쿠버네티스에 대한 이해도를 점검하는 10가지 질문
✅ 쿠버네티스 이해도를 점검하는 10가지 질문
-
두 개의 노드가 있는 클러스터에서, 한 노드에는 파드가 있고 다른 노드에는 없을 경우, 새 파드는 어떤 노드에 스케줄링될까요?
-
컨테이너에서 실행 중인 애플리케이션이 OOM(메모리 부족) 오류를 만나면, 컨테이너만 재시작되나요, 아니면 전체 파드가 다시 생성되나요?
-
환경 변수나 ConfigMap 같은 애플리케이션 설정은 파드를 재생성하지 않고 동적으로 적용할 수 있나요?
-
사용자가 추가 작업을 하지 않아도, 한 번 생성된 파드는 안정적으로 계속 유지될까요?
-
ClusterIP 타입의 서비스는 TCP 트래픽에 대해 로드 밸런싱을 보장하나요?
-
애플리케이션 로그는 어떻게 수집해야 하며, 로그 유실의 위험은 없나요?
-
HTTP 서버 파드의 livenessProbe가 정상이라면, 애플리케이션에도 문제가 없다고 볼 수 있나요?
-
트래픽 변화에 대응하기 위해 애플리케이션은 어떻게 스케일링할 수 있을까요?
-
kubectl exec -it <pod> -- bash명령을 실행하면, 파드에 로그인하는 건가요? -
파드 안의 컨테이너가 계속 종료되고 재시작된다면, 어떻게 문제를 해결하시겠습니까?
❓ 질문 1
두 개의 노드가 있는 클러스터에서, 한 노드에는 파드가 있고 다른 노드에는 없을 경우, 새 파드는 어떤 노드에 스케줄링될까요?
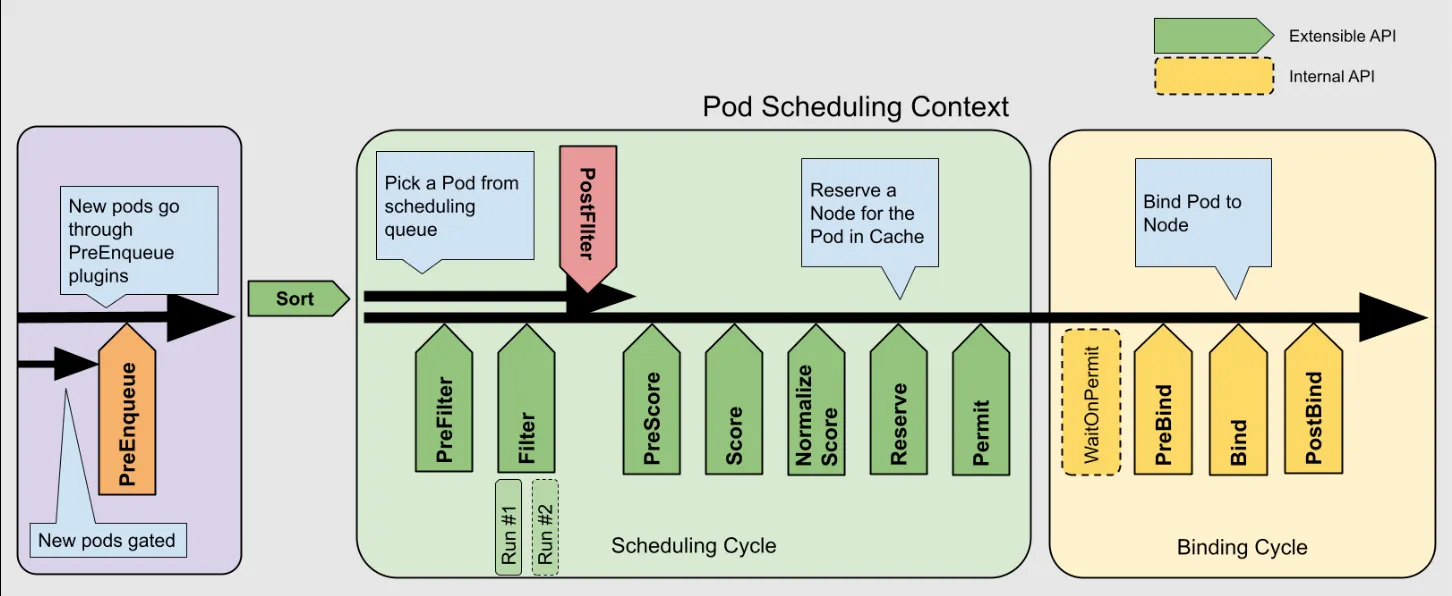
✅ 답변 1
결과는 파드 어피니티(Pod Affinity), 테인트 및 톨러레이션(Taints and Tolerations), 그리고 스케줄링 플러그인과 같은 설정에 따라 달라질 수 있습니다. 하지만 기본 설정이고 두 노드의 리소스 사용량이 동일하다고 가정할 경우, NodeResourcesFit 플러그인이 핵심적인 역할을 합니다.
이 플러그인의 점수 매기기 전략에는 다음과 같은 방식이 있습니다:
-
LeastAllocated (기본값): 리소스를 가장 적게 사용하는 노드를 우선합니다.
-
MostAllocated: 리소스를 더 많이 사용하는 노드를 우선합니다.
-
RequestedToCapacityRatio: 자원 사용률의 균형을 맞추는 전략입니다.
MostAllocated 전략을 사용할 경우, 새로운 파드는 이미 파드가 있는 노드에 스케줄링됩니다. 반면, 다른 두 전략은 파드가 없는 노드를 더 선호합니다.
📊 스케줄링 전략별 비교 표
| 전략 이름 | 설명 | 선호되는 노드 |
|---|---|---|
| LeastAllocated (기본값) | 가장 적게 리소스를 사용하는 노드를 우선함 | 파드가 없는 노드 (리소스 여유 多) |
| MostAllocated | 리소스를 많이 사용 중인 노드를 우선함 | 이미 파드가 있는 노드 |
| RequestedToCapacityRatio | 리소스 사용률의 균형을 고려하여 스케줄링함 | 상황에 따라 다름 (균형 우선) |
❓ 질문 2
컨테이너에서 실행 중인 애플리케이션이 OOM(메모리 부족) 오류를 만나면, 컨테이너만 재시작되나요, 아니면 전체 파드가 다시 생성되나요?
✅ 보완된 해설 포함 답변
컨테이너에서 애플리케이션이 OOM(메모리 부족) 오류를 일으키면, 대부분의 경우 해당 컨테이너만 재시작되며, 파드는 그대로 유지됩니다. 이는 파드의 RestartPolicy가 기본적으로 Always로 설정되어 있기 때문입니다.
하지만 여기엔 운영체제 수준의 세부 동작(cgroup 버전 차이) 도 영향을 줍니다.
-
cgroup v1에서는 일반적으로 OOM이 발생한 개별 프로세스만 종료됩니다.
-
cgroup v2에서는 cgroup 전체(즉, 컨테이너 전체)의 리소스를 관리하므로, 전체 컨테이너가 종료될 수 있습니다.
그리고 만약 노드 전체에 메모리 압박이 심해지면, kubelet은 파드를 evict(축출) 할 수 있으며, 이 경우 파드는 삭제되고 다시 생성될 수 있습니다.
❓ 질문 3
환경 변수나 ConfigMap 같은 애플리케이션 설정은 파드를 재생성하지 않고 동적으로 적용할 수 있나요?
✅ 답변 3
-
환경 변수는 동적으로 변경할 수 없습니다.
-
ConfigMap은 파일로 마운트한 경우에 한해, 동적으로 반영될 수 있습니다 (단, subPath를 사용하지 않아야 함). 반영 시점은 kubelet의 syncFrequency(기본값 1분)와 configMapAndSecretChangeDetectionStrategy 설정에 따라 달라집니다.
📌 추가 정보
| 항목 | 동적 적용 가능 여부 | 비고 |
|---|---|---|
| 환경 변수 | ❌ 불가능 | 변경 시 파드 재생성 필요 |
| ConfigMap (파일 마운트) | ✅ 가능 | subPath 사용 금지 |
| ConfigMap (subPath) | ❌ 불가능 | 파드 재생성 필요 |
| ConfigMap (envFrom) | ❌ 불가능 | 파드 재생성 필요 |
❓ 질문 4
사용자가 추가 작업을 하지 않아도, 한 번 생성된 파드는 안정적으로 계속 유지될까요?
✅ 답변 4
아닙니다. 파드는 생성된 후에도 항상 안정적으로 유지된다고 보장할 수 없습니다.
리소스 부족이나 네트워크 문제와 같은 외부 요인으로 인해, 사용자가 아무 작업을 하지 않아도 파드가 축출(Eviction)될 수 있습니다.
📌 추가 설명
-
파드는 일시적인 객체입니다. ReplicaSet이나 Deployment가 파드를 관리하지 않는 이상, 실패 시 자동 복구되지 않습니다.
-
Eviction(축출)은 노드의 메모리 부족 또는 디스크 압박 등으로 인해 kubelet이 파드를 제거하는 행위입니다.
-
파드의 지속성과 안정성을 보장하려면, Deployment, StatefulSet 등의 컨트롤러로 관리하는 것이 바람직합니다.
❓ 질문 5
ClusterIP 타입의 서비스는 TCP 트래픽에 대해 로드 밸런싱을 보장하나요?
✅ 답변 5
- ClusterIP는 TCP 트래픽에 대해 로드 밸런싱을 수행하지만, 완벽하게 균등한 분산을 보장하지는 않습니다.
- 특히 오래 지속되는 연결(long-lived connections) 의 경우, 세션 유지로 인해 불균형한 부하 분산이 발생할 수 있습니다.
- 지속적인 연결이 많을 경우 부하가 한쪽으로 몰릴 수 있으므로,
필요한 경우 외부 LoadBalancer나 Istio 같은 서비스 메시로 보완하는 것이 좋습니다.
📌 추가 설명
| 항목 | 설명 |
|---|---|
| 로드 밸런싱 방식 | iptables 또는 IPVS를 통한 커널 수준 분산 처리 |
| 세션 유지 (Session Affinity) | 동일 클라이언트가 동일한 백엔드에 계속 연결될 수 있음 |
| 단점 | 장시간 연결이 유지되면 일부 백엔드에만 부하가 몰릴 수 있음 |
❓ 질문 6
애플리케이션 로그는 어떻게 수집해야 하며, 로그 유실의 위험은 없나요?
✅ 답변 6
- stdout/stderr로 출력하는 로그는 노드에 저장되며, 로그 수집 에이전트를 통해 수집할 수 있습니다.
- 하지만 파드가 삭제되기 전에 수집되지 않으면 로그가 유실될 수 있습니다.
- 지속성 있는 볼륨(Persistent Volume)에 로그를 파일로 저장하면 유실을 방지할 수 있습니다.
- ELK, Loki, Grafana와의 연동을 대안으로 볼 수 있습니다.
📌 로그 수집 방식 요약
| 로그 방식 | 장점 | 단점 |
|---|---|---|
| stdout / stderr | Kubernetes 기본 방식, 도구와 잘 통합됨 | 파드 삭제 시 로그 유실 가능성 있음 |
| 파일로 기록 + PV | 로그 유실 방지, 장기 보존 가능 | 로그 파일 관리 및 마운트 필요 |
❓ 질문 7
HTTP 서버 파드의 livenessProbe가 정상이라면, 애플리케이션에도 문제가 없다고 볼 수 있나요?
✅ 답변 7
-
아닙니다. livenessProbe가 정상이어도 애플리케이션이 완전히 정상이라는 의미는 아닙니다.
-
애플리케이션이 부분적으로 손상된 상태(degraded state) 일 수도 있고, 네트워크 상에서 다른 노드에서는 통신 문제가 발생할 수 있음에도 불구하고, livenessProbe는 이를 감지하지 못할 수 있습니다.
-
따라서 어플리케이션의 실제 상태 확인은 별도의 모니터링, APM, 커스텀 헬스체크 등을 통해 보완해야 합니다.
📌 관련 개념 요약
| 프로브 유형 | 설명 | 한계 |
|---|---|---|
livenessProbe | 컨테이너가 살아 있는지 확인 (비정상 시 재시작) | 기능 정상 여부는 확인하지 않음 |
readinessProbe | 서비스에 트래픽을 보낼 준비가 되었는지 확인 | 애플리케이션 내부 상태까지는 파악 어려움 |
| 네트워크 관점 | 프로브 요청은 kubelet이 전송 | 클러스터 외부 또는 다른 노드 간 연결 문제는 감지 불가 |
네! 질문 8번에 대한 정확한 한국어 번역과 설명을 아래에 정리해드릴게요.
❓ 질문 8
트래픽 변화에 대응하기 위해 애플리케이션은 어떻게 스케일링할 수 있을까요?
✅ 답변 8
Kubernetes는 트래픽 변화에 대응하기 위해 수평 스케일링(HPA) 과 수직 스케일링(VPA) 을 지원합니다.
- HPA는 파드의 개수를 동적으로 조절하며, 가장 일반적으로 사용됩니다.
- VPA는 파드의 리소스(CPU, 메모리)를 조정하여 재생성하는 방식이라, 사용에 제약이 있습니다.
- 외부 시스템에서도 API 서버를 통해 스케일 조정을 트리거할 수 있습니다.
- 일반적인 트래픽 변화 대응에는 HPA를 활용한 자동 스케일링이 효과적입니다.
- 고정된 리소스 한계 문제에는 VPA를 고려할 수 있지만, 재시작이 동반되므로 신중히 사용해야 합니다.
📌 스케일링 방식 요약
| 스케일링 방식 | 설명 | 특징 |
|---|---|---|
| HPA (수평 확장) | 파드 개수 자동 조정 (CPU, 메트릭 기반) | 실시간 대응, 많이 사용됨 |
| VPA (수직 확장) | 파드 리소스 변경 후 재생성 | 다운타임 가능성, 제한적 사용 |
| 외부 트리거 | 외부 시스템이 API 서버에 요청해 수동/자동 스케일링 | 사용자 지정 로직에 활용 가능 |
❓ 질문 9
kubectl exec -it -- bash 명령을 실행하면, 파드에 로그인하는 건가요?
✅ 답변 9
- 아니요, 이는 "로그인"이라기보다는, 지정된 컨테이너 안에서 새로운 bash 프로세스를 실행하는 것입니다.
- 즉, 파드 전체에 접속하는 것이 아니라, 파드 내 컨테이너 중 하나의 격리된 환경 안에 진입하는 것입니다.
- kubectl exec는 컨테이너 내부 명령 실행 도구일 뿐, 파드 전체에 SSH처럼 로그인하는 방식이 아닙니다.
- 여러 컨테이너가 있는 파드에서는 어떤 컨테이너에 exec 할 것인지 명시해야 합니다.
❓ 질문 10
파드 안의 컨테이너가 반복적으로 종료되고 재시작된다면, 어떻게 문제를 해결하시겠습니까?
✅ 답변 10
-
컨테이너가 계속 크래시(crash)된다면, kubectl exec는 사용할 수 없습니다.
-
이럴 때는 로그 확인, 파드 상태 점검, kubectl debug를 통한 조사용 임시 컨테이너 실행 등의 방법으로 원인을 파악할 수 있습니다.
-
반복적인 종료 문제는 로그 + 상태 + 디버그 환경을 조합하여 원인을 좁혀가는 방식으로 해결해야 합니다.
-
kubectl debug는 최근 Kubernetes에서 매우 강력한 문제 해결 도구입니다.
📌 문제 해결 단계 요약
| 단계 | 설명 |
|---|---|
| 1️⃣ 로그 확인 | kubectl logs <pod>로 충돌 직전의 로그 확인 |
| 2️⃣ 상태 점검 | kubectl describe pod <pod>로 이벤트, 리소스 오류, OOM 여부 확인 |
| 3️⃣ 디버깅 환경 구성 | kubectl debug로 디버깅용 컨테이너를 띄워 환경/의존성 분석 |
| 4️⃣ 컨테이너 명령 확인 | command, args 설정이 잘못됐는지 확인 (예: 잘못된 쉘 경로 등) |
| 5️⃣ CrashLoopBackOff 타이밍 | 주기적 재시작으로 인해 로그 수집이 제한될 수 있음, --previous 플래그 활용 |
더 알아보기
✅ 1. Pod와 Container 개념의 명확한 구분
처음 쿠버네티스를 접하실 때 가장 많이 혼동하시는 부분이 바로 Pod와 컨테이너의 관계입니다.
- Pod는 하나 이상의 컨테이너를 담는 최소 단위입니다.
- 컨테이너가 종료되어도 Pod는 계속 존재할 수 있으며, 반대로 Pod가 삭제되면 그 안의 모든 컨테이너도 함께 사라집니다.
kubectl logs나kubectl exec같은 명령어는 컨테이너 단위로 동작합니다.
👉 문제 상황이 발생했을 때, Pod 전체의 이슈인지, 특정 컨테이너의 문제인지를 먼저 파악하시는 것이 중요합니다.
✅ 2. livenessProbe와 readinessProbe는 역할이 다릅니다
두 프로브는 유사해 보이지만 용도는 완전히 다릅니다:
- livenessProbe: 컨테이너가 "살아 있는지" 확인 → 실패 시 재시작
- readinessProbe: 서비스 요청을 받을 준비가 되었는지 확인 → 실패 시 트래픽 차단
▶️ 실무에서는 livenessProbe는 통과했는데도 트래픽이 가지 않는 현상이 발생하는 경우가 있는데, 이는 readinessProbe 실패 때문일 수 있습니다.
✅ 3. 로그 수집은 클러스터 설계 단계부터 고려해야 합니다
- 파드가 삭제되면 기본적으로 로그도 함께 사라집니다.
- 표준 출력(
stdout/stderr)으로 로그를 출력하는 경우, Fluent Bit, Filebeat 등의 에이전트를 DaemonSet으로 구성하여 수집하시는 것이 일반적입니다. - 로그가 중요한 서비스라면, Persistent Volume에 로그 파일을 저장하거나, Loki, Elasticsearch와 같은 로그 집계 시스템과 연동하는 것도 권장드립니다.
✅ 4. HPA 외의 스케일링 전략도 고려해보세요
- Horizontal Pod Autoscaler(HPA)는 CPU나 메모리 사용량을 기반으로 자동으로 스케일링해주는 훌륭한 도구입니다.
- 하지만 경우에 따라 요청 수나 대기열 길이와 같은 사용자 정의 메트릭이 더 적절할 수 있습니다.
- 이럴 경우에는 Custom Metrics Adapter나, KEDA (Kubernetes Event-driven Autoscaling) 같은 솔루션을 통해 더욱 유연하게 대응하실 수 있습니다.
✅ 5. kubectl debug는 강력한 문제 해결 도구입니다
컨테이너가 반복적으로 크래시되면 kubectl exec 명령은 사용할 수 없습니다.
이럴 때는 kubectl debug를 이용해 디버깅 전용 컨테이너를 임시로 파드에 붙여 환경을 점검할 수 있습니다.
▶️ 이는 실무에서 장애 분석 시 매우 유용한 방법이며, 최근 많은 팀에서 적극적으로 활용하고 있습니다.
🔍 추가로 추천드리는 학습 주제
| 주제 | 실무에서의 활용 이유 |
|---|---|
| Node Affinity / Taints | 워크로드 분산, 특정 노드 지정 등 고급 스케줄링 전략 적용 |
| PodDisruptionBudget | 롤링 업데이트나 노드 재시작 중 파드가 과도하게 사라지는 것을 방지 |
| Resource Requests / Limits | OOM 방지, 리소스 낭비 줄이기 위한 자원 설정 |
| Helm / Kustomize | YAML 템플릿화 및 배포 자동화로 운영 효율성 향상 |
| RBAC / SecurityContext | 최소 권한 원칙 및 보안 설정 적용을 위한 필수 기능 |
