JDK 6에서는 동시성 효율이 크게 증가하였다.
적응형 스핀, 락 제거, 락 범위 확장, 경량 락, 편향 락 등 다양한 락 최적화 기술을 구현하는 데 많은 자원을 투자했다.
스핀 락과 적응형 스핀
이전 포스팅에서 상호 배제 동기화가 성능에 악영향을 주는 주된 원인은 블로킹이라고 언급했었다. 스레드를 일시 정지시키고 재개하려면 커널 모드로 진입해야 하기 때문에 동시성 성능에 부담을 주기 때문이다.
하지만, 분석 결과 수많은 애플리케이션이 공유 데이터를 아주 잠깐만 잠궜다가 곧바로 해제한다는 사실을 알게 되었다. 이 찰나의 시간에 스레드를 멈췄다 재개하는건 의미가 없다. 오늘날의 컴퓨터는 거의 다 멀티코어 시스템이며, 스레드를 둘 이상 병렬로 실행할 수 있어 대기 상태로 들어가지 않고도 원하는 락이 해제되는지 옆에서 지켜볼 수 있기 때문이다.
하지만 스핀 락은 블로킹 방식을 완전히 대체하지는 못한다. 스레드 전환 부하는 없애지만 락 시간이 길다면 프로세서 시간을 소비하는 부작용이 따르기 때문이다. 그래서 스핀 락에는 스핀하는 횟수를 정해 놓는다. 이는 옛날에는 사용자가 정할 수 있었지만 JDK 6부터는 적응형 스핀 락을 도입해 스핀의 성공 여부에 따라 횟수를 조정한다.
락 제거
락 제거는 특정 코드 조각에서 런타임에 데이터 경합이 일어나지 않는다고 판단되면 가상 머신의 JIT 컴파일러가 해당 락을 제거하는 최적화 기법이다.
락을 제거할지에 대한 여부는 주로 탈출 분석에서 얻으며, 코드 조각에서 모든 데이터가 탈출하지 않고 다른 스레드에서 접근하지 않는다고 판단디면 마치 스택에 있는 데이터처럼 취급할 수 있다. 스택의 데이터는 오직 한 스레드만이 접근하므로 동기화 할 필요가 없다.
락 범위 확장
원칙적으로 코드를 작성할 때는 동기화 블록의 범위를 가능한 한 좁게 줄이는 게 좋다. 이러면 동기화된 상태에서 수행해야 할 연산의 수가 최소화되며, 이 덕분에 경합이 생기더라도 스레드들이 최대한 락을 짧게 쓰고 건네주어 전체적인 대기 시간이 줄어든다. 이 원칙은 대부분의 상황에서는 옳지만 연이은 다수의 작업이나 순환문에서 똑같은 락 객체를 잠그는 일련의 단편적인 작업들을 발견하면 락의 유효 범위를 해당 작업 전체로 늘릴 수 있다.
경량 락
경량 락도 JDK 6때 추가되었으며, 이는 운영 체제의 뮤텍스를 이용해 구현한 기존 락보다 가볍다는 뜻이다.
경량 락은 중량 락(기존의 락)을 대체하기 위해 나온 건 아니고, 스레드 경합을 없애 뮤텍스를 사용하는 기존 중량 락의 성능 저하를 줄이는 목적으로 나왔다.
경량 락과 편향 락을 이해하기 위해서는 핫스팟 가상 머신에서 객체가 메모리에서 어떻게 표현되는지 알아야 한다. 핫스팟 가상 머신의 객체 헤더는 두 부분으로 나뉜다.
첫 번째 부분은 해시 코드와 GC 세대 나이 등 객체 자신의 런타임 데이터를 저장한다.
이 부분을 마크 워드라고 하며 편향, 경량 락 구현의 핵심이다.
두 번째 부분은 메서드 영역의 데이터 타입 데이터를 가리키는 포인터를 저장한다. 배열 객체인 경우 배열 길이를 저장하는 항목이 추가된다.
객체 헤더의 마크 워드는 다음과 같은 형식으로 되어있다.

객체의 락 상태는 다음과 같이 5가지가 있다. 이제 경량 락이 어떻게 동작하는지 알아보자.
만약 코드가 동기화 블록에 진입하려할 때, 락 객체가 잠겨있지 않다면(락 플래그가 01) 가상 머신은 가장 먼저 현재 스레드의 스택 프레임에 락 레코드를 생성한다.
락 레코드는 현재 마크 워드의 복사본으로, 소유한 락 객체를 저장하는 용도의 공간이다.
아래 그림은 이때의 스레드 스택과 객체 헤더의 모습이다.
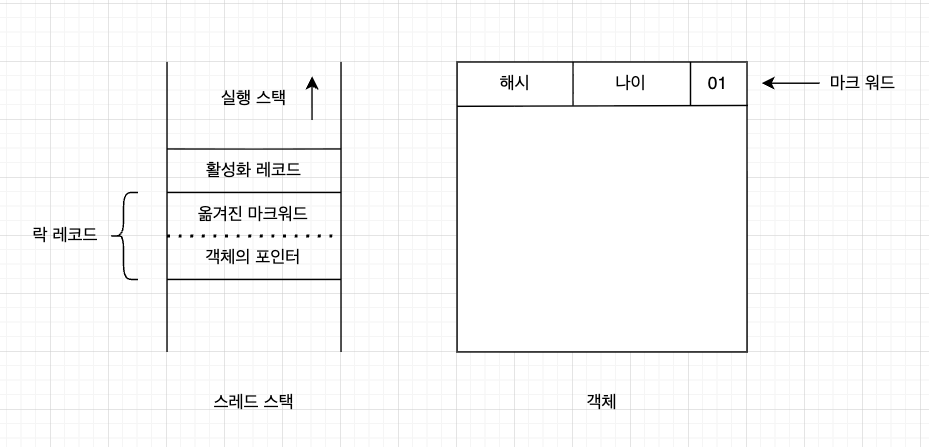
이제 메서드가 동기화 블록에 진입하면, 가상 머신은 CAS연산으로 락 객체의 마크 워드를 락 레코드를 가리키는 포인터로 바꾼다. 변경에 성공하면 락 획득이 성공한 것이고, 마크 워드의 락 플래그를 00으로 바꿔 객체가 경량 락 상태에 있음을 표시한다. 이때의 스레드 스택과 객체 헤더는 다음과 같다.
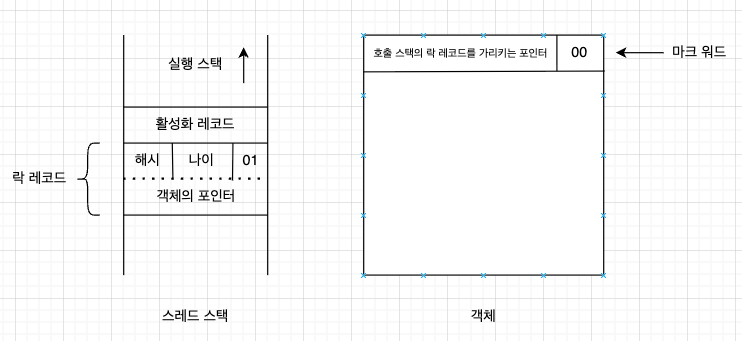
만약 변경에 실패한다면 같은 객체를 놓고 경쟁하는 스레드가 최소 하나는 더 있다는 뜻이고, 이때 가상 머신은 먼저 락 객체의 마크 워드가 현재 스레드의 스택 프레임을 가리키는지 확인해 이미 객체의 락을 얻었는지 확인한다. 그렇지 않다면, 다른 스레드가 있다는 뜻이므로 경량 락은 더 이상 유효하지 않다.
객체의 마크 워드의 락 플래그를 10으로 변경해 중량 락으로 변경 후 블록된다.
락 해제도 동일하게 CAS 연산을 이용하여 실행된다. 객체의 마크 워드가 여전히 스레드의 락 레코드를 가리키고 락 플래그가 00이라면, CAS 연산으로 객체의 현재 마크 워드와 옮겨진 마크 워드를 교체한다. 만약 실패한다면 이는 다른 스레드가 락을 얻으려 했었고, 블록된 스레드가 다시 깨어나야 한다는 의미이다.
경량 락은 "대부분의 락은 실제로는경합을 겪지 않는다" 라는 경험 법칙에 의해 프로그램의 동기화 성능을 개선할 수 있다. 하지만 경합이 많다면 뮤텍스 부하에 더해 CAS연산까지 더해 전통적인 중량 락보다 오히려 느려진다.
편향 락
편향 락은 경합이 없을 때 데이터의 동기화 장치들을 제거하여 프로그램 실행 성능을 높이는 최적화 기법이며 CAS 연산마저 쓰지 않게 하여 전체 동기화를 없앤다.
편향 락에서 "편향"은 락을 마지막으로 썼던 스레드가 락을 찜해둔다는 의미이다. 다음번 실행 시까지 다른 스레드가 락을 가져가지 않으면 직전에 사용한 스레드는 다시 동기화 할 필요가 없다.
편향 락이 활성화된 가상 머신에서는 어떤 스레드가 락 객체를 처음 획득하면 가상 머신이 객체 헤더의 락 플래그를 01로, 편향 모드를 1로 설정한다. 그리고 락을 얻은 스레드의 아이디를 마크 워드에 기록한다. 이때 CAS 연산을 사용한다. CAS 연산이 성공하면 편향 락을 소유한 스레드는 아무런 동기화 작업 없이 해당 동기화 블록에 몇 번이고 진입할 수 있다.
그러다가 다른 스레드가 락을 얻으려 시도하는 즉시 편향 모드가 종료된다. 락 객체가 현재 잠긴 상태인지에 따라 편향을 해제할지 여부를 결정한다.
편향 락은 JDK 15 이후부터 삭제되었다. 많은 단점들이 존재하기 때문이다.
마치며
여기까지 락에 대해 알아보았고 JDK 끝까지 알아보기도 전부 읽었다. 아직은 실무도 가보지 않았기 때문에 모든 내용이 가깝게 느껴지진 않았지만, 2~4장, 12~13장의 내용들은 공부하면서 참 도움이 많이 된 것 같다. 아직 읽지 않은 사람들은 읽어보면 큰 도움이 될 것이다.
