프로그래밍 언어는 용도에 따라 많은 종류가 있으며, 각기 다른 특성을 지니지만 공통적으로 가지는 특성도 있다.
기본적으로 컴퓨터라는 하드웨어를 제어하기 때문에 결국에는 기계어로 번역되어야 하는데, High level 에서 기계어까지 가는 과정이 언어마다 다르다.
예를 들어 c언어의 경우.c 파일을 컴파일할 때 type checking 을 통해 잘못된 타입들을 다 찾아내서 런타임에는 타입 에러가 뜨지 않도록 하지만 파이썬은 런타임에 type checking 을 한다. 이렇게 런타임에 타입 체크를 하면 flexibility 가 올라가지만 런타임 동안에 어떤 변수가 어떤 타입인지 그 변수의 헤더에 저장을 해놔야 하기 때문에 시간적, 공간적으로 손해를 본다.
이런 식으로 언어 차원에서 support 해주는 기능들이 모두 다른데, 기능마다 장점과 단점이 존재한다.
대체로 프로그래머가 쓰기 쉽게 해주면 성능이 떨어지는 경향이 있고, flexibility 를 높이면 reliability 가 낮아지는 경향이 있다.
ex) 배열에 index를 통해 접근할 때 index bound를 체크 해주냐? 안 해주냐?
-> 이걸 체크하려면 배열의 크기와, 접근하려는 index를 가지고 boundary를 체크하는 assembly를 알아서 언어 차원에서 집어넣어줘야 한다. 그러면 실행 속도가 늦어진다.
-> 근데 안 해주면 reliability 가 낮아짐. 할당된 배열을 넘은 index를 맘대로 access 하면 프로그램이 정상 작동하지 않을 뿐더러 보안에도 위협이 있다.
1-1.
하드웨어에 맞게 프로그래밍 언어가 설계된 부분도 있고, 프로그래밍 언어에 맞게 하드웨어를 설계하는 경우도 있다.
CISC (Complex Instruction Set Computer) 는 high level 언어의 기능들을 빠르게 수행할 수 있도록 개발된 하드웨어이다. 예를 들어 프로그래밍 언어에서 배열이라는 타입을 만드니까 array accessing 을 빠르게 할 수 있도록 인덱싱을 지원하는 하드웨어를 만든 식이다.
근데 이렇게 high level 에 맞는 하드웨어를 개발하다 보니 CPU 안의 control memory 가 너무 많이 필요하게 되었다. 그래서 나온 게 RISC (Reduced Instruction Set Computer) . 구조를 간단하게 만들고 CPU 안에 레지스터를 넣은 하드웨어이다. 데이터는 결국 cpu 안에서 이동하면 가장 빠르고, 메모리에서 가져오면 그나마 빠르고, 디스크에서 가져오려면 비교하기 어려울 정도로 느리다. 그래서 그냥 instruction set을 줄여서 정해진 몇 안 되는 명령을 빠르게 memory 랑 왔다갔다 할 수 있게 만든 것.
1-2.
High level 언어를 기계어로 어떻게 번역할 것인가?
운영체제마다, 하드웨어마다 시스템이 모두 다르다. 그래서 high level 언어를 기계어로 번역하려면 매번 os와 하드웨어에 맞춰서 기계어를 작성해야 하는데, 이건 사실상 불가능하다.
그렇기 때문에 가상 머신을 사용하는데, 이건 하드웨어를 추상화 해놓은 소프트웨어라고 생각하면 된다. C언어를 기계어로 생각하는 가상 머신을 만들어 놓고, c 언어 프로그램 소스를 실행하면 어떤 os이든지 상관없이 같은 방법으로 작동하는 것이다.
Imperative language : 폰 노이만 컴퓨터를 추상화한 언어. 명령형 언어
5-1.
변수 : 메모리를 추상화하여 이름으로 접근할 수 있도록 함.
같은 이름의 변수라도 포함된 scope에 따라 실제 주소가 다를 수 있다.
한 변수를 두 가지 이상의 방법으로 access 하는 것을 aliase 라고 한다. (C언어 포인터)
변수의 타입은 그 변수의 값 범위와 연산의 종류를 결정한다.
같은 타입이라도 cpu에 따라 범위가 달라질 수 있다.
5-2.
Binding. 이름과 값을 연결하는 것.
Static binding : 런타임 전에 binding 되고, 프로그램 실행 동안 바뀌지 않는다. 예) C언어의 타입 바인딩. 한번 정수로 선언해 놓으면 프로그램 도는 동안에는 다른 타입으로 바꿀 수 없다.
Dynamic binding : 런타임 동안에 바인딩 되고, 바뀔 수 있다. ex) local variable 의 value binding.
Type binding.
static type binding. 컴파일 하면서 변수의 타입을 확정하고 바꿀 수 없다. 이렇게 하면 런타임에는 변수의 타입에 대해서는 아예 안 봐도 되기 때문에 성능이 올라가고, 타입에 관한 에러가 나지 않는 장점이 있다.
dynamic type binding. 변수가 처음 선언될 때 값을 보고 알아서 타입을 잡으며 실행되는 동안 바뀔 수 있다. 예를 들어 파이썬에서 a=1 라고 하면 알아서 정수로 잡고, "bc" + a 를 실행하면 알아서 "bc1" 이라는 문자열로 바꿔준다. Flexibility 가 크게 올라가지만, 에러를 찾기 어렵고 런타임 동안에 타입을 저장해야 해서 시공간적 손해를 본다.
바인딩 타임이라는 게 있다. 프로그래밍 언어를 실행할 때, 어느 시점에 "바인딩" 되는지를 말한다.
예를 들어, C 언어에서 type binding (변수의 타입을 바인딩) 은 컴파일 타임에 일어난다.
그럼 로컬 변수의 storage binding 은 언젤까? 런타임이다. 왜냐면 로컬 변수에 값을 할당하려면 런타임에 직접 그 변수의 값이 얼마로 선언되었는지를 봐야 되기 때문이다.
반면에 global variable 의 storage binding의 경우 로딩 타임 (컴파일하고 링크한 뒤, 실행시키기 전에 프로그램 로딩할 때) 이다. 왜냐면 글로벌 변수는 함수 바깥에 선언되어 있기 때문에 런타임 전에 이미 값을 알고 있기 때문이다.
5-3.
Type equivalence. 두 변수가 서로의 값을 할당받을 수 있으면 type compatible 이다.
두 타입이 coercion 없이 operator를 공통으로 사용할 수 있으면 두 타입은 서로 equivalence 하다.
- coercion 이란 자동으로 타입을 변환해서 연산해주는 기능이다. 정수와 실수를 더하면 프로그램이 알아서 정수를 실수로 변환해서 더하기를 해주는 것.
5-4.
Scoping.
- Static scoping, Dynamic scoping.
스태틱 스코핑은 프로그램의 구조만 보고 변수의 scope 를 설정하고, dynamic scoping 은 호출한 곳으로 따라가간다.
무슨 말이냐?
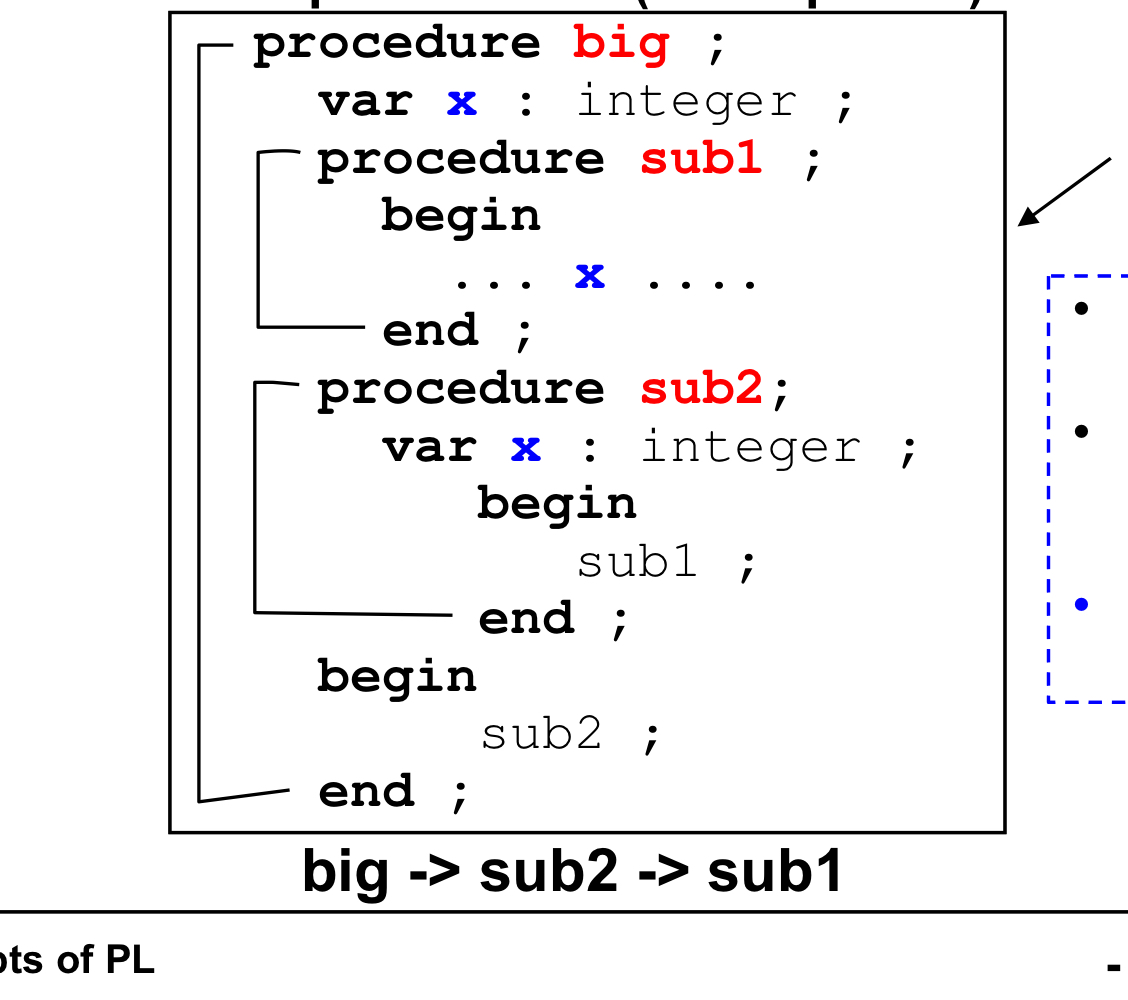
이런 프로그램이 있으면 static scoping과 dynamic scoping 에서 sub1 에서 x의 값이 달라진다.
프로그램이 실행되면 sub1은 sub2에서만 호출된다.
static scoping 의 경우 부모인 big 에서 선언된 x의 값을 가져오지만, (구조에 따름)
dynamic scoping은 sub2에서 sub1을 호출하면 sub1은 자신을 호출한 sub2로 올라가서 x의 값을 가져온다.
Primitive data types : 하드웨어가 직접 계산 가능한 데이터 타입
Integer : single memory word. word size 는 cpu에 따라 달라짐. 16bit cpu 는 word size 가 2byte, 32bit cpu는 word size 가 4byte. 1개의 sign bit (양수 음수) 와 31개의 비트로 구성됨
Floating poing : 실수 저장. 정확하게 저장할 수 없음. 1개의 sign bit, 8개의 exponent (지수부), 23개의 fraction (실수부) 로 구성됨. 1.xxx * 2^e 형태.
Decimal : 숫자 저장이 정확해야 되는 언어에서 사용된다. BCD (Binary Coded Decimal) 는 한 숫자를 4bit로 표현하는 방식이다. 20을 표현하려면 2와 0으로 나눠서 0010 0000 이런 방식. range를 낮추고 정확도를 올렸다. 실제로 메모리에 저장될 때는 1byte씩 쓰므로 000000010 00000000 으로 저장된다.
Boolean : true or false. single bit. 하지만 1byte로 저장 (1bit씩 저장하면 access 효율 낮아짐)
Character : 주로 ASCII 로 저장. 1byte 사용.
6-1.
Array
Raw major order : 2차원 배열이 있을 때 실제 메모리에 우리 머릿속 배열처럼 저장한다.
123
456
789
이런 배열이 있을 때 스택에 1 2 3 4 5 6 7 8 9 순서로 쌓인다는 말이다. 대부분 언어가 이렇게 한다.
Column major order : 열과 행 순서를 바꿔서 저장한다.
1 4 7 2 5 8 3 6 9 이 순서로 스택에 쌓는다.
메모리 접근 : 1차원 배열 A[10] 이 있으면 A[0] + sizeof(type) * n 식을 통해 n번째 원소의 주소에 접근한다.
2차원 배열 B[10][10] 이 있으면 B[0] + sizeof(type)i10 + sizeof(type)*j 를 통해 i 행 j열 원소의 주소에 접근한다.
6-2.
Record
C언어의 structure. 서로 다른 타입들을 모아놓음. 선언된 순서에 맞게 메모리가 할당되며, 이때 word size 기준으로 할당된다. 무슨말이냐? 예를 들어 structure 안에 char c, int i 순서로 들어있다고 치면 char의 크기는 1byte 이고 int 는 4 byte 니까 총 5byte를 쓸 것 같지만 그렇지 않다. char c가 1byte 지만 3byte를 비워서 4byte 를 맞추고, int 4byte 해서 총 8 byte를 차지한다.
왜냐면 만약 1, 4 byte 씩 차지하면 정수에 접근하려면 결국 2개의 word에 access 해야 한다. 바운더리에 걸치기 때문에 그렇다. 그래서 그냥 4byte씩 잘라서 주는 것.
6-3.
Union
이건 다른 데이터 타입들이 한 공간을 공유한다. 가장 큰 데이터 타입의 크기에 따라 크기가 결정된다.
그래서 만약 union 안에 int와 float 을 같이 선언하고 float 값을 넣어준 뒤 그냥 int 로 읽어버릴 수도 있다. 값은 잘못됐지만 결국 같은 주소 안에 쓰여진 데이터이기 때문에 읽히긴 한다.
Pointer
주소를 가리킴. 항상 word size 이다. 주소값을 가지기 때문.
문제점 :
Dangling pointer : 이미 해제된 메모리를 가리키는 포인터.
Lost object : 동적으로 할당된 메모리가 있는데 거길 가리키는 포인터가 해제되거나 다른 주소로 변경된 경우. 메모리는 할당되어 있는데 접근할 방법이 없다.
교수님 : 포인터는 마약이다. 쓰면 개꿀이지만 한번 쓰면 돌아갈 수가 없다. 근데 쓰레기다. C도 쓰레기 언어다
문제 해결 :
Tombstone approach : Dynamic variable 을 가리키는 tombstone을 생성해서, dynamic variable에 직접 접근하지 않고 tombstone 을 통해 값을 가져온다. 시공간 cost는 손해봄
Locks-and-key approach : 포인터와 dynamic variable 에 key 값을 매치시키고 서로 비교해가면서 키 쌍이 없을 경우 dangling pointer 또는 Lost object 를 찾아서 해제시켜 준다. 프로그래머가 알아서 메모리를 관리하는 방식.
Heap Management
힙 공간 용량 관리.
Reference Counte Approach : dynamic variable 을 가리키고 있는 포인터의 갯수를 카운트해서 0이면 해제
Garbage Collection : 가비지 콜렉터가 heap 영역에 있는, 제거할 가비지 메모리들을 모아서 해제한다. 이걸 위해서 모든 heap의 메모리 cell 들은 collection algorithm을 위한 추가적인 bit가 필요하다. 시공간적 cost 가 추가된다.
Operator Evaluation Order
연산자에 따른 계산 우선순위. 보통 계산 연산은 왼쪽->오른쪽, 값 할당은 오른쪽->왼쪽
Side effect : 어떤 변수에 값을 할당할 때 함수가 호출되어 리턴값을 사용하면, 함수 호출에 의해 global variable의 값이 바뀌어 영향을 미칠 수 있다. 이때 계산 순서가 중요해짐.
Overloaded operator : 연산자에 유저가 기능을 추가해서 오버로딩 할 수 있음
ex) '+' 연산자에 다른 기능 정의.
7-1.
Type Conversion.
Coercion : implicit type conversion. 컴파일러가 알아서 해줌
casting : explicit type conversion. 프로그래머가 직접 타입 변환
비교 연산의 경우 수학적 연산보다 낮은 우선순위를 가짐
Short-circuit evaluation : 곱 연산 중간에 0이 포함된 연산처럼, 중간에 종료해도 되는 연산이라고 판단되면 종료를 한다. 프로그래밍 언어에 따라 이렇게 하는 것도, 안 하는 것도 있음.
Statement-level control structures
control statement : 분기 또는 반복문. 조건에 따라 분기하든지, 다시 반복하든지.
Block : compound statement (collection of statements) and data declarations.
C 언어에서 { } 로 표현.
Selection statement : if else.
Iterative statement : 반복문.
logical : 루프 돌 때마다 조건과 비교해서 반복할지 결정
counting : 조건을 먼저 계산해서 몇 번 반복할지 결정한 뒤 반복
C 언어는 logical 만.
Unconditional branching : go to. 위험하다.
Guarded command : 둘 다 참이면 랜덤으로 실행한다.
if (조건1)
if (조건2)
이렇게 코드를 짜면 순서에 따라 우선순위가 생긴다. 조건1과 조건2를 모두 만족하더라도 항상 조건1에 해당하는 statement만 실행하기 때문에, 우선순위를 동등하게 하기 위해서 둘 다 만족시킬 경우 랜덤으로 분기하도록 함.
Subprogram
Procedure vs Macro.
Macro 는 compile 전에 code 를 카피해서, macro 가 들어있는 모든 부분에 코드를 갖다 넣는다. 수행 속도 cost 가 증가.
9-1.
Parameters
subprogram에서 필요한 data 에 access 하는 법은 두 개.
-
nonlocal variable에 직접 접근 : 별로 안 좋다.
-
parameter passing : 인자를 넘겨줘서 걔를 가지고 subprogram 실행. 거의 이렇게 함
formal parameters : subprogram header 에 있는 파라미터.
actual parameters : subprogram 호출 시에 전달되는 진짜 값을 가진 파라미터.
Parameter passing
Positional parameters : formal parameter의 위치에 맞게 호출할 때도 위치로 값을 전달
Keyword parameters : 전달될 parameter의 이름을 설정하고 호출할 때 subprogram(key=value) 이런 식으로 전달해줌
Procedure : return X
Function : return O
9-2.
Design Issues
- local variables 할당을 static? dynamic?
dynamic : recursion 가능. 런타임에 값을 할당하면서 가기 때문에 재귀적 호출 가능
static : 시작할 때 할당하고 시작하기 때문에 recursion 불가능.
- parameter type check?
넘겨주는 인자의 타입이 formal parameter 과 맞는지 체크를 해주는가?
-
subprogram을 파라미터로 전달 가능한가?
-
seperate or independent compilation ?
seperate compilation : 다른 정보가 있어야 컴파일 가능하다.
independent compilation : 다른 정보 없이도 부분적으로 컴파일이 가능하다.
C 의 컴파일 단위는 file.
Local referencing environments.
Stack-dynamic local variables : 스택으로 관리.
장점 : 재귀 호출이 가능하다. 메모리 관리가 용이하다. 호출된 순서에 따라 메모리 할당해줬다가 해제했다가 가능.
단점 : 스택에 메모리를 할당하고, 값을 넣고, 해제해주는 과정에서 cost 발생.
history-sensitive 하지 않다. 호출될 때마다 변수가 초기화되기 때문.
ex)
sub (int a) {
int k;
}
이런 subprogram 이 있을 때 local 변수는 int k 하나이지만, int a의 4 byte + int k 의 4 byte + 돌아갈 주소 4 byte 해서 총 12byte 가 최소로 필요하다.
Static local variables : 프로그램 실행되면 storage에 바운딩 됨.
여러 번 실행되어도 값이 변한 상태 그대로 유지된다.
