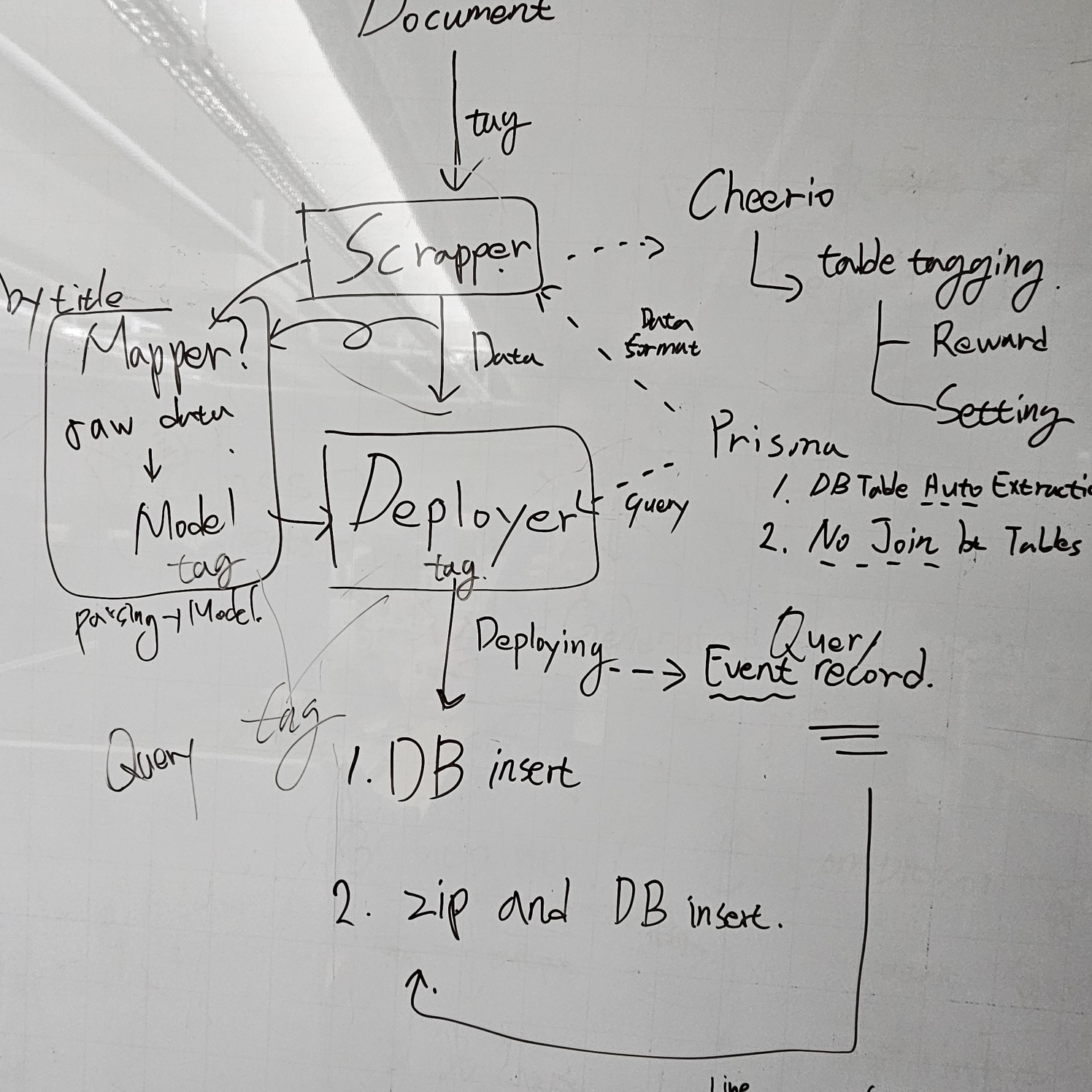
다른 팀에서도 사용 가능한 모듈과 우리 팀에서만 사용하는 모듈을 분리해보기로 하였다. 컨플루언스 문서를 스크랩핑하는 Scrapper 와 Prisma DB 에 배포하고 쿼리를 로깅하는 Deployer 는 다른 팀에서도 사용 가능해 보였다. 그리고 다른 팀과 우리 팀의 DB 테이블 구조는 많이 달랐고 각 팀에서 독립적으로 데이터를 모델에 매핑하는 역할이 필요하게 되었다. Scrapper 와 Deployer 의 중간 단계인 Mapper를 만들게 되었다. Mapper 는 우리 팀의 DB 모델로 스크랩핑한 내용을 변환하는 역할을 한다.
- Scrapper 는 Mapper 에게 컨플루언스 페이지의 body 값을 넘긴다.
- Mapper 는 body 값에서 태그가 달린 테이블을 조회하여 추출하여 일정한 데이터 형식으로 변경한다.
- Mapper 는 일정한 형식의 데이터를 Prisma Model 형식으로 변경한다.
- Deployer 는 Mapper 로부터 값이 담긴 모델을 전달 받고 DB 에 입력하고 쿼리 로그를 저장한다.
- 쿼리 로그를 파일로 만들어 다운로드가 가능하게 만든다.
위와 동일한 단계를 거쳐 Mapper 는 기존에 존재하는 테이블 형식에 맞게 모델에 값을 입력하여 사용할 수 있게 했다. 그리고 우리 팀은 다른 모듈에 신경을 덜 쓰고 Mapper 에만 초점을 맞추어 개발하면 될 것이다.
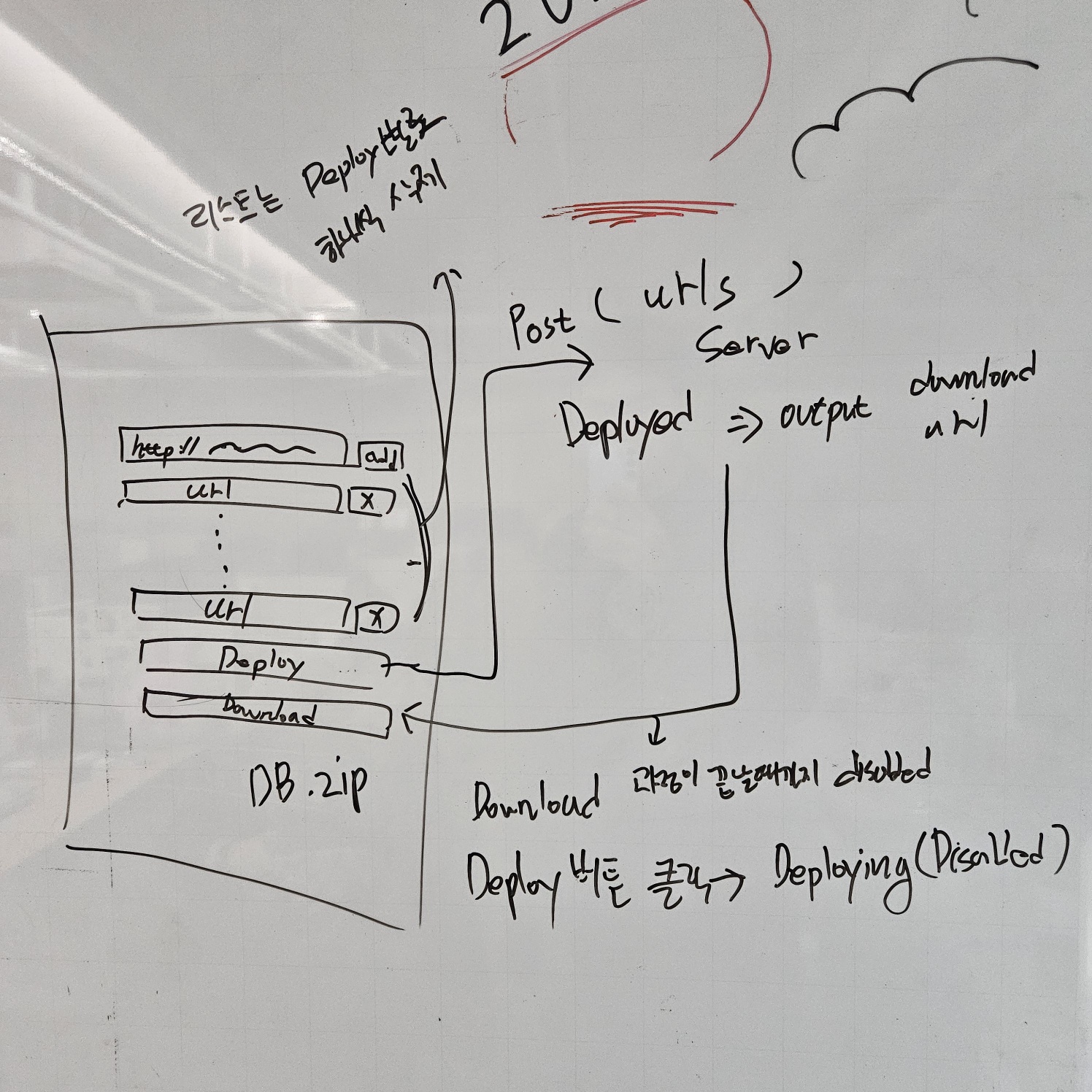
프론트엔드는 어떻게 구성할까? 라는 고민을 하였다.
- 단순한 UI 구성으로 하나의 기능만을 가진 툴이였으면 좋겠다.
- 향후 제작될 어드민에 추가되도록 Svelte 형식의 자유로운 구성이였으면 좋겠다.
그래서 위 사진과 같이 url 을 입력 받는 input 과 입력 받은 url 을 표시하는 리스트, Deploy와 Download 버튼만으로 구성하게 되었다.
클라이언트에서 입력받은 url들을 서버 API 로 넘기고 현재 진행 상황은 Tanstack Query 를 사용하여 진행 중인 상황을 disabled와 loaing 으로 표시하려고 한다.
향후 과제
이제부터 시작이다. 이제 모델로 변경해야할 대상은 30개가 넘고 기획팀께 전달드리고 확인 받기 위한 태그와 테이블은 40개나 된다. 그리고 계속해서 조율해나가고 부족한 부분을 챙기면서 발전시켜야만 한다. 그래서 지금 데이터 설정에만 소요되는 4시간을 4분으로 줄이고 개발에 집중하고 다양한 경험을 쌓을 수 있는 시간이 생길 것이기 때문이다. 화이팅~!
