
해시 테이블 (Hash table)
해시 테이블(해시 맵이라고도 불림)은 Key와 Value로 연관 데이터를 매핑 시켜주는 데이터 구조이다. 해시 함수를 통해 Key를 고유한 index로 변환하여 이 index를 이용하여 bucket이나 slot이라 불리는 배열등에 저장 한다.
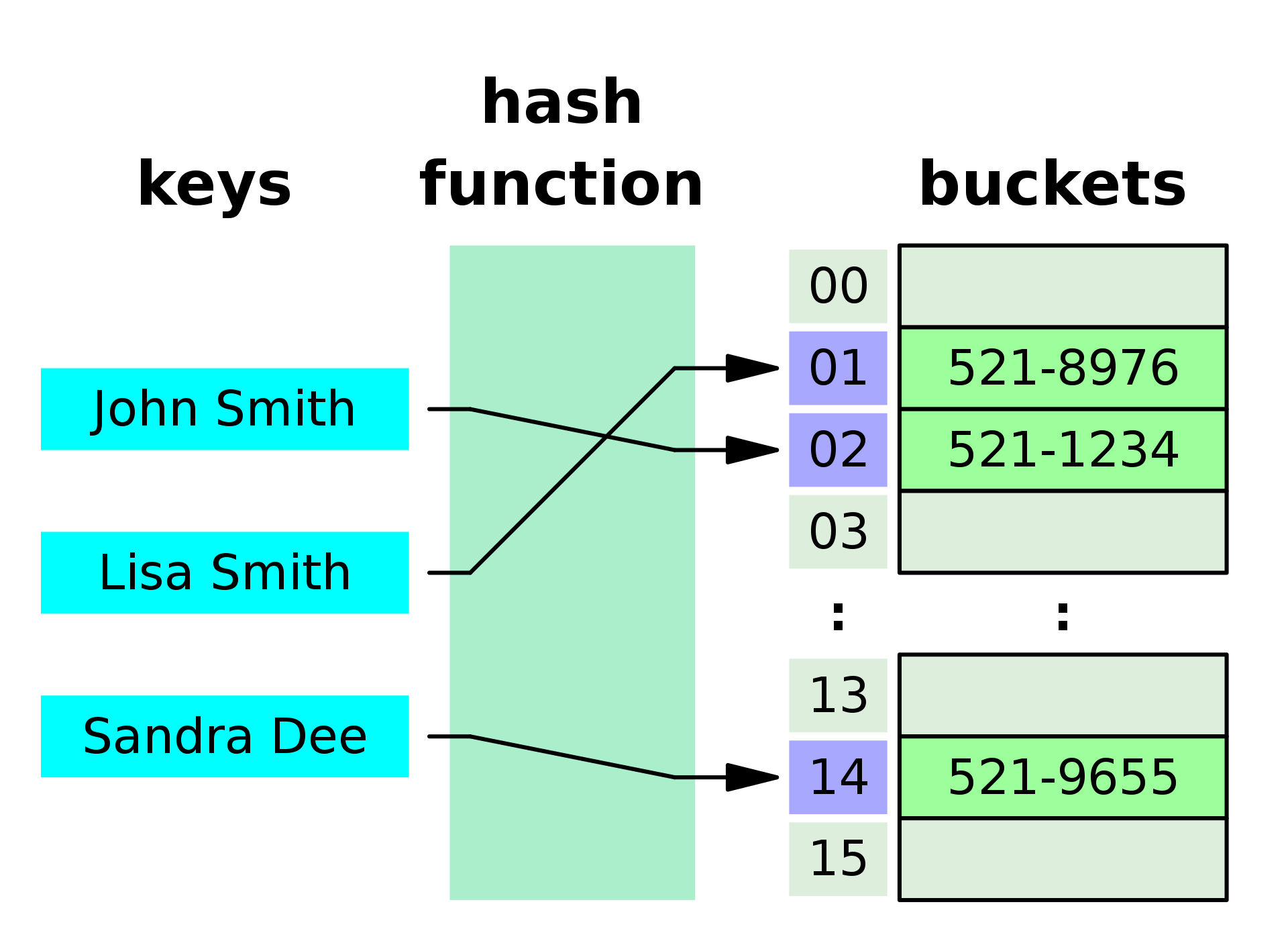
hashing은 공간-시간 trade off의 가장 일반적인 예이다. 요소가 있는지 확인하기 위해 매번 배열을 검색하는 대신 배열을 한 번 탐색 후 모든 요소를 해시 테이블로 만들 수 있다.
hashing 후에는 검색에 O(n)이 걸리던 시간 복잡도를 O(1)로 만들 수 있다.
hashing의 문제점은 해시 충돌인데, 이에 관한 충돌 해결 방법은 다음과 같이 있다.
-
분리 연결법
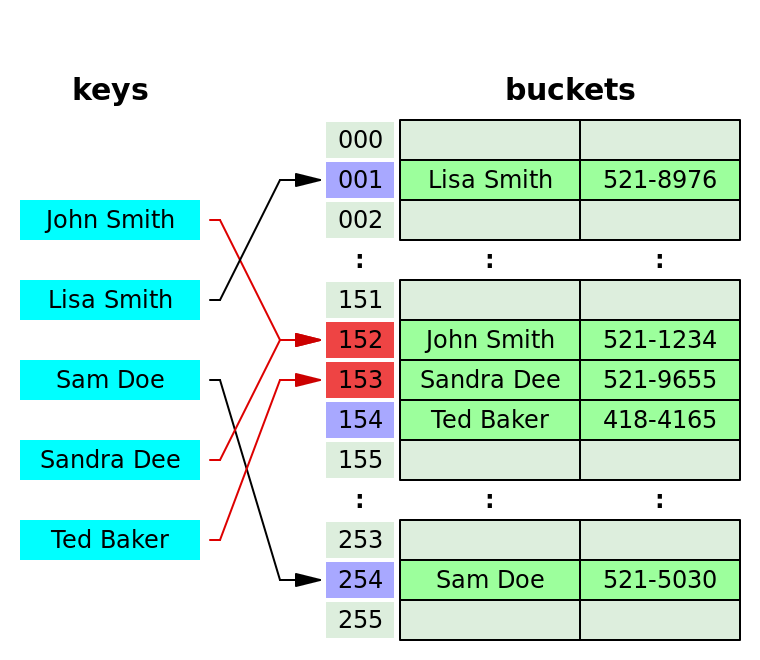
분리 연결법은 충돌이 발생한 경우 버킷에 LInkedList나 Tree 자료구조를 추가로 생성하여 계속해서 확장해 나가는 방법이다. 따라서 bucket의 총 길이가 변하지 않아도 데이터를 저장하는 개수는 제한이 없다. 하지만 이는 메모리 문제를 야기할 수 있다.
-
개방 주소법
비어있는 bucket의 공간을 활용하는 방법이다. 즉, 생성한 index의 자리에 이미 데이터가 있을시 다른 비어있는 bucket의 자리를 찾아 데이터를 저장하는 방식이다. 이 방법은 부하율이 높아질 수록 속도가 급격하게 느려진다.
비어있는 자리를 찾는 방법으로 대표적으로 3가지가 존재한다. -
Linear probing
해당 index로 부터 지정된 폭만큼 차례대로 이동하며 비어있는 자리를 찾는 방식이다. -
Quadratic Probing
폭을 제곱으로 늘려가며 이동하는 방식이다. 예를 들어 첫 번째는 다음 (1^2 = 1)번째의 공간을 탐색하고 있다면 그 다음은 (2^2 = 4)번째의 공간, 그 다음은 (3^2 = 9)번째의 공간… 을 찾는 방식이다. -
Double Hashing
해시된 값을 다시 해시 함수를 통하여 새로운 인덱스를 생성하는 방법이다.
시간 복잡도
| 동작 | Big-O | 비고 |
|---|---|---|
| 접근 | N/A | 해시 코드가 무엇인지 모르면 알 수 없다. |
| 검색 | O(1)* | |
| 삽입 | O(1)* | |
| 삭제 | O(1)* |
필수 문제
- LeetCode
- Two Sum
- Ransom Note
추천 문제
- LeetCode
- Group Anagrams
- Insert Delete GetRandom O(1)
- First Missing Positive
- LRU Cache
- All O one Data Structure
참조
Array cheatsheet for coding interviews | Tech Interview Handbook
