1. Introduction

머신러닝, 딥러닝이 어디에든지 적용되고 있다.
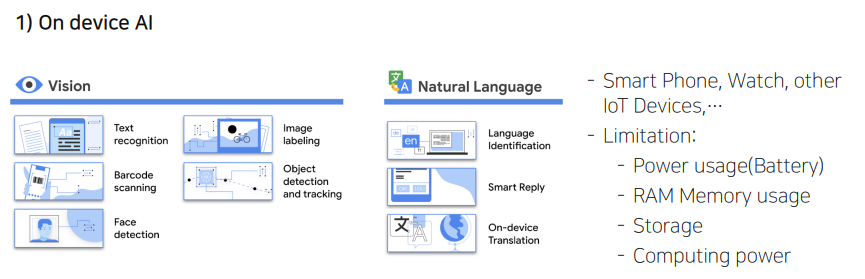
그러면서, 여러 디바이스에 적용되고자 하는 시도가 증가했다. 하지만 여기에는 몇가지 한계가 있다.
- 파워 사용량(배터리)
- 메모리 사용량
- 저장 공간
- 컴퓨팅 파워
이 4가지를 해소할 수 있는 것이 경량화이며 강의에서 전반적으로 이를 다룰것이다.

- latency : 요청에 대해 소요되는 시간
- throughput : 단위 시간당 처리되는 양
만약, 번역 작업을 하는데 1분에 1문장이 번역된다. 또는 한 사이트를 10명만 이용할 수 있다면 불편할 것이다.

전체적으로 연산량이 매우 크게 증가하는 추세.


구분은 주관적일 수 있다. 두 관점을 섞어서 보기도 하기 때문. 연구 분야로서 받아들이면 된다.
- Efficient Architecture Design : 모델의 크기를 줄이는 것. 특히, AutoML을 통해서 사람이 줄이는 것이 아니라, 모델의 최적화되는 지점을 찾아 모델에 맞춰 줄이는 것이 대세이다.
- Network Pruning : 학습된 네트워크를 가지치기. 중요도가 낮은 파라미터를 제거하자.
- Knowledge Distillation : Teacher Network를 Student Network로 전이하자. (차원 축소와 비슷)
- Matrix/Tensor Decomposition : 알버트에서 쓰인 것과 비슷. 100차원의 행렬을 20차원과 40차원의 곱으로 나타내어서 메모리 사용량을 줄이는 방법. 이렇게 되면 가중치의 크기도, 가중치의 개수도 줄어든다.
- Network Quantization : 근사값을 줄이자. fp32 -> fp16 와 같이 작은 데이터 타입을 이용하자는 것.
- Network Compiling : Target hardware가 정해져있을 때 inference가 효과적으로 진행되도록 네트워크 자체를 컴파일 하는 것.
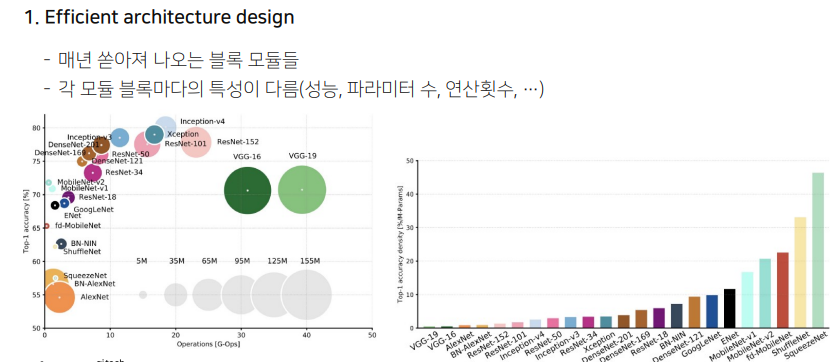
x축은 연산 횟수, y축은 정확도, 원의 크기는 필요한 파라미터 수이다. 왼쪽에 있는 모델이 경량화 하기에 적합한 모델이다.

AutoML이나 NAS등이 이러한 2.0에 해당한다.
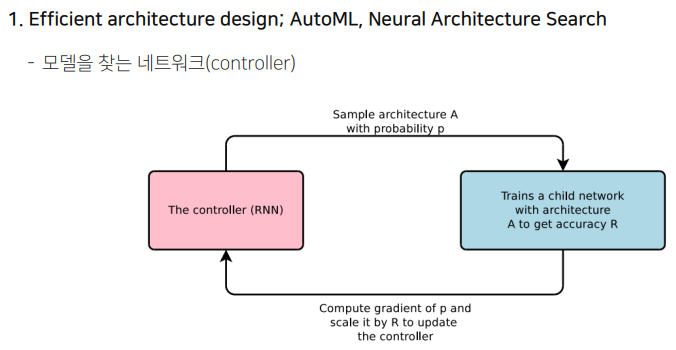
모델을 찾는 네트워크가 특정 아키텍처를 제안한다. 이 제안된 아키텍터를 학습하고 정확도를 측정해본다. 이 정확도를 가지고 네트워크를 학습시킨다. 그러면 또 다음 아키텍처를 제안하고 하는 방식의 Repeat-Interactive 한 방식으로 찾는다.
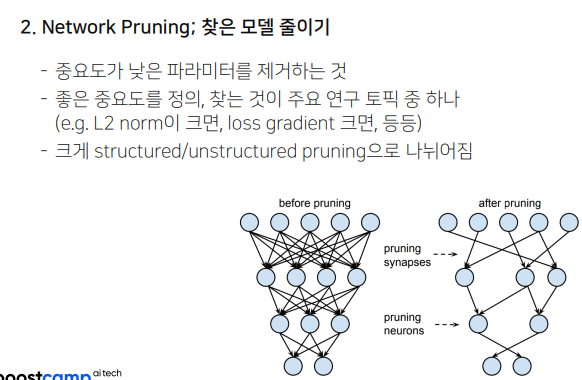
왼쪽은 학습된 네트워크. 오른쪽 네트워크 처럼 파라미터를 줄이는 것이 프루닝.
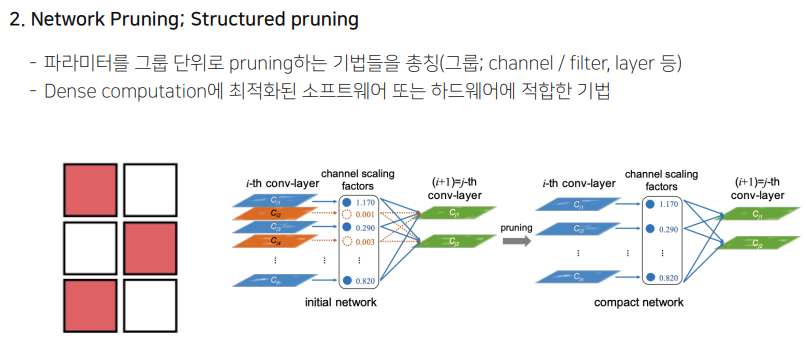
파라미터를 그룹 단위로 프루닝함. 채널, 필터, 레이어등이 여기에 속함.
왼쪽 그림에서는, 6개의 필터중에서 빨간 색 필터만 남겨서 3개의 필터를 날리는 모습. 오른쪽 그림에서는 주황색 필터의 중요도가 높지 않아서 제거하는 모습.
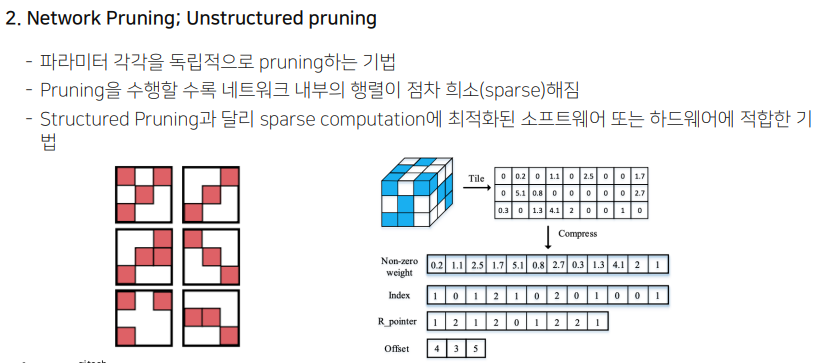
매우 효율적으로 보이긴 하지만 제약 조건이 좀 있다.
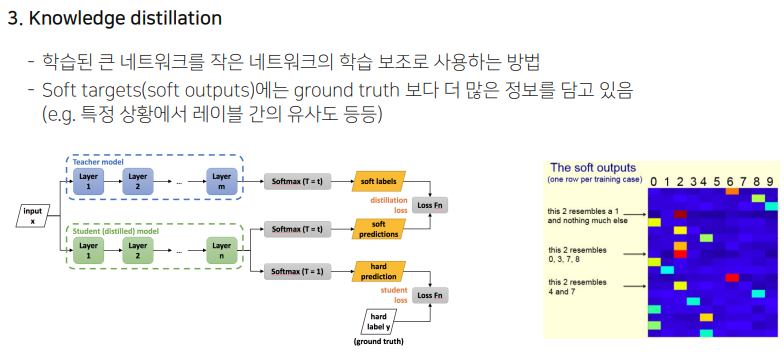
자동차와 자전거가 함께 있는 사진에서 한 가지 라벨로만 태깅해야 해서 자동차로 태깅되었을 때 모델이 봤을 때는 자동차와 자전거가 둘 다 있으므로 혼동이 생길 수 있다. 이를 위해서 한 가지 값을 갖는 GT를 가지기 보다는 더 많은 정보를 가질 수 있도록 Soft Label을 갖도록 한다.

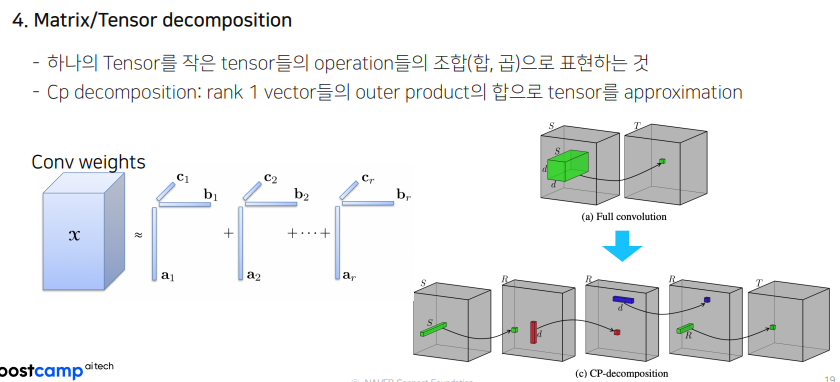
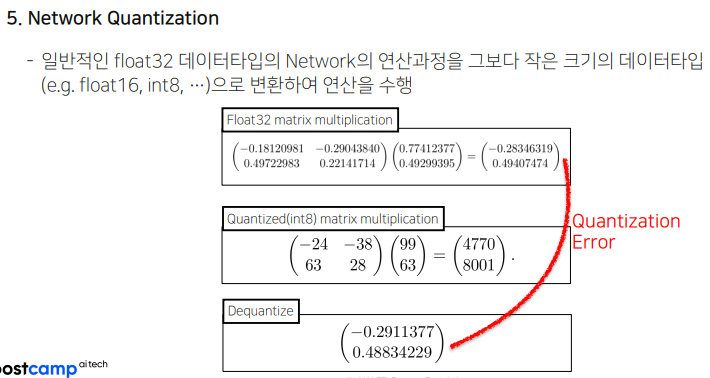
Quantization Error가 있더라도, Robust하게 잘 적용된다는 것이 경험적으로 많이 알려짐. 많이 적용되는 기술.
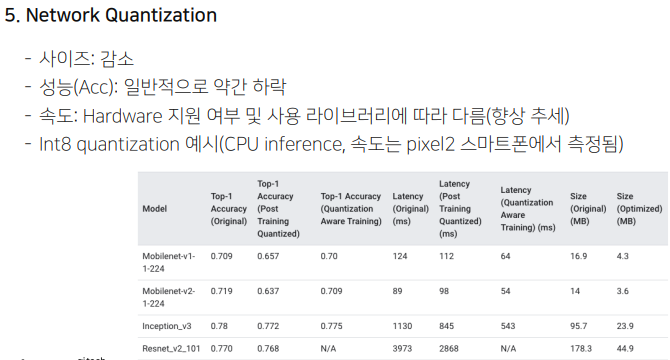
어떤 경우에는 호환성 문제가 있어서 int로 디퀀타이즈 하더라도 속도가 느려질 때도 있음.
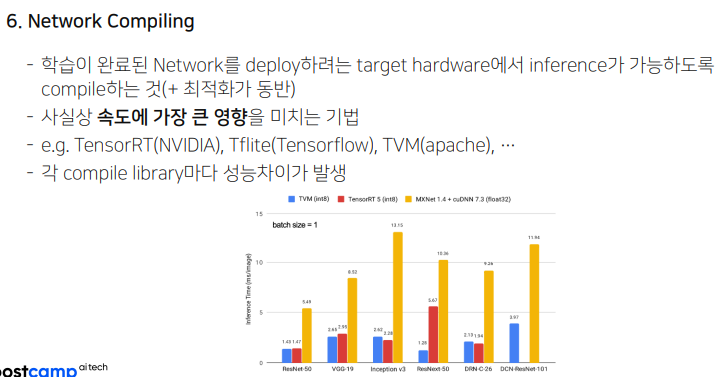
가장 복잡하면서도 가장 중요하다. 속도에 굉장히 큰 영향을 미침. 일반적으로 우리가 다루기에는 굉장히 디테일 하고 딥하다.
노란색 original보다 훨씬 성능이 좋아지는 모습!! 다만, 네번째를 보면 각 컴파일 라이브러리마다 성능차이가 있는 모습이다. 왜그런걸까?
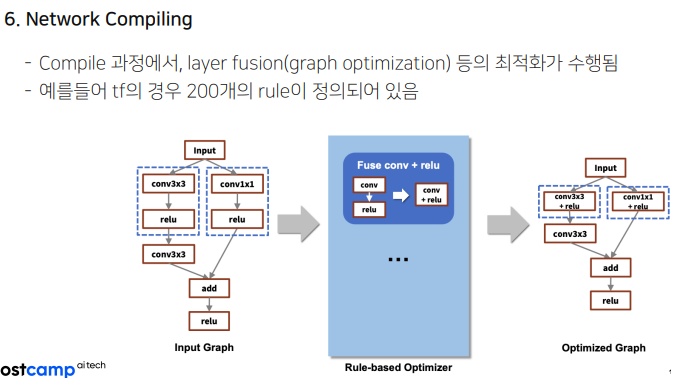
Layer Fusion이 tf에서 일어남. 한번에 할 수 있는 연산을 굳이 두번에 나누어서 하지 않도록 200개의 rule-based로 최적화 할 수 있게 했다.

문제는, 하드웨어의 스펙이 모두 다르고 프레임워크와 백엔드도 다르다.
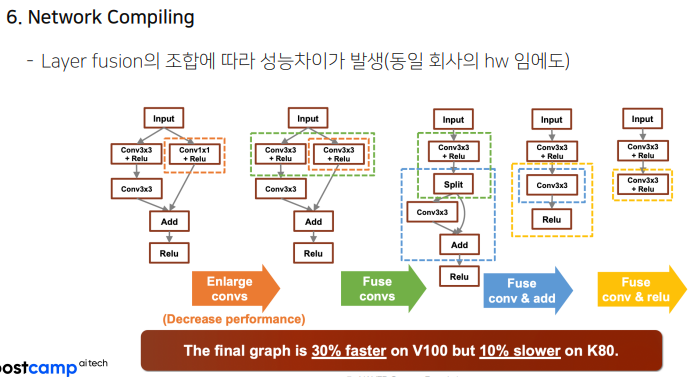
퓨징을 하는 결과에 따라 성능이 모두 달라진다. 동일 제조사의 하드웨어인데도 말이다.

AutoML로, Sofrware2.0으로 그래프의 좋은 퓨전을 찾는 시도.
2. 강의 목표, 구성


세 가지 주요 토픽을 다룰것임.