Project
1.프로젝트 개발 효율성을 위한 CI/CD 적용 과정
이전에 개발을 하면서 수동으로 배포를 해왔습니다. 항상 EC2에 접속을 해서 git으로 프로젝트를 다운로드를 받고 build를 실행을 시키는 반복적인 과정을 진행을 해왔습니다. 이런 과정는 시간이 항상 많이 소요가 되었고 배포에 대한 피로도 높았습니다.이번에는 낭비와
2.대용량 트래픽이 오면 서버를 어떻게 확장을 하는게 좋을까? - 대용량 트래픽(1)
제가 하고 있는 프로젝트는 스포츠나 뮤지컬 같은 공연을 애매를 하는 프로젝트입니다.애매 프로젝트의 특징은 애매가 시작이 되면 많은 사용자가 애매를 하기 위해서 몰리기 때문에 그에 따라 트래픽이 증가를 합니다. 트래픽이 증가를 할 수록 이를 감당하는 서버는 버거워지기 시
3.서버 분산 처리 과정에서 발생하는 데이터 Session 불일치 문제를 어떻게 해결할까? - 대용량 트래픽(2)
지난 포스트에서 서버 확장에 방법으로 Sacle Out이 더 적합하다는 판단을 내렸습니다.하지만 Scale Out이라는 방식은 테이터 불일치라는 문제가 남아있습니다. 그렇다면 데이터 불일치 문제는 무엇일까요?데이터 불일치은 서버가 여러대 일때, 서버 간의 session
4.[Project] 인기 검색어 동시성 문제 해결하기
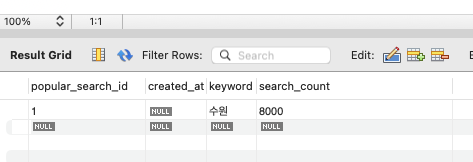
내가 예상한 것과 DB에 저장이 된 게 다르네,,, 프로젝트를 진행을 하면서 인기 검색어를 구현을 하게 되었습니다. 인기 검색어는 사용자가 검색을 한 단어를 DB에 저장을 하고 그 단어가 검색이 될 때마다 카운트를 올려서 1씩 증가를 하도록 했습니다. 그런데 이 부분에
5.[Project] Redis로 동시서 제어하기 - SETNX

저번 포스트에서는 인기검색어를 구현을 하는데 있어서 Synchronized 키워드와 Optimistic Lock, Pessimitic Lock을 사용하고 어느 방법이 현재 프로젝트에 적합한 지를 알아 보았습니다. 그리고 Pessimitic Lock을 사용하는 것이 현재
6.[Project] Redis로 동시성 제어하기 - Spin Lock
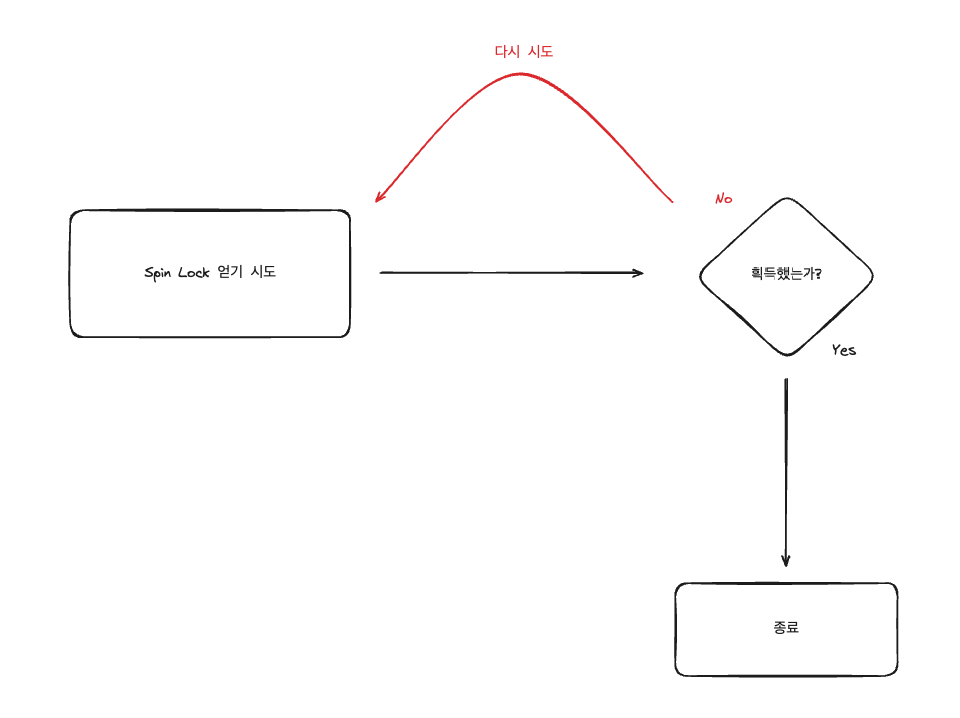
이전 포스트에서는 Redis에서 기본으로 제공을 하는 원자성 명령어를 통해서 동시성을 제어하는 법을 알아보고 프로젝트에 적용을 해보았습니다. 하지만 작업을 하려던 스레드가 Lock을 획득을 하지 못 했을 때, 작업을 중단이 되면서 인기 검색어의 count를 올리는 작업
7.[Project] In-Memory-Database와 JWT 토큰 - 대용량 트래픽 (3)
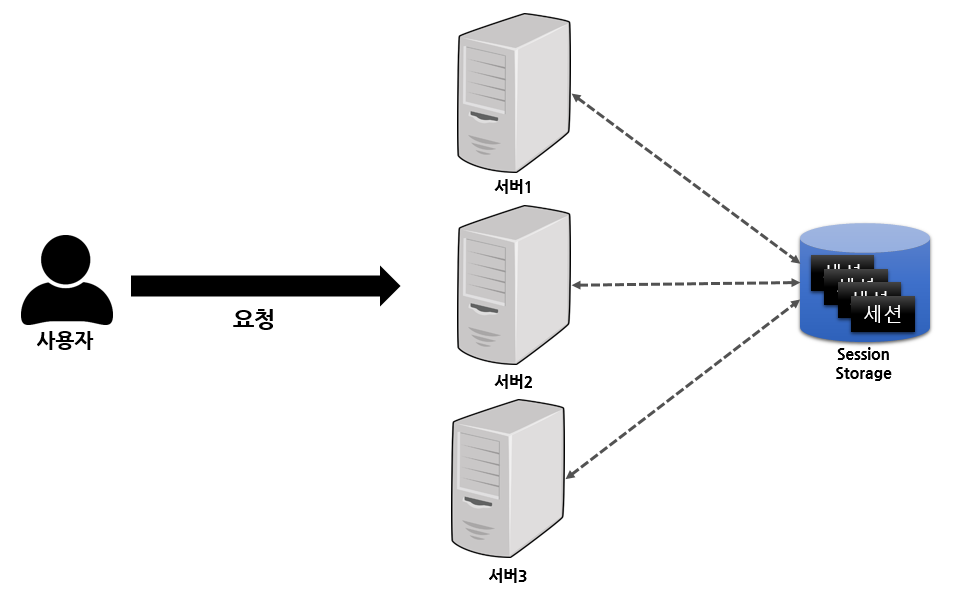
저번 포스트에서는 Scale Out의 세션 불일치 문제의 해결 방식으로 Sticky Session, Session-Clustering의 대해서 알아보았습니다. Sticky Session의 경우, 고정된 사용자와 서버를 사용하기 때문에 오히려 트래픽이 더 늘어나 Scal
8.[Project] Redisson을 이용한 좌석 선택 동시성 제어하기

보통 예매를 하는 애플리케이션을 보면 좌석을 선택하고 예매를 합니다. 좌석을 선택하게 되면 다른 이용자는 좌석을 선택을 하지 못하게 됩니다. 이번 프로젝트에서도 이 플로우를 따라 갑니다. 먼저, 이용자가 좌석을 선택을 하고 예매를 합니다. 근데 여기서 한 가지 주의를
9.[Project] Redisson 분산 락 AOP 적용
지난 시간 Redisson 분산락을 구현을 해보았습니다. 그리고 이 분산 락을 통해서 동시성 제어를 했습니다. 여기서 한 가지 더 발전을 시켜보고 싶었던 부분은 가독성과 재사용성이었습니다. 코드를 보면 좌석을 선택을 하는 비지니스 로직과 동시성을 제어를 하는 분산 락
10.[Project] redis로 성능 개선 하기
이번 포스트에서는 카테고리로 이벤트를 조회하는 api의 성능을 개선을 해보려고 합니다. 예매 프로젝트 특성 상 티켓 예매가 오픈이 되는 날 많은 사용자가 이벤트를 조회를 하는 경우가 발생을 하는데 조회가 느려지면 사용자에게 불편함을 줄 수 있다고 판단을 하였습니다. 성
11.[Project] 프로젝트에서 Test Fixture를 어떻게 사용할 지 고민해보기
프로젝트를 진행을 하면서 테스트 코드를 작성을 해왔습니다. 그러면 자연스럽게 테스트를 위한 Fixture를 쓰게 되었습니다. 사용을 하면서 아무 생각 없이 사용을 하고 있었습니다. 그런데 사용을 하면서 Fixture를 작성을 하면서 코드가 길어지고 가독성이 떨어지는 것
12.[Project] Facade 패턴으로 의존성 개선하기

프로젝트를 진행을 하면서 event의 service단을 작업을 하고 있었습니다. event를 생성하고 수정을 하는 과정에서 필드의 다른 엔티티들이 필요로 하다보니 event의 service단에서 repository들을 의존을 하는 것이 굉장히 컸습니다. 의존을 많이 하