필요
- Vector DB가 관련 문서를 찾아서 LLM에게 전달
2. 시맨틱 검색 (Semantic Search)
🔍 키워드 검색:
"저렴한 노트북" → "저렴한", "노트북" 키워드 매칭
🧠 시맨틱 검색:
"저렴한 노트북" → 의미적으로 유사한 결과
→ "가성비 좋은 랩탑", "학생용 컴퓨터", "예산 친화적 PC"3. 추천 시스템
👤 사용자가 본 상품: "나이키 운동화"
↓ (벡터 유사도 검색)
📦 추천 상품: "아디다스 러닝화", "뉴발란스 스니커즈"4. 이미지/멀티모달 검색
📷 이미지 업로드: [빨간 드레스 사진]
↓ (이미지 → 벡터 변환)
🛍️ 검색 결과: 비슷한 스타일의 빨간 드레스들🏗️ Vector DB 동작 원리
핵심 개념
| 개념 | 설명 |
|---|---|
| Embedding | 데이터를 벡터로 변환 |
| Index | 빠른 검색을 위한 자료구조 |
| Similarity | 벡터 간 유사도 측정 |
| ANN | 근사 최근접 이웃 검색 |
인덱싱 알고리즘
🌳 HNSW (Hierarchical Navigable Small World)
- 그래프 기반 알고리즘
- 높은 정확도 + 빠른 검색
- 메모리 사용량 높음
- 대부분의 Vector DB에서 사용
📊 IVF (Inverted File Index)
- 클러스터링 기반
- 메모리 효율적
- 대용량 데이터에 적합
🗜️ PQ (Product Quantization)
- 벡터 압축 기술
- 메모리 절약
- 약간의 정확도 손실유사도 측정 방법
# 코사인 유사도 (Cosine Similarity)
# -1 ~ 1 범위, 1에 가까울수록 유사
cos_sim = dot(A, B) / (norm(A) * norm(B))
# 유클리드 거리 (Euclidean Distance)
# 0에 가까울수록 유사
euclidean = sqrt(sum((A - B)^2))
# 내적 (Dot Product)
# 값이 클수록 유사
dot_product = sum(A * B)🗃️ 주요 Vector Database 비교
한눈에 보기
| DB | 유형 | 특징 | 적합한 용도 |
|---|---|---|---|
| ChromaDB | 오픈소스 (로컬) | 초간단, 빠른 프로토타이핑 | MVP, 학습, 소규모 |
| Pinecone | 관리형 클라우드 | 제로 운영, 엔터프라이즈 | 프로덕션, 대규모 |
| Milvus | 오픈소스 (분산) | 대용량, 고성능 | 10억+ 벡터 |
| Qdrant | 오픈소스 | 고성능, 필터링 강점 | 중~대규모 |
| Weaviate | 오픈소스 | 하이브리드 검색 | 복잡한 쿼리 |
| pgvector | PostgreSQL 확장 | 기존 인프라 활용 | PostgreSQL 사용자 |
🟢 ChromaDB
특징
가장 쉽고 빠른 Vector DB. 프로토타이핑에 가장 적합.
✅ 장점:
- 설치, 사용 쉬움
- Python 네이티브 API
- LangChain 완벽 통합
- 완전 무료 (Apache 2.0)
- 2025년 Rust 재작성으로 4배 빨라짐
❌ 단점:
- 대규모 프로덕션에 부적합
- 1000만 벡터 이상은 힘듦
- 분산 처리 미지원설치 및 사용
pip install chromadbimport chromadb
# 클라이언트 생성
client = chromadb.Client()
# 컬렉션 생성
collection = client.create_collection(name="my_docs")
# 문서 추가 (자동 임베딩)
collection.add(
documents=[
"오늘 날씨가 좋습니다",
"내일 비가 올 예정입니다",
"주말에 등산을 가려고 합니다"
],
ids=["doc1", "doc2", "doc3"],
metadatas=[
{"topic": "날씨"},
{"topic": "날씨"},
{"topic": "여행"}
]
)
# 유사도 검색
results = collection.query(
query_texts=["날씨가 어때요?"],
n_results=2
)
print(results)
# → "오늘 날씨가 좋습니다", "내일 비가 올 예정입니다"영구 저장
# 파일로 저장
client = chromadb.PersistentClient(path="./chroma_db")
# 이후 재시작해도 데이터 유지✅ ChromaDB를 선택하기 적합한 상황
- RAG 프로토타입 빠르게 만들기
- LangChain/LlamaIndex 튜토리얼 따라하기
- 소규모 챗봇 (100만 벡터 이하)
- 개인 프로젝트, 학습용🌲 Pinecone
특징
완전 관리형 Vector DB. 운영 걱정 제로.
✅ 장점:
- 서버 관리 불필요 (Serverless)
- 자동 스케일링
- 수십억 벡터 처리 가능
- 5~10ms 낮은 지연시간
- 엔터프라이즈급 보안
❌ 단점:
- 비용이 높음 (대규모 시)
- 클라우드 종속
- 오픈소스 아님가격
| 플랜 | 가격 | 특징 |
|---|---|---|
| Free | $0 | 1개 인덱스, 100K 벡터 |
| Starter | $0 | 5개 인덱스, 제한적 |
| Standard | 사용량 기반 | 서버리스, 자동 스케일링 |
| Enterprise | 협의 | 전용 인프라, SLA |
사용 예시
pip install pinecone-clientfrom pinecone import Pinecone
# 초기화
pc = Pinecone(api_key="YOUR_API_KEY")
# 인덱스 생성
pc.create_index(
name="my-index",
dimension=1536, # OpenAI 임베딩 차원
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1")
)
# 인덱스 연결
index = pc.Index("my-index")
# 벡터 업서트
index.upsert(
vectors=[
{
"id": "doc1",
"values": [0.1, 0.2, ...], # 1536차원 벡터
"metadata": {"title": "문서 제목", "category": "기술"}
}
]
)
# 검색
results = index.query(
vector=[0.1, 0.2, ...],
top_k=5,
include_metadata=True,
filter={"category": {"$eq": "기술"}}
)✅ Pinecone을 선택하기 적합한 상황
- 프로덕션 RAG 서비스
- 운영팀 없이 AI 서비스 런칭
- 엔터프라이즈급 안정성 필요
- 빠른 시장 진입이 중요할 때🐋 Milvus
특징
대규모 분산 처리의 강자. 10억+ 벡터 전문.
✅ 장점:
- 오픈소스 (Apache 2.0)
- 수십억 벡터 처리
- 다양한 인덱스 지원 (HNSW, IVF, DiskANN)
- GPU 가속 지원
- Zilliz Cloud (관리형) 제공
❌ 단점:
- 설치/운영 복잡
- 소규모에는 과함
- 학습 곡선 높음아키텍처
┌─────────────────────────────────────┐
│ Milvus Cluster │
├─────────────┬───────────────────────┤
│ Proxy │ 쿼리 라우팅 │
├─────────────┼───────────────────────┤
│ Query │ 검색 처리 │
│ Nodes │ │
├─────────────┼───────────────────────┤
│ Data │ 데이터 저장/인덱싱 │
│ Nodes │ │
├─────────────┼───────────────────────┤
│ etcd │ 메타데이터 관리 │
│ MinIO │ 오브젝트 스토리지 │
│ Pulsar │ 메시지 큐 │
└─────────────┴───────────────────────┘사용 예시
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType
# 연결
connections.connect("default", host="localhost", port="19530")
# 스키마 정의
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=768),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=1000)
]
schema = CollectionSchema(fields, description="문서 컬렉션")
# 컬렉션 생성
collection = Collection("documents", schema)
# 인덱스 생성
index_params = {
"metric_type": "COSINE",
"index_type": "HNSW",
"params": {"M": 16, "efConstruction": 256}
}
collection.create_index("embedding", index_params)
# 검색
results = collection.search(
data=[query_vector],
anns_field="embedding",
param={"metric_type": "COSINE", "params": {"ef": 64}},
limit=10
)✅ Milvus를 선택하기 적합한 상황
- 10억 개 이상의 벡터
- 데이터 엔지니어링 팀이 있을 때
- 완전한 통제권이 필요할 때
- GPU 가속이 필요할 때🔷 Qdrant
특징
성능과 효율의 균형. Rust로 작성된 고성능 DB.
✅ 장점:
- Rust 기반 고성능
- 메모리 효율적
- 강력한 필터링 기능
- 오픈소스 + 클라우드 옵션
- 합리적인 가격
❌ 단점:
- Pinecone보다 설정 필요
- 커뮤니티 규모 작음가격 (Qdrant Cloud)
| 플랜 | 가격 | 특징 |
|---|---|---|
| Free | $0 | 1GB, 1 클러스터 |
| Standard | $0.025/GB | 자동 스케일링 |
| Enterprise | 협의 | SLA, 전용 지원 |
사용 예시
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
# 클라이언트 연결
client = QdrantClient("localhost", port=6333)
# 컬렉션 생성
client.create_collection(
collection_name="my_collection",
vectors_config=VectorParams(size=768, distance=Distance.COSINE)
)
# 포인트 추가
client.upsert(
collection_name="my_collection",
points=[
PointStruct(
id=1,
vector=[0.1, 0.2, ...],
payload={"title": "문서 1", "category": "tech"}
),
PointStruct(
id=2,
vector=[0.3, 0.4, ...],
payload={"title": "문서 2", "category": "science"}
)
]
)
# 필터링 검색
results = client.search(
collection_name="my_collection",
query_vector=[0.1, 0.2, ...],
query_filter={
"must": [{"key": "category", "match": {"value": "tech"}}]
},
limit=5
)✅ Qdrant를 선택하기 적합한 상황
- 비용 효율적인 프로덕션
- 복잡한 메타데이터 필터링
- 셀프 호스팅 + 클라우드 유연성
- 중간 규모 (100만~10억 벡터)🔶 Weaviate
특징
하이브리드 검색의 강자. 벡터 + 키워드 결합.
✅ 장점:
- 하이브리드 검색 (벡터 + BM25)
- GraphQL API
- 모듈식 확장
- 내장 임베딩 모델 연동
- 오픈소스 + 클라우드
❌ 단점:
- 설정 복잡
- 리소스 사용량 높음하이브리드 검색
import weaviate
client = weaviate.Client("http://localhost:8080")
# 하이브리드 검색: 벡터 + 키워드 결합
result = client.query.get(
"Document", ["title", "content"]
).with_hybrid(
query="머신러닝 튜토리얼",
alpha=0.5 # 0: 키워드만, 1: 벡터만, 0.5: 균형
).with_limit(5).do()✅ Weaviate를 선택하기 적합한 상황
- 키워드 + 시맨틱 검색 결합
- GraphQL 선호
- 모듈식 AI 통합
- 복잡한 데이터 관계🐘 pgvector
특징
PostgreSQL 확장. 기존 인프라 활용.
✅ 장점:
- PostgreSQL에 벡터 기능 추가
- 기존 SQL 지식 활용
- 관계형 데이터 + 벡터 통합
- 운영 비용 절감
❌ 단점:
- 전용 Vector DB보다 느림
- 대규모 확장 한계사용 예시
-- 확장 설치
CREATE EXTENSION vector;
-- 테이블 생성
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding vector(768) -- 768차원 벡터
);
-- 인덱스 생성
CREATE INDEX ON documents
USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);
-- 유사도 검색
SELECT id, content,
1 - (embedding <=> '[0.1, 0.2, ...]') AS similarity
FROM documents
ORDER BY embedding <=> '[0.1, 0.2, ...]'
LIMIT 5;✅ pgvector를 선택하기 적합한 상황
- 이미 PostgreSQL 사용 중
- 새 인프라 도입 어려움
- 벡터 + 관계형 데이터 JOIN 필요
- 중소규모 (100만 벡터 이하)⚡ 시맨틱 캐싱 (Semantic Caching)
시맨틱 캐싱이란?
시맨틱 캐싱은 Vector DB를 활용해 유사한 질문에 대해 LLM 호출을 생략하고, 캐시된 답변을 반환하는 기술입니다.
일반적인 RAG 시스템은 매 질문마다 LLM을 호출합니다. 하지만 비슷한 질문이 반복되면 동일한 비용과 시간이 계속 발생합니다.
❌ 일반 RAG의 문제점:
"회사 휴가 정책이 뭐야?" → LLM 호출 (0.5초, $0.01)
"휴가 규정 알려줘" → LLM 호출 (0.5초, $0.01) ← 거의 같은 질문!
"연차 정책이 어떻게 돼?" → LLM 호출 (0.5초, $0.01) ← 또 비슷한 질문!
→ 3번의 LLM 호출, 총 1.5초, $0.03✅ 시맨틱 캐싱 적용 후:
"회사 휴가 정책이 뭐야?" → LLM 호출 → 캐시 저장 (0.5초, $0.01)
"휴가 규정 알려줘" → 캐시 히트! (0.05초, $0) ← 유사 질문 감지!
"연차 정책이 어떻게 돼?" → 캐시 히트! (0.05초, $0) ← 유사 질문 감지!
→ 1번의 LLM 호출, 총 0.6초, $0.01 (66% 비용 절감!)시맨틱 캐싱 아키텍처
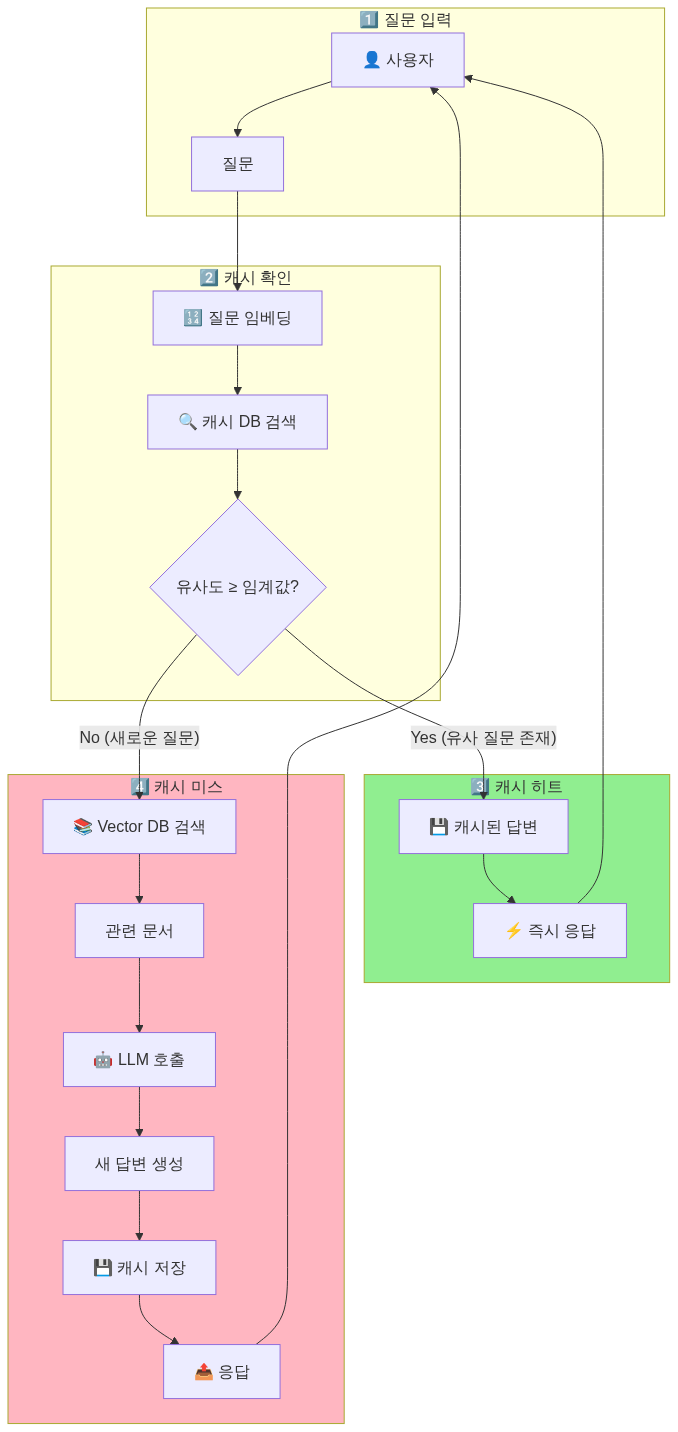
왜 효율적인가?
| 지표 | 캐시 미스 (LLM 호출) | 캐시 히트 | 개선율 |
|---|---|---|---|
| 응답 시간 | 500ms ~ 3초 | 10~50ms | 10~100배 빠름 |
| 비용 | $0.01 ~ $0.10/요청 | ~$0 | 비용 절감 |
| API 부하 | 매번 호출 | 호출 없음 | 무제한 확장 |
실제 구현 예시
import chromadb
from openai import OpenAI
# 캐시용 Vector DB 초기화
cache_client = chromadb.PersistentClient(path="./semantic_cache")
cache_collection = cache_client.get_or_create_collection(
name="qa_cache",
metadata={"hnsw:space": "cosine"}
)
# 문서용 Vector DB
docs_collection = cache_client.get_or_create_collection(name="documents")
openai_client = OpenAI()
SIMILARITY_THRESHOLD = 0.92 # 유사도 임계값 (조정 가능)
def get_embedding(text: str) -> list:
"""텍스트를 임베딩으로 변환"""
response = openai_client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def semantic_cache_query(question: str) -> str:
"""시맨틱 캐싱이 적용된 RAG 쿼리"""
# 1️⃣ 질문 임베딩 생성
question_embedding = get_embedding(question)
# 2️⃣ 캐시에서 유사 질문 검색
cache_results = cache_collection.query(
query_embeddings=[question_embedding],
n_results=1,
include=["documents", "metadatas", "distances"]
)
# 3️⃣ 캐시 히트 확인 (코사인 거리 → 유사도 변환)
if cache_results["distances"][0]:
similarity = 1 - cache_results["distances"][0][0]
if similarity >= SIMILARITY_THRESHOLD:
# ✅ 캐시 히트! LLM 호출 없이 즉시 반환
cached_answer = cache_results["metadatas"][0][0]["answer"]
print(f"⚡ 캐시 히트! (유사도: {similarity:.2%})")
return cached_answer
# 4️⃣ 캐시 미스 → 일반 RAG 수행
print("🔄 캐시 미스, LLM 호출 중...")
# 문서 검색
docs_results = docs_collection.query(
query_embeddings=[question_embedding],
n_results=3
)
context = "\n".join(docs_results["documents"][0])
# LLM 호출
response = openai_client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "주어진 문서를 참고하여 답변하세요."},
{"role": "user", "content": f"문서:\n{context}\n\n질문: {question}"}
]
)
answer = response.choices[0].message.content
# 5️⃣ 캐시에 저장
cache_collection.add(
embeddings=[question_embedding],
documents=[question],
metadatas=[{"answer": answer, "original_question": question}],
ids=[f"cache_{hash(question)}"]
)
return answer
# 사용 예시
print(semantic_cache_query("회사 휴가 정책이 뭔가요?"))
# → 🔄 캐시 미스, LLM 호출 중... (첫 질문)
print(semantic_cache_query("휴가 규정 알려줘"))
# → ⚡ 캐시 히트! (유사도: 94.5%) (유사 질문, 즉시 응답)
print(semantic_cache_query("연차는 어떻게 사용하나요?"))
# → ⚡ 캐시 히트! (유사도: 92.1%) (유사 질문, 즉시 응답)시맨틱 캐싱 설계 시 고려사항
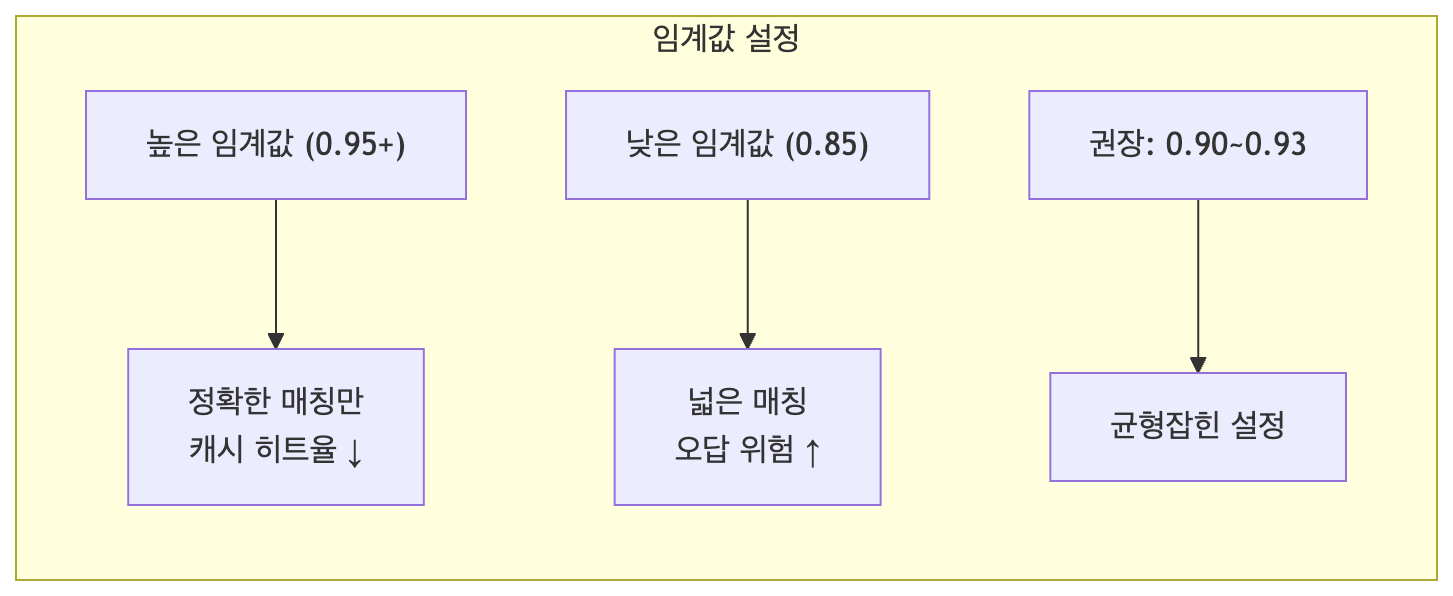
| 고려사항 | 설명 | 권장값 |
|---|---|---|
| 유사도 임계값 | 너무 낮으면 다른 질문에 잘못된 답변 | 0.90 ~ 0.93 |
| 캐시 만료 | 오래된 정보 방지 | 24시간 ~ 7일 |
| 캐시 크기 | 메모리/스토리지 관리 | LRU 정책 적용 |
| 질문 정규화 | "뭐야", "뭔가요" 등 통일 | 전처리 적용 |
시맨틱 캐싱이 효과적인 경우
✅ 효과가 큰 경우:
- FAQ 챗봇 (반복 질문 많음)
- 고객 지원 시스템
- 사내 문서 QA (유사 질문 패턴)
- 트래픽이 많은 서비스
❌ 효과가 적은 경우:
- 매번 다른 창의적 질문
- 실시간 데이터 필요 (주가, 날씨)
- 개인화된 답변 필요비용 절감 시뮬레이션
📊 월 10만 건 질문 기준 (캐시 히트율 60% 가정)
일반 RAG:
- 100,000 × $0.02 = $2,000/월
시맨틱 캐싱 적용:
- 캐시 미스: 40,000 × $0.02 = $800
- 캐시 히트: 60,000 × $0 = $0
- Vector DB 비용: ~$50
- 총: $850/월
💰 절감액: $1,150/월 (57.5% 절감!)📊 성능 벤치마크
1000만 벡터 기준 (768차원)
| DB | 쿼리 지연시간 | Recall@10 | 메모리 사용 |
|---|---|---|---|
| Pinecone | 5-10ms | 99%+ | 관리형 |
| Qdrant | 8-15ms | 99%+ | 효율적 |
| Milvus | 10-20ms | 99%+ | 높음 |
| Weaviate | 15-25ms | 98%+ | 높음 |
| ChromaDB | 20-50ms | 97%+ | 보통 |
| pgvector | 30-100ms | 95%+ | 보통 |
⚠️ 실제 성능은 하드웨어, 설정, 데이터 특성에 따라 다름
🎯 선택 가이드
상황별 추천
| 상황 | 추천 | 이유 |
|---|---|---|
| 빠른 프로토타입 | ChromaDB | 5분 안에 시작 |
| 스타트업 MVP | Pinecone Free | 무료 + 관리형 |
| 프로덕션 (소규모) | Qdrant Cloud | 비용 효율적 |
| 프로덕션 (대규모) | Pinecone / Milvus | 안정성 + 확장성 |
| PostgreSQL 기존 사용 | pgvector | 인프라 통합 |
| 멀티모달 검색 | Weaviate | 모듈 확장성 |
| 엣지/모바일 | LanceDB | 임베디드 |
🛠️ 실전 RAG 파이프라인 예시
LangChain + ChromaDB
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# 1. 문서 로드
loader = TextLoader("company_docs.txt")
documents = loader.load()
# 2. 청킹
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_documents(documents)
# 3. 임베딩 & 저장
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(chunks, embeddings, persist_directory="./db")
# 4. RAG 체인 구성
llm = ChatOpenAI(model="gpt-4")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(search_kwargs={"k": 3})
)
# 5. 질문
answer = qa_chain.run("회사의 휴가 정책이 어떻게 되나요?")
print(answer)LangChain + Pinecone
from langchain.vectorstores import Pinecone
from langchain.embeddings import OpenAIEmbeddings
import pinecone
# Pinecone 초기화
pinecone.init(api_key="YOUR_KEY", environment="us-east-1")
# 벡터스토어 생성
embeddings = OpenAIEmbeddings()
vectorstore = Pinecone.from_documents(
documents=chunks,
embedding=embeddings,
index_name="my-index"
)
# 검색
docs = vectorstore.similarity_search("검색 쿼리", k=5)📝 정리
Vector DB 핵심 요약
| 항목 | 내용 |
|---|---|
| 정의 | 벡터(임베딩)를 저장하고 유사도 검색하는 DB |
| 핵심 용도 | RAG, 시맨틱 검색, 추천 시스템 |
| 주요 알고리즘 | HNSW, IVF, PQ |
| 선택 기준 | 규모, 예산, 운영 능력, 기능 |
최종 추천
🏃 빠른 시작:
→ ChromaDB (로컬, 무료, 5분 세팅)
💼 프로덕션 (운영팀 없음):
→ Pinecone (관리형, 안정적)
💰 비용 효율:
→ Qdrant (오픈소스 + 클라우드)
🏢 엔터프라이즈:
→ Milvus (대규모, 완전 통제)
🐘 기존 PostgreSQL:
→ pgvector (인프라 통합)📚 참고 자료

누군가에게 도움을 주기 위한 개발자로 성장하고 싶습니다.