DB
컴퓨터 시스템에 저장되는, 구조화된 정보 혹은 데이터의 집합
DBMS (Database Management System)
데이터베이스에서 데이터를 정의, 저장, 검색 및 인출, 관리하기 위해 사용되는 소프트웨어
SQL (구조화된 쿼리 언어)
- 관계형 데이터베이스와 대화하기 위해 특별히 디자인된 언어이다.
- 대표적으로 MySQL , PostgreSQL , SQLite가 있다.
- SQL 데이터베이스는 테이블이 있고 , 행과 열이 존재한다.
NoSQL
정의
- 비관계형 데이터베이스
- 대량의 분산된 데이터를 저장하고 조회하는 데 특화되어있으며, 스키마 없이 사용가능하거나 느슨한 스키마를 제공하는 저장소를 말한다.
특징
- 데이터 간의 관계를 정의하지 않는다.
JOIN 연산이 힘들다.
- 대용량의 데이터를 저장할 수 있다.
- 분산형 구조이다.
여러 곳의 서버에 데이터를 분산 저장해 특정 서버에 장애가 발생했을 때에도 데이터 유실이나 서비스 중지가 발생하지 않도록 한다.
- 고정되지 않은 스키마를 갖는다.
데이터를 저장하는 column이 각기 다른 이름과 데이터 타입을 갖는 것이 허용된다.
장점
관계형데이터베이스에 비해 저렴한 비용으로 분산처리와 병렬 처리가 가능하다.
설계 비용이 줄어든다.
정해진 구조가 없기 때문에 다양한 구조로 데이터 저장이 가능하다.
데이터 모델의 유연한 변화가 가능하다.
단점
일관성이 보장되지 않는다.
많은 인덱스를 활용하려면 충분한 메모리가 필요하다.
종류
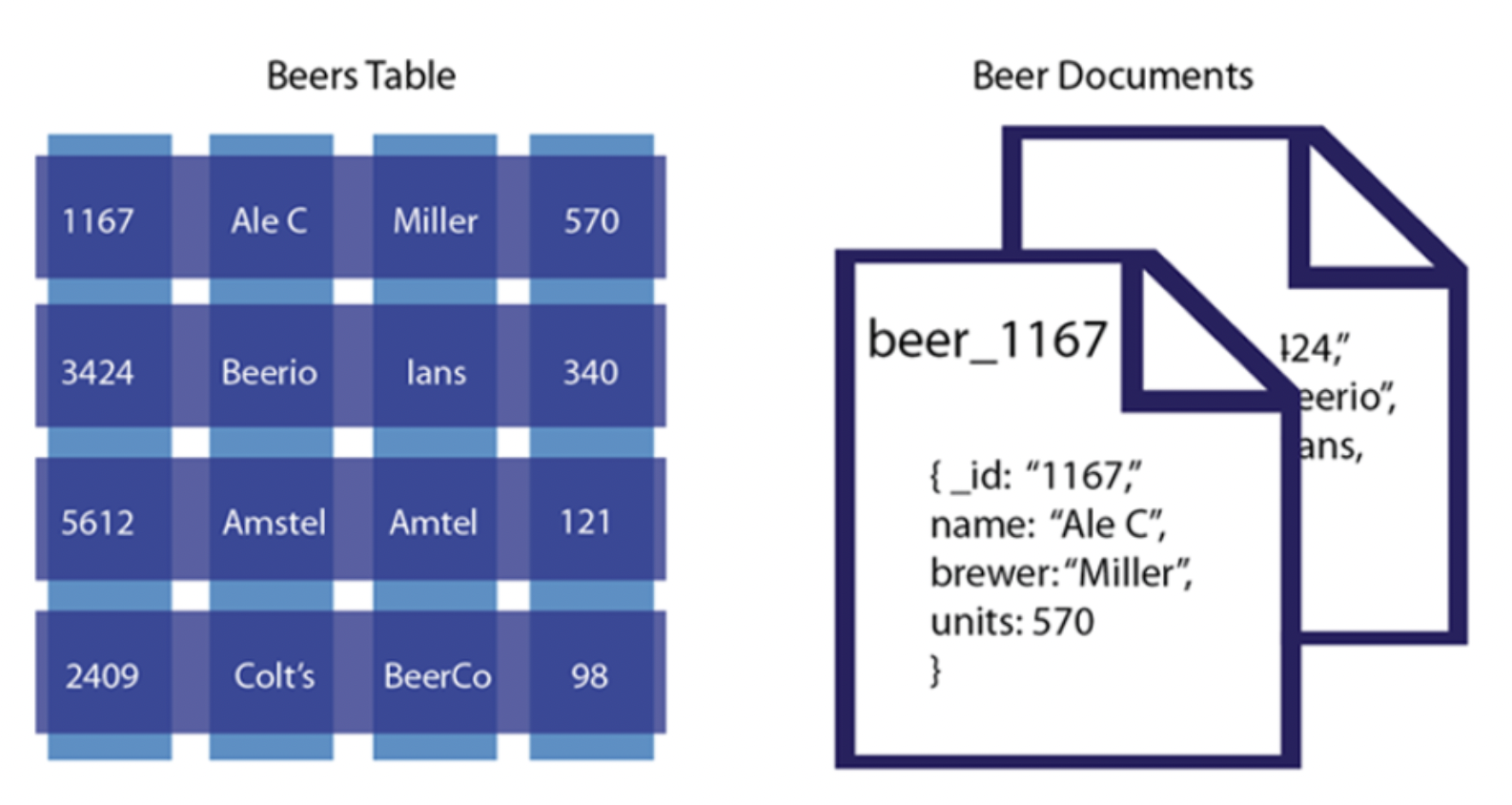
출처: https://inyl.github.io/programming/2017/05/09/database.html- Document DB
데이터를 json document 형태로 저장한다.
보통의 SQL처럼 행과 열이 존재하는 것이 아니라 원하는 종류와 모양으로 저장할 수 있다.
데이터들은 같은 모양을 갖지 않아도 된다.
프론트엔드와 백엔드 간의 소통 언어로 JSON이 활용되기 때문에 편리한 이점이 있다.
트리형 구조로 레코드를 저장하거나 검색하는 데 효과적이다.
가장 큰 예시로 mongoDB가 있다.
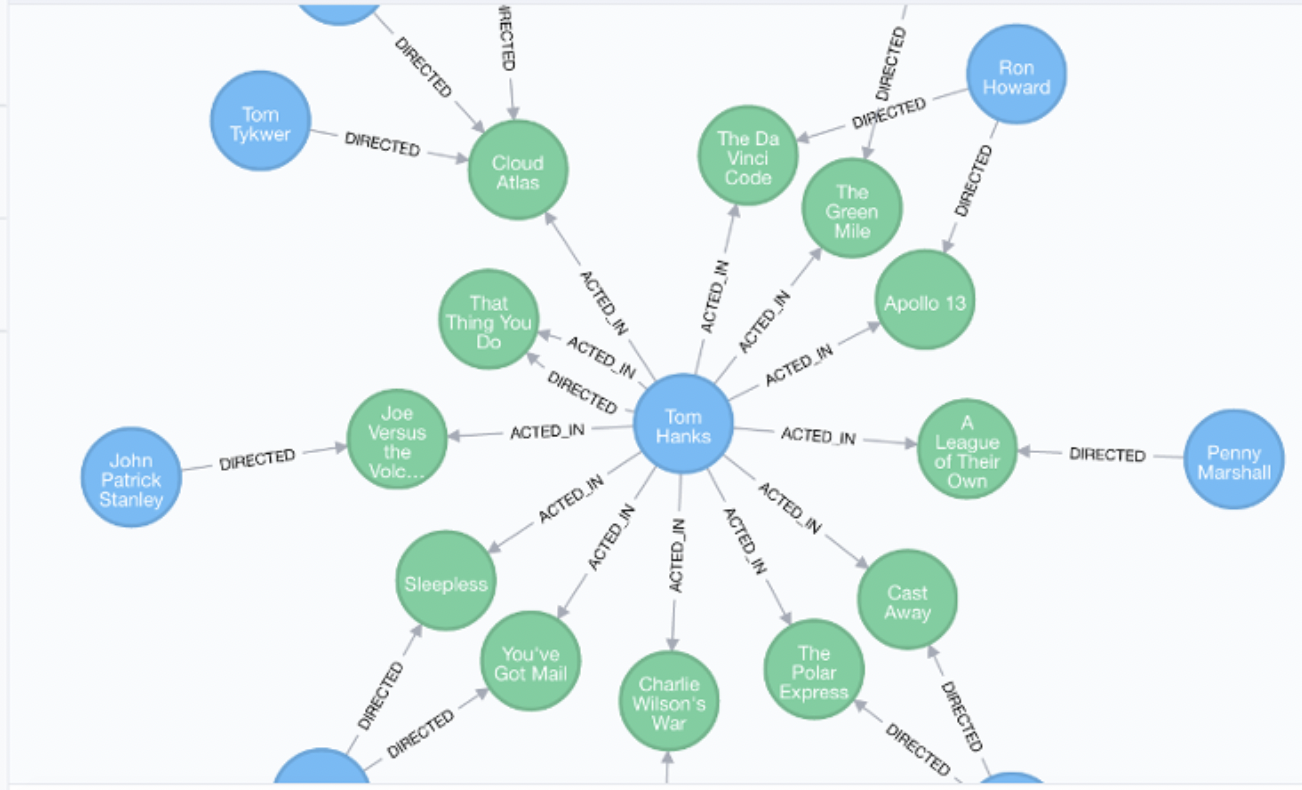
출처: https://database.guide/what-is-a-graph-database/#more-896- Graph DB
column이나 document가 필요없고 각 노드 사이의 관계를 알아야 할 때 활용한다.
소셜 네트워크 시스템에서 주로 활용되며 데이터를 각각 저장하고 이를 관계망으로 연결한다.
관계형 데이터베이스보다 성능이 좋고 유연하여 유지보수에 용이하다.
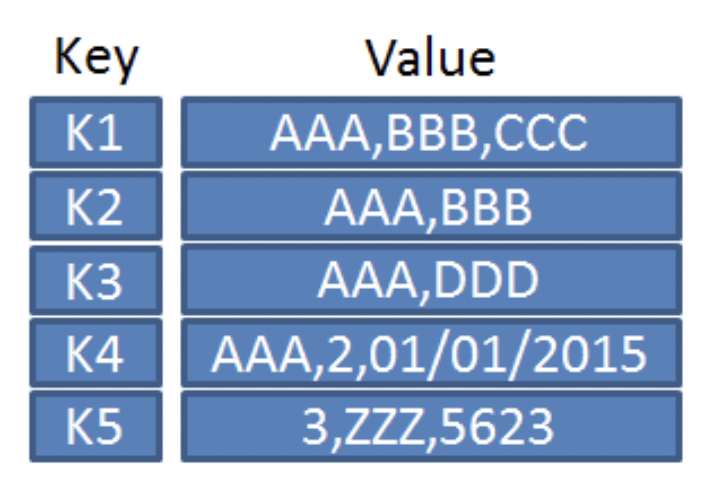
출처: https://en.wikipedia.org/wiki/Key-value_database- Key-Value DB
기본적인 패턴으로 단순하게 Key-Value의 묶음으로 저장되는 구조이기 때문에 속도가 빠르고 분산 저장시 용이하다.
파티셔닝을 통해 다른 유형의 데이터베이스로는 불가능한 범위까지 수평 확장을 가능하게 한다.
가장 많이 활용하는 Key-Value DB로 Amazon Dynamo DB가 있다.
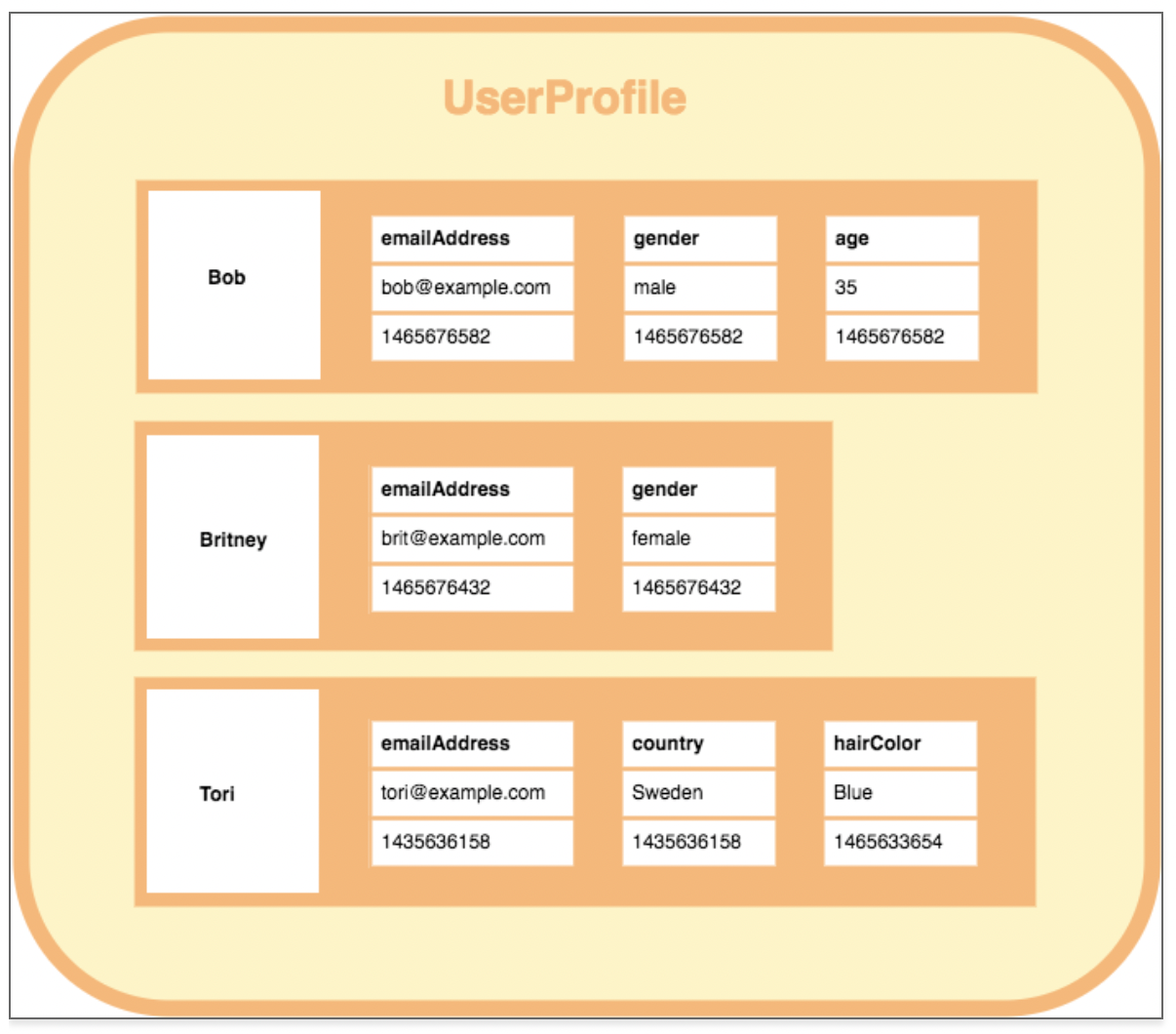
출처: https://database.guide/what-is-a-column-store-database/- wide column DB
행마다 키와 값을 저장할 때마다 각각 다른값의 다른 수의 스키마를 가질 수 있다.
대량의 데이터의 압축, 분산처리, SUM , COUNT 와 같은 집계 쿼리 및 쿼리 동작 속도, 확장성이 뛰어난 것이 대표적인 특징이다.
대표적인 DB로 Cassandra가 있다.
- 파티셔닝 참고자료
