the graph란
the graph는 이더리움을 시작으로 블록체인으로부터 데이터 인덱싱과 쿼리를 위한 탈중앙화 프로토콜이다. 바로 쿼리 날리기 어려운 데이터에 쿼리를 가능하게 해준다.
인기있는 CryptoKitties dApp을 예로 들면 상대적으로 다음 질문을 하기 쉽다.
특정 계정이 소유한 CryptoKitties 가 얼마나 많은지? 특정 CryptoKitty 가 언제 태어났는지?
읽기 패턴들은 콘트랙트에 의해 노출된 balanceOf, getKitty 메소드들에 의해 지원되기 때문이다.
그러나 다른 질문은 답하기 어렵다.
특정 기간 내에 태어난 CryptoKitties의 주인이 누구인가?
이 질문에 답하기 위해 birth 이벤트를 처리해야 하고 ownerOf 메서드를 태어난 각 CryptoKitty에 대해 호출해야 한다.
상대적으로 간단한 질문임에도 답을 얻기 위해 브라우저에서 실행되는 탈중앙화된 앱은 수 시간, 수 일이 걸린다. 인덱싱 블록체인 데이터는 어렵다. 완결성, 체인 재구성, uncled blocks 같은 블록체인 속성들은 블록체인 데이터에서 올바른 쿼리 결과를 검색하는데 시간이 더 많이 소요되게 할 뿐만 아니라 개념적으로도 어렵게 한다.
the graph는 블록체인 데이터를 인덱싱하는 호스트 서비스로 문제를 해결한다. 이런 인덱스들를 표준 graphQL API로 쿼리할 수 있다. 미래에 호스트 서비스는 동일 능력의 완전 탈중앙화 프로토콜로 진화할 것이다.
어떻게 the graph가 동작하는가
the graph는 subgraph manifest라고 하는 subgraph 설명을 기반으로 이더리움 데이터를 인덱싱하는 항목과 방법을 학습한다. 하위 그래프 설명은 하위 그래프에 대한 관심 스마트 계약, 주의를 기울여야 하는 해당 계약의 이벤트 및 그래프가 데이터베이스에 저장할 데이터에 이벤트 데이터를 매핑하는 방법을 정의합니다.
하위 그래프 매니페스트를 작성한 후에는 Graph CLI를 사용하여 IPFS에 정의를 저장하고 호스팅된 서비스에 해당 하위 그래프에 대한 데이터 인덱싱을 시작하도록 지시합니다.
뭔가 설명이 어렵다...
다음 단계로 진행된다.
1. 탈중앙화 앱은 스마트 콘트랙트에 있는 트랜잭션을 통해 이더리움에 데이터를 추가한다.
2. 스마트 콘트랙트는 트랜잭션을 처리하는 동안 하나 이상의 이벤트를 방출한다.
3. Graph Node는 포함될 수 있는 새 블록들을 위한 이더리움과 하위 그래프를 위한 데이터를 검색한다.
4. 그래프 노드는 이 블록들에서 하위 그래프에 대한 이더리움 이벤트를 찾고 매핑 핸들러를 실행한다. 매핑은 이더리움 이벤트에 대한 응답으로 graph node가 저장하는 데이터 엔티티를 생성 또는 갱신하는 WASM 모듈이다.
5. 탈중앙화 앱은 노드의 graphQL endpoint를 사용해서 블록체인으로부터 인덱싱된 데이터에 대해 graph node를 쿼리한다. graph node는 이 데이터를 가져오기 위해 GraphQL 쿼리를 기본 데이터 저장소에 대한 쿼리로 변환하여 저장소의 인덱싱 기능을 사용한다. 분산형 애플리케이션은 이 데이터를 최종 사용자를 위한 풍부한 UI로 표시하며, 최종 사용자는 이 데이터를 사용하여 이더리움에서 새로운 거래를 발행한다. 주기가 반복된다.
REST API에는 많은 end point가 있고 frontend에서는 이를 조합해야하는데 느리고 복잡하다.
the graph는 단일 end point가 있다. 단일 쿼리로 여러 데이터를 묶을 수 있다.
api를 만들기 위해 the graph가 graphql을 어떻게 사용할까?
the graph는 sub graph의 id 기반으로 생성된다.
sub graph는 블록체인으로부터 어떤 데이터를 가져올지 결정하는 방법이다.
graph node에 여러 개의 sub graph가 추가될 수 있다.
subgraph 작성방법
Graph CLI 설치, Subgraph 초기화 후에 Subgraph를 작성한다.
Manifest (subgraph.yaml) : 매니페스트는 서브그래프가 인덱스할 datasources를 정의한다.
Schema (schema.graphql) : graphql schema는 서브그래프로부터 추출할 데이터를 정의한다. 스키마에 적힌대로 graphql을 써서 쿼리할 수 있다.
AssemblyScript (mapping.ts) : 이 코드는 datasources의 데이터를 schema에 정의한 entities로 변환한다.
그래프 노드는 manifest의 datasources를 바탕으로 새 블록에 포함될 수 있는 서브그래프에 대한 데이터를 스캔한다. 서브그래프의 이벤트를 찾고 매핑 핸들러를 실행한다. 데이터 엔티티를 저장, 갱신한다.
백엔드에서 API 요청이 오면 미리 지정된 엔티티에 맞게 DB에 값을 저장하는 것과 비슷하다.
graph node = server
네트워크의 event = API 요청
schema, entity = orm schema, entity
assembly script handler = repository의 CRUD 메서드
subgraph 배포
github 로그인 -> hosted service -> 정보 입력
subgraph 프로젝트 터미널에서 명렁어 실행
yarn codegen
graph auth --product hosted-service <ACCESS_TOKEN>
graph deploy --product hosted-service <GITHUB_USER>/<SUBGRAPH NAME>query
the graph playground를 통한 graphQL 요청
playground
쿼리가 json같아 보이지만 graphql 언어다. 화살표를 누르면 결과가 나오고 오른쪽엔 스키마가 있다.
graphQL이란
graph query language
server API로 정보를 주고 받는 것에 특화된 쿼리 언어
정보를 요청하는 쪽에서 원하는 형태로 쿼리할 수 있다
REST API와의 차이점
REST API로 요청해서 응답으로 온 데이터에 불필요한 값이 있을 수 있다. 경우의 수를 고려해서 응답을 짜기엔 너무 수가 많다.
여러 데이터가 필요할 때 REST API에서 여러 번의 API 호출을 해야할 수도 있다. 이런 문제를 under-fetching이라고 한다. 여러 데이터를 받아서 조합해야 한다. 만약 3번의 API 호출을 했는데 서버에 문제가 생겨 특정 데이터를 받지 못했다면 결과를 만들어낼 수 없다.
API마다 다른 URL이 있기 때문에 하나하나 만들어야하고 매번 RESTful하게 URL을 만들기도 쉽지 않다.
graphql은 이러한 over-fetching, under-fetching 문제를 해결했다. graphql은 하나의 API 호출로 모든 요청을 커버할 수 있다.
graphql의 operation type
Query : 데이터 조회
Mutation : 데이터 수정
Subscription : 실시간 앱 구현 시 사용
graphql은 API 테스트를 위한 UI를 제공한다.
요청하는 쪽에서 어떤 API를 사용하고 어떤 데이터가 필요한지 작성하면 된다.
같은 이름의 API를 동시에 호출하면 에러가 발생하는데 API 앞에 임의의 식별자를 적어주면 된다.
장단점
REST API : 요청은 쉽지만 여러 번 요청하고 응답을 조합해야 함
GraphQL : 요청 쿼리는 일일이 작성해야하지만 응답 데이터는 쿼리에 맞게 한번에 온다
graphql 강좌
apollo는 graphql 테스트를 돕는 UI다.
id, manager 외에 값을 추가하거나 값을 제외시켜도 응답이 잘 온다. 필요한 데이터만 요청할 수 있으므로 over-fetching, under-fetching을 막는다.
query {
teams {
id
manager
}
}계층적인 정보도 한번의 쿼리로 가져올 수 있다.
query {
teams {
members {
name
}
}수정 mutation을 사용한다
mutation {
postTeam (input: {
manager: "A"
}) [
manager
]
}삭제도 mutation을 사용한다.
mutation {
deleteTeam (id: 1) {
id
}
}graphql은 하나의 URL에 post로 모든 요청을 처리할 수 있다.
Apollo란?
GraphQL은 REST API처럼 하나의 명세, 형식이다.
GraphQL에 맞게 요청, 응답하도록 하는 걸 만들어야 한다. Apollo는 GraphQL 요청이 들어오면 그에 맞게 DB의 데이터를 가져다 가공해서 응답하도록 도와준다.
Apollo는 프론트엔드, 백엔드 모두 지원한다.
Apollo 서버 구축
npm init으로 프로젝트 초기화한다.
index.js 파일에 console.log('')를 작성한다.
터미널에서 nodemon index.js를 입력한다.
package.json 파일에 start 명령어를 추가한다. npm start를 입력하면 nodemon index.js가 실행된다.
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "nodemon index.js"
},mock 데이터 추가, csv 파일과 .js 파일을 프로젝트 디렉토리로 이동
npm i convert-csv-to-json 패키지 설치
index.js 코드 수정
const database = require('./database')
console.log(database)서버 실행 후 로그 확인
서버 종료 후 npm i apollo-server로 패키지 설치
index.js 파일에 아래 코드 대체하고 서버 실행. http://localhost:4000으로 접속하면 playground가 뜸
const database = require('./database')
const { ApolloServer, gql } = require('apollo-server')
const typeDefs = gql`
type Query {
teams: [Team]
}
type Team {
id: Int
manager: String
office: String
extension_number: String
mascot: String
cleaning_duty: String
project: String
}
`
const resolvers = {
Query: {
teams: () => database.teams
}
}
const server = new ApolloServer({ typeDefs, resolvers })
server.listen().then(({ url }) => {
console.log(`🚀 Server ready at ${url}`)
})playground에 아래 쿼리 입력 후 실행
query {
teams {
id
manager
office
extension_number
mascot
cleaning_duty
project
}
}코드 설명
ApolloServer 클래스는 typeDefs, resolvers를 인자로 받아 생성자를 생성해 server에 할당한다.
typeDef : graphql 명세에서 사용될 데이터, 요청의 타입 지정
resolver : 서비스의 액션들을 함수로 지정, 요청에 따라 데이터를 crud함
query 루트 타입
쿼리 정의. 반환될 데이터 형태 지정. 배열 내에 Team이 있다.
teams 쿼리를 날리면 여러 개의 Team 객체가 반환된다.
type Query {
teams: [Team]
}type
Team 객체는 key, 자료형으로 구성된다.
type Team {
id: Int
manager: String
office: String
extension_number: String
mascot: String
cleaning_duty: String
project: String
}resolver
쿼리를 수행하는 함수다. database에 있는 모든 teams를 반환하는 함수
const resolvers = {
Query: {
teams: () => database.teams
}
}query 짜기
database의 객체를 출력해서 어떤 key가 있고 value는 어떤 타입인지 확인한다. 반환 시 어떤 형태로 반환할지 typeDefs에 명시한다. 이 Equipment를 query root에 추가해야 한다.
const typeDefs = gql`
type Query {
equipments: [Equipment]
}
type Equipment {
id: String
used_by: String
count: Int
new_or_used: String
}
`resolver 작성
const resolvers = {
Query: {
equipments: () => database.equipments
}
}조건을 넣어 특정 값 쿼리
parent, args, context, info 4가지 인자를 넣고 특정 테이블에서 어떤 값들을 필터링할지 정한다. args에는 id가 있다. args의 id에 해당되는 것을 가져온다.
const typeDefs = gql`
type Query {
teams: [Team]
team(id: Int): Team // root query에 team을 추가하고 파라미터로 Int형 id를 받는다고 명시한다. 응답은 단일 Team 객체다.
equipments: [Equipment]
}
const resolvers = {
Query: {
teams: () => database.teams,
team: (parent, args, context, info) => database.teams.filter((team) => {
return team.id == args.id;
})[0], // 인자 중 하나인 id와 team의 id가 같은 것만 필터링해서 0번째 원소를 반환한다.
equipments: () => database.equipments
}
}다음 쿼리로 특정 team을 가져올 수 있다.
query {
team(id: 1) {
id
}
}객체의 하위 객체를 함께 가져오기
Team 객체 내에 다수의 Supply 객체를 넣을 것이므로 query root에supplies: [Supply]를 추가한다.
resolvers에서는 팀 각각에 대해 팀에 속하는 supply를 필터하고 supplies 속성을 추가해서 team 배열을 반환한다.
const typeDefs = gql`
type Query {
teams: [Team]
team(id: Int): Team
equipments: [Equipment]
supplies: [Supply]
}
type Team {
id: Int
manager: String
office: String
extension_number: String
mascot: String
cleaning_duty: String
project: String
supplies: [Supply]
}
type Supply {
id: String,
team: Int
}
`
const resolvers = {
Query: {
teams: () => database.teams
.map((team) => {
team.supplies = database.supplies
.filter((supply) => {
return supply.team === team.id
})
return team
}),
}데이터 삭제하기
mutation은 수정, 삭제를 하게 해준다.
mutation root에 타입을 추가한다.
deleteEquipment를 호출하면 문자열 id를 인자로 받고 Equipment를 반환한다.
resolvers에 Mutation을 추가한다. 삭제할 객체를 deleted에 넣고, database.equipments 속성에 삭제할 id는 제외하고 나머지 equipments를 할당한다.
const typeDefs = gql`
type Mutation {
deleteEquipment(id: String): Equipment
}
`
const resolvers = {
Mutation: {
deleteEquipment: (parent, args, context, info) => {
const deleted = database.equipments
.filter((equipment) => {
return equipment.id === args.id
})[0]
database.equipments = database.equipments
.filter((equipment) => {
return equipment.id !== args.id
})
return deleted
}
}
}데이터 추가하기
Mutation root에 다음을 추가한다.
insertEquipment(
id: String,
used_by: String,
count: Int,
new_or_used: String
): Equipmentresolvers의 Mutation 속성에 다음 메서드를 추가한다. 입력된 args는 equipments에도 있으므로 그대로 push한다.
insertEquipment: (parent, args, context, info) => {
database.equipments.push(args)
return args
}추가하는 쿼리
mutation {
insertEquipment (
id: "laptop",
used_by: "developer",
count: 17,
new_or_used: "new"
) {
id
used_by
count
new_or_used
}
}데이터 수정하기
editEquipment(
id: String,
used_by: String,
count: Int,
new_or_used: String
): Equipment
editEquipment: (parent, args, context, info) => {
return database.equipments.filter((equipment) => {
return equipment.id === args.id
}).map((equipment) => {
Object.assign(equipment, args)
return equipment
})[0]
}쿼리
mutation {
editEquipment (
id: "pen tablet",
new_or_used: "new",
count: 30,
used_by: "designer"
) {
id
new_or_used
count
used_by
}
}모듈화하기
하나의 파일에 모든 로직을 넣으면 관리, 재사용이 어렵다.
디렉토리 구조는 다음처럼 구성했다.
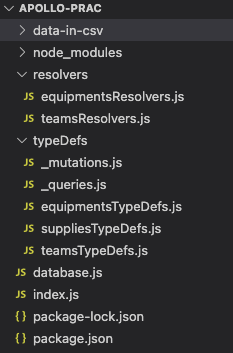
index.js에서는 query root, mutation root, 나머지 typeDefs, resolvers를 import해서 사용한다.
typeDefs 디렉토리에 query root, mutation root, typeDefs를 정의한다.
resolvers에는 query, mutation 동작을 정의한다.
