algorithm
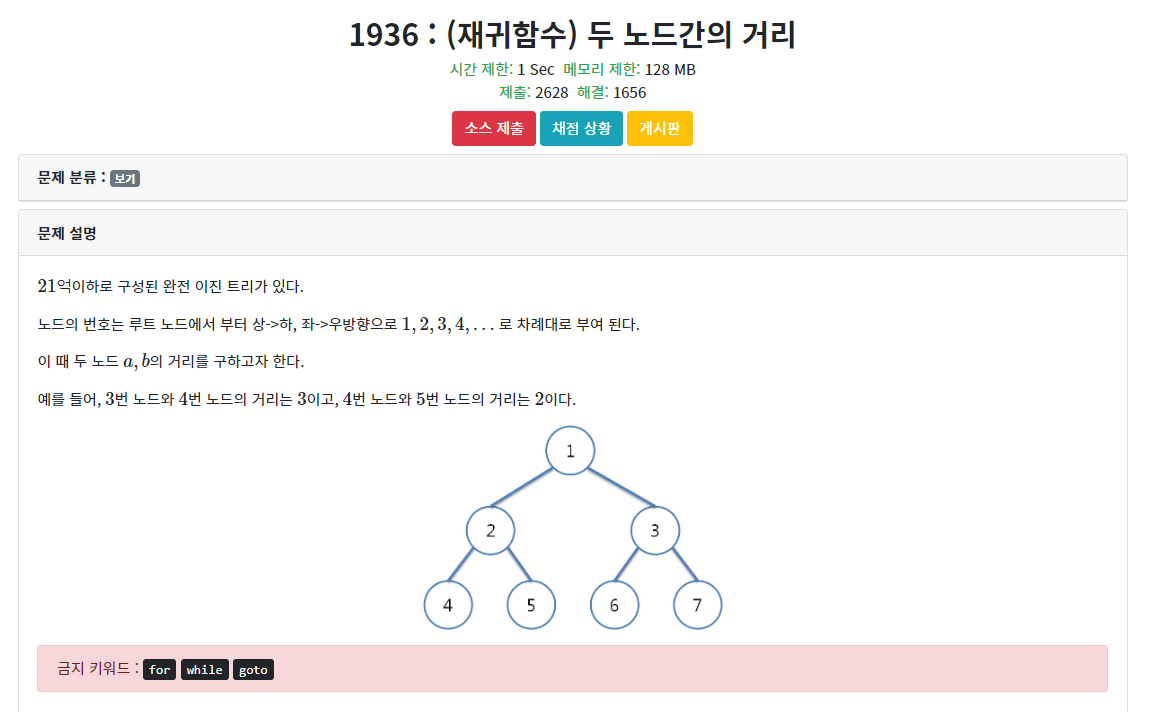
https://codeup.kr/problem.php?id=1936
CodeUp: 두 노드간의 거리
이진 트리란?
각각의 노드가 최대 두개의 자식 노드를 가지는 트리 자료 구조입니다.
자식은 공백이 될 수도 있습니다.
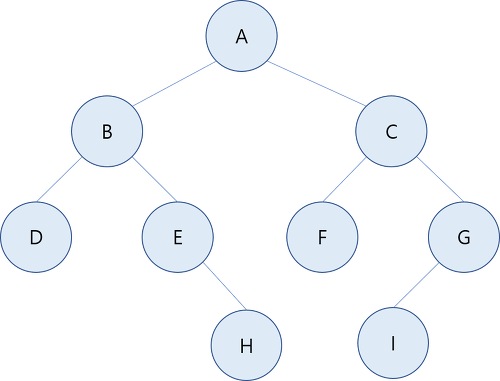
위의 사진은 이진트리의 예를 보여줍니다.
서브트리(자식)가 공백인 노드 : D, F, H, I
하나의 서브트리를 가지고 있는 노드: E, G
두개의 서브트리를 가지고 있는 노드: A, B, C
또한 왼쪽 서브트리와 오른쪽 서브트리를 가지고 있는것을 구분을 명확하게 하기 때문에 E는 오른쪽 서브트리를 가지고있고 G는 왼쪽 서브트리를 가지고 있다라고 말 할 수 있습니다.
이진 탐색이란?
데이터가 정렬돼 있는 배열에서 특정한 값을 찾아내는 알고리즘.
배열의 중간에 있는 임의의 값을 선택해 찾고자하는 값 X와 비교하고
X가 중간 값보다 작으면 중간 값을 기준으로 좌측의 데이터들을 대상으로 다시 탐색,
X가 중간 값보다 크면 중간 값을 기준으로 우측의 데이터들을 대상으로 다시 탐색합니다.
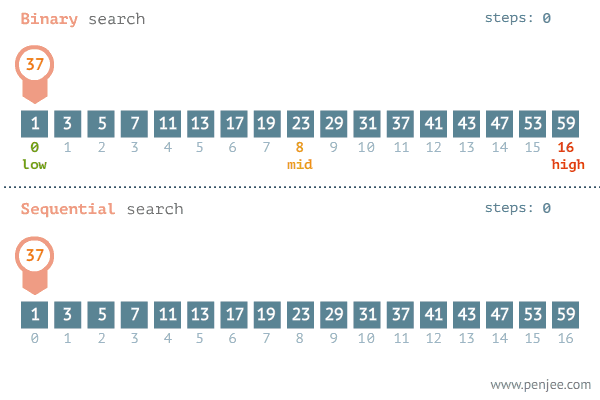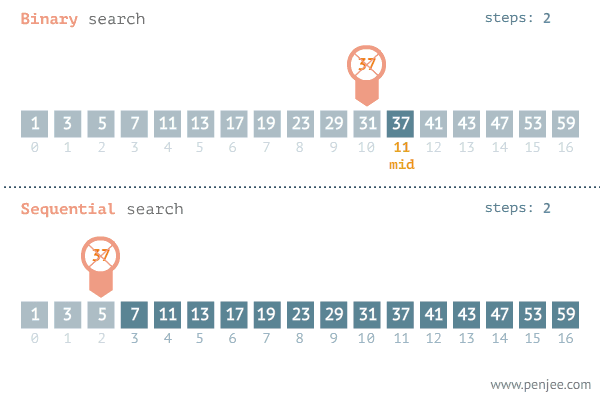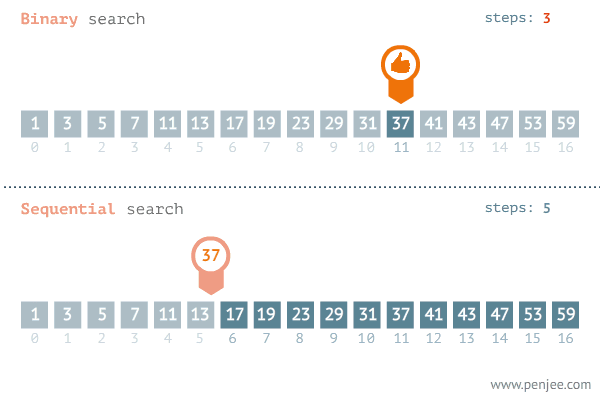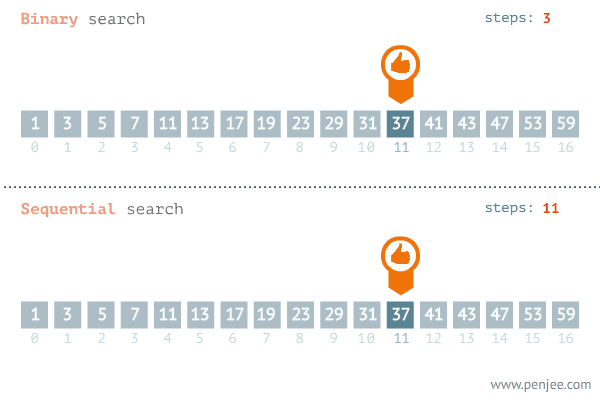
출처: https://blog.penjee.com/binary-vs-linear-search-animated-gifs/
SpringBoot
스트림이란?
자바 8부터 지원하는 기능이며 컬렉션, 배열등에 대해 저장되어 있는 요소들을 하나씩 참조하며 반복적인 처리를 가능하게 합니다.
스트림을 이용해 불필요한 for, if문등을 쓰지 않고도 직관적인 코드를 작성할 수 있습니다.
맵리듀스란?
구글에서 대용량 데이터 처리를 분산 병렬 컴퓨팅에서 처리하기 위한 목적으로 제작한 프레임워크입니다.
맵리듀스는 예를 들어 한명이 4일동안 할 일을 4명이서 나누어 1일만에 끝내는 것으로 병렬 처리 개념입니다.
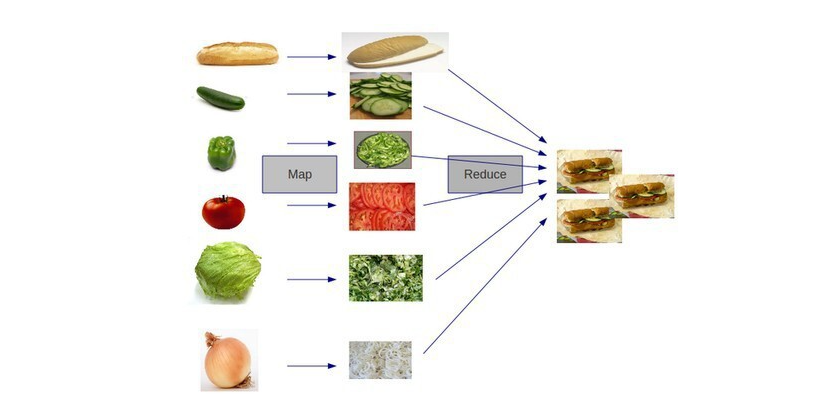
(MapReduce의 예를 위의 사진으로 보여줍니다.)
재료를 준비할때 한명이 다 한다면 오래걸리는 것을 나누어 처리 한 후 합치는 것. ex) 자동차 공장
맵리듀스의 장점
단순하고 사용이 편리하다.
특정 데이터 모델이나 스키마 정의등에 의존적이지 않아서 유연하게 지원 가능하다.
저장 구조와 독립적.
2번과 연계되어 확장성이 높음
맵리듀스의 단점
복잡한 연산이 어렵다.
상대적으로 성능이 낮다.
기존 DBMS가 지원하는 (스키마, SQL문, 인덱스등) 기능을 지원하지 않는다.
.map()
map 메소드는 입력 컬렉션을 출력 컬렉션으로 매핑하거나 변경할때 유용.
map 메소드를 사용하지 않았을 때 코드
final List<String> names = Arrays.asList("Ironman", "Captain", "Hulk", "BlackWidow", "SpiderMan");
for(String name : names) {
System.out.println(name.toUpperCase());
} // list의 엘리먼트 값을 모두 대문자로 변경해서 출력
System.out.println("");출력결과
IRONMAN
CAPTAIN
HULK
BLACKWIDOW
SPIDERMANmap 메소드를 사용했을 때 코드
final List<String> names = Arrays.asList("Ironman", "Captain", "Hulk", "BlackWidow", "SpiderMan");
names.stream()
.map(name -> name.toUpperCase()) // list의 엘리먼트 값을 모두 대문자로 변경해서 출력
.forEach(name -> System.out.println(name));출력결과
IRONMAN
CAPTAIN
HULK
BLACKWIDOW
SPIDERMAN.filter()
filter 메소드는 컬렉션을 조건에 의한 선택을 할때 유용.
filter 메소드는 boolean 결과를 리턴하는 람다표현식이 필요하다.
final Listt<String> names = Arrays.asList("Ironman", "Captain", "Hulk", "BlackWidow", "SpiderMan");
System.out.println("filter 메소드 사용 X");
final List<string> startsWithN1 = new ArrayList<string>();
for (String name : names) {
if (name.startsWith("S")) { // 'S' 로 시작하는 이름을 출력.
startsWithN1.add(name);
}
}
System.out.println(startsWithN1);
System.out.println("");
System.out.println("filter 메소드 사용 O");
final List<string> startsWithN2 =
names.stream().filter(name -> name.startsWith("S")) // 'S' 로 시작하는 이름을 출력.
.collect(Collectors.toList());
System.out.println(startsWithN2);
</string></string></string>출력결과
filter 메소드 사용 X
[SpiderMan]
filter 메소드 사용 O
[SpiderMan]오늘 복습한 어노테이션
@RequiredArgsConstructor
RequiredArgsConstructor 어노테이션은 초기화 되지않은 final 필드나, @NonNull 이 붙은 필드에 대해 생성자를 생성해 줍니다.
주로 의존성 주입(Dependency Injection) 편의성을 위해서 사용되곤 합니다.
빈(Bean)에 생성자가 오직 하나만 있고, 생성자의 파라미터 타입이 빈으로 등록 가능한 존재라면 이 빈은 @Autowired 어노테이션 없이도 의존성 주입이 가능합니다.
TIP) Bean을 주입받는 방식 (3가지)
@Autowired
setter
생성자 (@AllArgsConstructor 사용) -> 권장방식
예제 코드
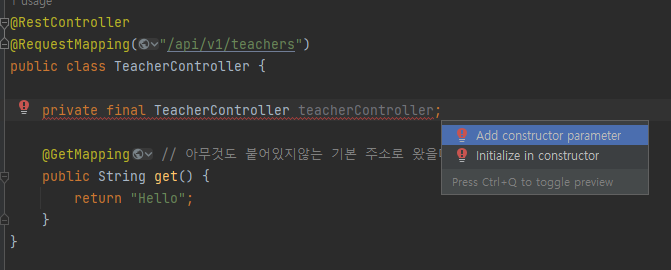
@RequiredArgsConstructor를 사용하지 않았을 때의 코드
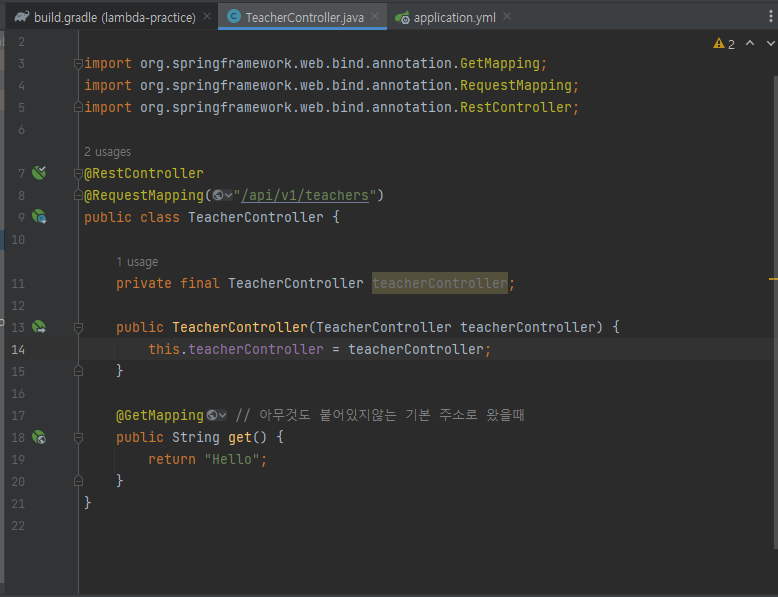
Constructor를 추가해준 모습입니다.
@RequiredArgsConstructor를 사용한 코드
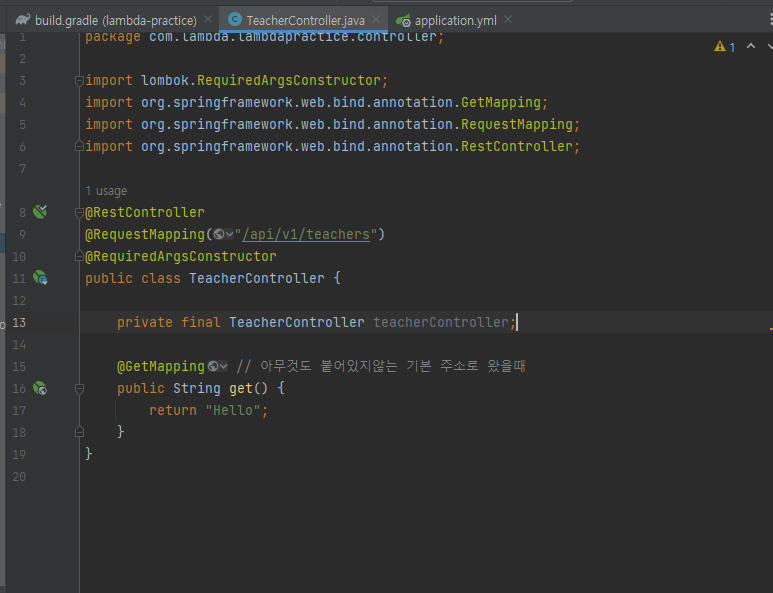
@WebMvcTest
Spring을 안띄우고도 Service만 Test를 할 수 있습니다.
나중에 큰 서비스를 하게 되면 Test를 하기 어려운데
@WebMvcTest를 사용해 @SpringBootTest보다 가볍게 테스트를 가능하게 합니다.
