History
220322 1-10p | 1.1 ~ 1.3.1.1
220324 11-20p | 1.3.1.2 ~ 1.4.1
220409 21-30p | 1.4.2 ~ 1.8
1.1 Introduction
여러 종류의 추천시스템에 대해 소개할 것. 또, 서로다른 도메인의 추천시스템을 소개하고 성능을 향상 시키는 방법을 다룰 것. 모델의 robustness를 다양한 측면에서 다룰 것이고 모델의 하이브리드(=혼합) 버전들을 평가할 것임.
1.2 Goals of Recommender Systems
추천할 수 있는 두가지 방법
1) Prediction version of problem
- user가 평가하지 않은 item에 대해 유저가 할 것 같은 평가를 예측하는 것.
2) Ranking version of problem
- 정확한 평가를 예측하기 보다는, 몇 개의 아이템들을 추천해주는 것.
추천시스템의 조건
- 수익을 증가하기 위한 비즈니스 중심적 목표를 확장하기 위해서 필요한 추천시스템의 4가지 조건
1) Relevance
- 가장 중요하고 명확한 목표. 유저가 좋아할 것 같은 아이템을 직접 손에 쥐어주어야함.
- 제일 중요하지만, 이 혼자만으로는 부족함 나머지 조건도 필요. 중요도는 비교할 수 없을 정도로 Relevance가 제일 중요하지만 그래도 나머지 조건이 필요.
2) Novelty
- 새로워야 함. 참신해야 함. 이전에 본적 없던 아이템을 추천해줘야 함. 매일 똑같은 것만 추천해주면 질리기 마련.
- 유명한 아이템만 추천해 주는 것은 다양성을 해치고 수익 감소로 이어짐.
3) Serendipity
- Novelty와 비슷한 개념이긴 한데, 이전에 유저가 "몰랐던 아이템"을 추천해줘서 유저가 알게하는 것을 의미하는 Novelty와는 다름. 그대신 "몰랐던 아이템"이 아닌 "몰랐던 취향"을 알게해서 새로운 관심사가 생기게 하는 것.
- 이전에 SF영화를 본적이 없는 사람이 우연히 이런 종류의 영화를 추천받아 지속적으로 보게 된다면 이것은 이 사람이 SF영화를 싫어해서 보지 않은 것이 아니라 좋아하는지 싫어하는지 알지 못했다가, 추천을 통해 호불호(여기 예시에서는 호)를 파악해서 알게된 것을 의미
4) Increasing recommnedation diversity
- 유저가 k개의 아이템을 추천받을 때 이 아이템들의 종류가 다 다른것이 더 좋음. 왜냐하면, 종류가 다 같아서 비슷비슷한 아이템들을 추천받았을 때 유저가 한 아이템을 싫어하면, 나머지도 싫어하는 것이 되며, 차라리 여러 종류의 아이템을 추천해 그 중 하나라도 좋아할 수 있도록 하는 것이 좋음
- 물론, 대박일 때는 대박임. 한 아이템을 너무 좋아했는데, 그것과 비슷한 아이템들이 모두 추천되었으니. 마치 분산투자 개념과 비슷.(이런말은 안써있고 내 생각임)
1.2.1 The Spectrum of Recommendation Applications
구글는 검색을 통해 해당 검색어와 관련된 광고를 추천한다. 검색어와 관련된 검색어가 아니라 검색어와 관련된 광고를 추천하지만 이 역시 추천시스템이다. 페이스북은 주변 친구를, 온라인 채용 사이트는 고용주와 구직자 서로를 추천해준다. 특히 채용의 경우 이를 reciprocal recommender라고 부른다. 이러한 모델들은 기본적인 추천시스템과 많이 다르며 그 차이에 대해 추후에 자세히 언급할 것이다.
1.3 Basic Models of Recommender Systems
기본적인 추천시스템은 두 가지 종류의 데이터를 이용하는데 하나는 1) 평점이나 구매내역 같은 유저-아이템 interaction이고 다른 하나는 2) 유저의 텍스트 정보나 아이템과 관련된 키워드 정보 같은 속성 데이터임. 1)을 이용하면 협업 필터링, 2)를 이용하면 컨텐츠 기반 필터링이라고 함. 물론 평점은 1)과 2) 둘 다 이용하는 데이터인데, 2)컨텐츠 기반 필터링의 경우 전체 유저의 평점보다는 단일 유저의 평점에 보통 초점을 맞추어 이용함.
3)지식 기반 추천시스템은 직접적으로 언급된 유저의 요구사항에 기반함. 평점이나 구매내역 대신에 추가적인 정보들과 조건들이 추천에 사용됨. 그래서 1,2,3)을 섞은 하이브리드 방식을 사용하기도 함. 이 방식은 좀 더 robust하고 다양하게 세팅이 가능함.
1.3.1 Collaborative Filtering Models
협업 필터링은 말 그대로 "협업"의 효과를 내는 방식임. 여러 유저의 피드백(=평가)을 가지고 추천을 하는 방식인데, 주 문제점은 대부분의 데이터가 모든 유저의 피드백을 받지 않기 때문에 한 데이터에 대해 여러 유저의 피드백이 없다(=희소하다)는 것임. 앞으로 유저가 평가한 행위를 "specified" 또는 "observed" 라고 할 것이며 유저가 평가하지 않은 행위를 "unobserved" 또는 "missing" 이라고 할 것임.
협업 필터링의 아이디어는 다양한 유저와 아이템들 사이에서 평가 데이터들이 밀접한 상관관계를 가지고 이로 인해 아직 평가되지 않은 데이터를 예측할 수 있다는 것. 앨리스랑 밥의 취향이 비슷하면 아마도 그들이 매기는 평가 역시 비슷할 것임. 따라서, 둘 중 한명만 평가를 했다고 하더라도, 평가하지 않은 사람의 평가는 평가를 한 사람의 평가와 비슷할 가능성이 높음.
협업 필터링의 이러한 예측은 유저 기반의 상관관계 또는 아이템 기반의 상관관계로 이루어지며 둘 다 이용하는 모델도 있음. 또 지도학습으로 분류 모델을 학습시키는 방법을 여기에 적용시키기도 함. 이러한 방법의 두 가지 유형을 소개하겠음.
1) Memory-based methods
- neighborhood-based collaborative filtering algorithms 이라고도 함.
- user-item combinations을 가지고 neighborhood의 값을 예측하는 방법.
- neighborhood를 어떻게 정의하냐에 따라 두 가지 방법으로 나뉨
- 1.1 User-based c.f
- 기준이 되는 유저 A와 마음이 비슷한 유저들의 평가를 예측하는 방법.
- 앨리스와 밥의 취향이 비슷할 때 앨리스는 보고 밥은 보지 않은 영화에 대해서, 앨리스의 평점을 가지고 밥의 평점을 예측한다.
- 유사도 함수는 평가 행렬의 행을 사용함
- 1.2 Item-based c.f
- 특정 유저 A가 선택한 기준 아이템 B에 대한 평가를 예측하는 방법. (그러니까 A는 아이템 B를 평가하지 않았고, 이를 예측하겠다는 것)
- 아이템 B와 유사한 아이템들을 찾아야 하며 이 때 이 아이템들은 A가 평가를 과거에 한 아이템들임. 이 아이템들이 아이템 B와 유사한데, 이 아이템들에 대한 A의 평가가 좋으면 이 아이템과 유사한 아이템 B의 평가도 좋을 것이라 예상.
- 유사도 함수는 평가 행렬의 열을 사용함
- 이 방법의 장점은 구현이 간단하고 설명력이 있음. 반면에, 희소 행렬에 대해서는 잘 작동하지 않음. 왜냐면 A랑 비슷한 유저를 찾기 힘들거나, B랑 비슷한 아이템을 찾기 힘든 경우에는 효과적이지 않을 것이기 때문.
- 상위 k개의 아이템이 필요할 때는 희소 문제가 자주 발생하지는 않으며 2장에서 자세히 설명할 것임
2) Model-based methods
- 여기서는 모델의 문맥적 추론을 위해 머신 러닝과 데이터 마이닝 기법이 사용됨. 최적화 방법에 따라 모델이 파라미터를 학습하며 예로는 결정 트리, 규칙 기반, 베이지안, latent factor 모델이 있음. 특히 latent factor같은 모델은 희소 행렬에 대해서도 고수준의 역량을 가짐. 이는 3장에서 설명할 것
memory-based가 간단하긴 해도 휴리스틱하기 때문에 늘 잘 작동하지는 않음. 또, memory기반도 유사도를 구할 때 모델(이 모델은 휴리스틱 하긴 함)을 사용할 수 있기 때문에 치만 memory기반이냐 model기반이냐도 굳이 구분을 하기에는 억지인 부분이 있음. 보통 둘을 섞어서 쓰는 것이 가장 좋은 성능을 냄.
1.3.1.1 Types of Ratings
추천 알고리즘은 tracking rating system의 영향을 받았음. 보통은 크기가 있는 값으로 rating이 되는데, Jester joke은 -10부터 10까지의 연속적인 수로 평가할 수 있도롥 함. 이는 흔한 방식은 아니고 보통은, 각 rate별로 간격이 있는, 이산표현으로 선호도를 표현했음.
이러한 rating은 몇 점 만점으로 하든 다 가능함. 보통 5, 7, 10점 사용. 이러한 점수로 유저의 선호도를 분석할 수 있는데 이는 플랫폼에 따라 다르게 해석됨. 넷플릭스의 경우 4점은 정말 좋아한다는 뜻이고 3점은 좋아한다는 뜻이라서 1, 2점이 좋아하지 않는다는 뜻인데 이는 평가에 있어서 불균형을 초래함. 또, rating choice가 짝수개여서, 중립을 표할 수 없는 시스템도 있음.
{짱시룸, 시룸, 그럭저럭, 조움, 짱조움}처럼 점수가 아니라 범주형 rating을 쓰기도 함. 이를 ordinal ratings라고 함. binary ratings의 경우 좋다 싫다 그리고 무응답으로 나뉨.
불호를 표현할 수 없는 rating 방식도 있음. 이를 unary ratings라고 함. 이런 방식은 특히 간접(=implicit) 피드백 방식으로 얻어진 데이터 셋에서 적용됨. 예를 들어 유저의 구매 행동은 해당 아이템을 선호 한다고 볼 수 있지만, 구매하지 않았다고 해서 해당 아이템을 선호하지 않는다고 볼 수는 없음. Facebook같은 SNS에서도 좋아요 버튼만 있지 싫어요는 없음.
Examples of Explicit and Implicit Ratings
rating matrix는 m명의 유저와 n개의 아이템으로 이루어진 m x n 행렬임. m과 n은 항상 같지는 않음. 이 rating matrix는 utility matrix라고도 불림. 엄격히 얘기하자면 utility가 총 수익을 의미한다고 할 때, user-item combination에서 utility의 의미는 특정 유저에게 아이템을 추천함으로써 얻게 되는 수익을 의미함. 특히 rating matrix와 같은 경우 domain-specific한 기준에 근거해서 utility value로 변환하는 작업이 이루어질 수 있음. 모든 협업 필터링 알고리즘은 rating matrix대신 utility matrix를 사용하는데, 이는 실제 필드에서는 흔하지 않기 때문에 대부분은 그냥 바로 rating matrix를 사용하는 편.
unary rating matrix의 예시는 그림 1.3에서 확인할 수 있음. positive preference utility matrix로 간주되는데, 이는 positive preference 지표만 표현되기 때문임. 이러한 행렬은 표현력이 낮음. 왜냐하면, dislike에 대한 표현은 할 수 없고 표현을 하지 않자니 unobserved와의 차이가 모호하기 때문임. 또, rating matrix와 비교하면 설명력의 차이 때문에 해석또한 달라지게 됨. U1과 U3을 볼 때 (a)의 경우 두 유저의 취향이 다름을 알 수 있지만 (b)의 경우는 두 유저의 취향이 비슷하다고 할 수 있기 때문. 이런 점에서 (b)는 유저의 구매여부와 같은 지표에 해당하고 그래서 implicit feedback으로 간주됨.
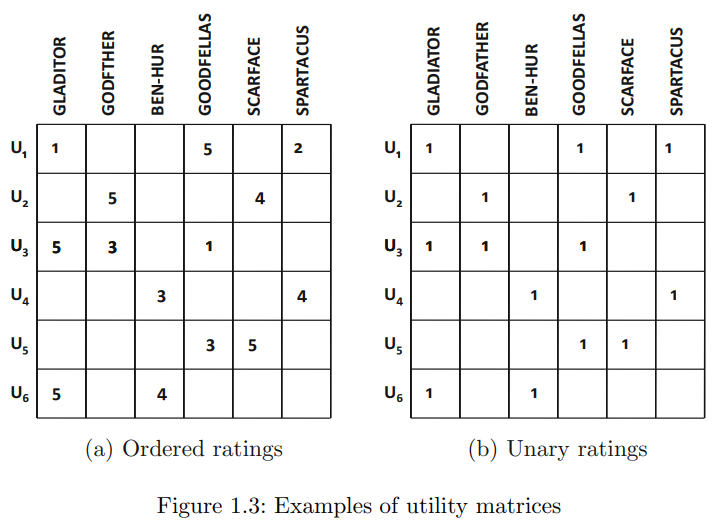
Unary rating은 추천 알고리즘에 직접적으로 미치는 영향이 상당한데, 이유는 유저가 아이템을 싫어하는지 아닌지에 대한 정보가 하나도 없기 때문임. (2점이냐 3점이냐의 차이는 미세할 수 있는 반면에 0점이나 1점이냐의 차이는 유무의 차이이기 때문에 이러한 점에서 상당하 영향을 미친다고 이야기하는 것 같음) unary matrix를 가지고 종종 추천을 할 때는 초기에 결측치를 0으로 간주함. 그리고 이후에, 어떤 아이템이 유저의 관심사에 부합하는 경우에는 이 값들이 학습 알고리즘을 통해서 0보다 큰 값들로 예측됨. 초기에 0의 값을 가지던 이러한 값들 중 제일 큰 값으로 예측되게 된 아이템이 추천됨. 가진만약 결측치가 0으로 대체되지 않으면 상당한 오버피팅이 발생하게 됨.
반면에, explicit ratings matrices에서는 결측치를 미리 대체하지 않음. 호와 불호가 이미 나타나있기 때문에 언제든지 결측치는 대체될 수 있음. 결측치를 어떤 값으로 대체하냐에 따라 상당한 편향을 보이게 되는데 unary rating은 0으로 대체하기 때문에 작긴 하지만 약간의 편향을 보이게 됨. (0으로 대체하는 것이 mean등의 값으로 대체하는 것보다 편향이 덜하다라는 의미인 듯) 편향이 작은 이유는, 대부분의 아이템을 어차피 유저가 구매하지 않을 것이기 때문에, 구매 여부와 같은 matrix는 unobserved data에 대해서 0으로 간주하는 것이 합리적임. 그래서 이러한 대체로 인해 오버피팅이 많이 줄어들 것임. (여기서 오버피팅이 많이 줄어든다고 하는 것에 대조군은 결측치가 있는 데이터를 제거했을 때를 의미함. 만약, 100개의 데이터 중에 결측치가 보이는 데이터를 제거하다보면 user-item interaction 특성 상 소수의 데이터만 남게 될 것이며 이들만 가지고 추천을 하게 된다면 오버피팅이 생길 것임) 0으로 대체하는 것은 계산량의 측면의 재미있는 결과가 있는데 이러한 trade-offs는 2장과 3장에서 다룰 것.
1.3.1.2 Relationship with Missing Value Analysis
협업 필터링 모델은 결측치 분석과 밀접한 관련이 있음. 결측치 분석에 관한 이전 논문들에서는 불완전하게 구성된 행렬에서 결측치를 대체했을 때의 문제를 구했음. 협업 필터링의 경우는 이 문제가 발생하면서 행렬이 크고 희소하기 때문에 특별한 케이스라고 할 수 있음. 이러한 문제의 해결책이 추천 시스템에 적용될 수 있었음. 그치만 크고 희소한 행렬에 대해 latent factor와 같은 추가적인 해결책이 필요함. 많은 결측치 추정 방법이 협업 필터링에 쓰이고 있음.
1.3.1.3 Collaborative Filtering as a Generalization of Classification and Regression Modeling
협업 필터링은 분류, 회귀 문제의 일반화 버전임. 분류-회귀 문제에서는 클래스/종속변수는 결측치의 속성으로 볼 수 있음. 추천시스템에서도 결측치를 예측해야 하고, 분류-회귀 문제에서도 이러한 클래스(예를 들어 감성분석이면 이 문장이 긍정인지 부장인지)를 예측해야 하기 때문. 또, 다른 컬럼들은 피처/독립변수로 볼 수 있음. 차이점이 있다면, 감정분석의 예시에서는 모든 행의 특정 열(=피처)이 비어있는 일이 없는데 반해 추천에서는 모든 열이 결측치를 가질 수가 있음. 결국, 분명한 차이를 이야기하자면 클래스/종속변수와 피처/독립변수의 구분이 없고 각각의 열은 두 개의 역할을 동시에 할 수 있음. 반면에, 분류-회귀 문제는 특정 열만 결측치(=우리가 예측해야 하는 클래스)가 있어야함. 그래서 추천에서는 train rows와 test rows는 구분되어 있지 않고 이런 entry로 구분하는 것이 의미가 있음. 이러한 차이에도 불구하고 분류-회귀에 적용되는 알고리즘등은 추천에 적용될 수 있고, 적용되어왔으며 각각의 challenge들은 상호보완의 관계(추천시스템에 적용된 알고리즘을 회귀나 분류에 적용하거나 또는 그 반대)를 가질 수 있기 때문에 중요한 관계를 가진다고 할 수 있음.
Matrix completion은 classification과 regression의 transductive setting과 많은 공통점이 있음. transductive setting(비지도학습을 의미하는 듯)의 학습 과정에서는 예측을 하기가 어려운데 반해 inductive setting(지도학습을 의미하는 듯)의 학습 과정에서는 예측을 하기가 쉬움. 예를 들어 베이지안 모델은 빌딩되는 과정에서도 잘 모르는 feature에 대해 예측하기 쉬움.
matrix completion은 본질적으로 transductive임. training set과 test set이 행렬안에 밀접하게 모여있기도 하고 unseen data에 대해 예측하는 것이 쉬운일이 아니기 때문. 예를 들어 specified rating이 많은 John이라는 유저가 추가되었을 때 협업 필터링 모델은 이미 구축되어 있기 때문에 John에게 추천을 해주기 힘듦. 추천을 해주려면 구축된 모델을 수정해야 하므로. 특히 협업 필터링 중 model-based 방법들이 그러함. 그러나 최근의 matrix completion 모델들은 inductive하게 설계되는 추세여서 쉽게 예측할 수 있음
1.3.2 Content-Based Recommneder Systems
Contents-based 추천 시스템은 아이템을 잘 설명할 수 있는 특징을 사용해 추천하는 방식임. content 자체는 이러한 특징을 의미함. John이 터미네이터 영화에 고점을 줬다면 터미네이터 영화의 "장르" 라는 특성은 터미네이터를 (매우 잘은 아니더라도 충분히) 잘 설명해주며 따라서 이 "장르" 라는 특성을 가지고 유사한 다른 영화를 추천해줌.
구체적인 방법으로, rating으로 labeled된 아이템 특징은 유저 전용의 분류 또는 회귀 모델을 만들기 위해 학습 데이터로 사용됨. 유저의 "구매함" 또는 "평가함" 등의 interaction이 있는 아이템을 가지고 interaction이 없는 아이템에 대해 "구매할 것인가" 또는 "평가할 것인가"를 예측하기 위함임.
어떤 아이템이 rated 되었는지에 대한 정보가 없더라도 아이템의 feature만을 이용하기 때문에 새로운 아이템의 feature만으로도 추천할 수 있다는 장점이 있음. 그래서 지도학습 모델은 이 아이템의 feature와 rating의 결합을 잘 이용해서 추천을 잘 할수 있음.
그치만 다음과 같은 단점또한 있음
1) 대부분의 경우 키워드랑 컨텐츠를 사용하기 때문에 설득력있는 추천을 할 수 있음. 근데 이 방법은 커뮤니티에서 비슷한 유저들은 전혀 고려하지 않고 특정 유저 전용으로 추천해주기 때문에 다양한 아이템을 추천하히가 어려움.
2) 새로운 아이템도 추천할 수 있지만 새로운 유저에 대해서는 추천하기가 어려움. 우리가 학습한 모델은, 새로운 아이템에 대한 rating은 필요없어도 target user의 rating history는 필요하기 때문. 또, 이러한 history가 많아야 robust한 결과물을 줄 수 있음
그래서, contents-based는 collaborative filtering과 trade-offs의 관계를 가짐.
지금까지 이야기 한것들은 과거의 학습 방식이며 좀 더 개선된 방법들은 가끔씩 사용됨. 만약 유저가 그들의 취향을 설명하기 위해 구체적인 키워드를 언급했다면 이를 item의 특징과 match하기 위해 이 방법을 사용해야 할 것임. 이 때는 추천에 rating 정보를 쓰는 것이 아니기 때문에 cold-start에 대해서도 굳건함. 그치만 이런 방법론은 기존의 것과 구분되는 특징이 있기 때문에 다른 추천시스템으로 간주될 때도 있음. 그것이 바로 knowledge-based systems. 왜냐하면 추천을 위해 matching하는 지표나 속성들이 domain-specific하기 때문임. knowledge-based system은 content-based system과 매우 연관성있으면서도 때때로 두 system간의 분명한 경계에 대해 논의되곤 한다. contents-based recsys는 4장에서 이야기 할 것이다.
1.3.3 Knowledge-Based Recommender Systems
이 방법은 매우 자주 구매되지 않는 아이템의 context를 이용할 때 특히 유용하다. 부동산이나 자동차, 여행이나 재정 서비스 또는 고가의 사치품들이 여기에 해당한다. 이 경우, 충분한 rating이 있기가 힘들다. 각각의 품목마다 특징도 다르고 고가여서 거래도 적게되기 때문. 결국 cold-start 문제에 직면하게 된다. 뿐만 아니고 소비자의 선호 역시 시간이 지날수록 달라질 수 있다. 예를 들어 자동차 모델들은 진화해왔는데 이 근거는 그에 상응하는 선호도라고 할 수 있다. 자동차는 이렇게 설명할 수 있어도 다른 예시는 이러한 패러다임 또한 파악하는게 쉽지 않을 수도 있다. 굉장히 다양한 특성들과 상응할 수도 있고 유저는 이 많은 특성중의 일부만을 선호할 수도 있다. 자동차로 예를 들면, 색이나 모델, 엔진이나 인테리어 등의 선택지가 주어지며 이들을 조합함으로써 유저의 흥미도를 한정지을 수 있다. 결국, item domain은 다양한 특징들의 관점에서는 복잡할 수 밖에 없고 다양한 선택지의 조합이 있다보니 각 조합마다 충분한 data가 존재할 가능성이 적다.
이럴 경우 rating이 필요없는 knowledge-based recsys이 쓰인다. 유저의 니즈와 아이템의 특징이 비교되거나 제한적인 기술 방식으로 유저의 니즈가 표현된다. knowleddge bases란 정보 수집기간동안 사용되는 rule이나 similarity function의 data를 의미한다. 협업 또는 컨텐츠 기반은 유저의 history 또는 neighbor의 history 또는 이 둘의 combination으로 구성되는데 비해 knowledge-based는 유저에게 구체적인 니즈를 수집하는 유일한 방법론이다.
knowledge-based recsys는 knowledge라 불리는 interface의 유형에 기반해 구분된다.
1) Constraint-based recsys : 유저가 일반적으로 아이템의 특징에 대해 요구사항이나 제약사항을 명시. user requirements를 item attributes에 맞추기 위해 특정 form을 취하는 방식으로 rule이 작용함. 이러한 form은 아래와 같음. 조건에 맞는 아이템의 수와 종류에 따라 그들은 원래 요구사항을 수정할 가능성도 있음. (100% 맞는 아이템은 없을 수 있으므로) 조건에 맞는 아이템이 너무 없으면 조건을 줄이거나 늘리거나 할 것임. 이 과정은 유저가 만족할 때 까지 이루어짐

2) Case-based recsys : 마찬가지로, 유저가 요구사항을 명시하는데 이 때 유저를 target으로 봄. item attributes에 대해 similarity metrics를 정의해서 user가 정의한 case와 비슷한 아이템을 가져오도록 함. 그 예시는 아래와 같음. similarity metrics는 domain-specific한 방법으로 신중히 정의됨. 그래서 이러한 similarity metrics는 특정 domain system에서만 사용되게 됨. 너무 specified 하다보니... 예를 들어, 유저가 요구사항을 입력했고(마치 쿼리같이) 이에 대해 유사한 아이템을 얻었을 때, 반환되는 아이템이 더욱 더 유저의 취향에 맞게 하기위해서 특정 요구사항을 수정할 수 있고 이에 대한 또 다른 결과가 반환되게 됨.
두 시스템은 유저에게 구체적인 요구사항을 명시할 수 있게 하지만 작동방식이 다르다. Constraint-based의 경우 rule을 가지고 추천을 하는 방식이며, 그래서 검색 시스템같은 폼을 사용해 요구사항을 구체화하게 됨. 예를 들어 방의 개수는 5개 이상과 같은 rule(= num of rooms >= 5)을 사용하게 됨. 반면 Cased-based는 similarity metrics를 사용하게 되고 유저의 요구사항은 하나의 기준점이 됨. 그래서 이 기준점과 유사한 아이템이 추천됨. Critiquing은 하나 이상의 요구사항을 변경하는 방식이며, 이 과정을 통해 다른 결과를 얻게되고 유저가 만족할 때 까지 이 과정이 이루어짐
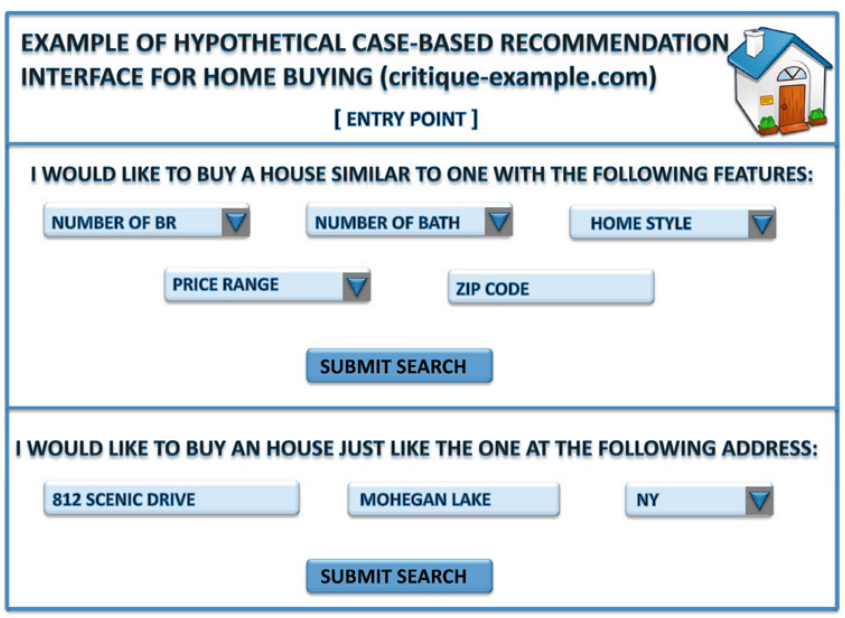
knowledge-based recsys에서 어떻게 이러한 상호작용이 이루어질까? 다음과 같은 방법을 통해 이루어짐
1) Conversational systems : feedback loop를 가지고 user preferences가 결정됨. item domain이 복잡하고 user preferences가 반복적인 대화형 시스템으로 결정될 수 있기 때문에 이러한 방식을 채택
2) Search-based systems : 사전에 준비된 질문을 가지고 유저의 선호도를 도출하는 방법.
3) Navigation-based recommendation : 추천된 아이템에 대해 많은 변경 사항을 명시하면 이 사항들을 가지고 타켓 item으로 추천해주는 방법. "지금 추천된 집보다 서쪽으로 5마일에 있는 비슷한 집을 원한다" 라고 변경 사항을 요구.
knowledge-based나 content-based는 아이템의 특성이 매우 중요함. 두 시스템 다 이런 특성을 이용하기 때문에 단점이 동일함. 그치만 history를 참고하냐 active specification을 이용하냐에 차이는 있음. 여러 형태의 knowledge-based recsys는 5장에서 다룸
1.3.3.1 Utility-Based Recommender Systems
item에 대한 유저의 선호 확률을 계산하기 위해서 product feautres에 대해 utility function을 정의하는 방법. 주된 챌린지는 적절한 utility function을 정의하는 것. utility value는 priori로 알려진 function에 기반함. 이러한 관점에서 external knowledge를 이용하는 것으로 볼 수도 있으며 그래서 knowledge-based recsys의 특별한 경우로 칭함.
1.3.4 Demographic Recommender Systems
인구통계학적 추천시스템은 유저에 대한 통계정보를 가지고 모델의 학습에 이용하는 방법. 20대 여자가 이 제품을 좀 더 많이 산다 같은 느낌의 통계적 추천. context-sensitive recommender systems의 방법론과도 관련이 있으며 8장에서 다룸.
rule-based classifier는 고객의 구매 행위를 인류통계학적 관점과 통합하기 위해 주로 사용하며 특정 아이템을 추천하는데에는 구체적으로 사용되지는 않지만 추천시스템의 보조 역할로 쉽게 부착이 가능함. 통계학적 특징은 독립변수로, 구매 행위나 평가등은 종속 변수로 간주한다는 점에서 순수 회귀-분류 모델과는 차이가 있음. 이러한 시스템은 독립적으로 사용될 때는 큰 성능은 못내지만, knowledge-based 추천시스템과 같은 다른 추천 시스템과 결합함으로써 마치 앙상블이나 하이브리드 시스템과 같은 효과를 낼 수 있게하여 model의 robustness에 이바지함.
1.3.5 Hybrid and Ensemble-Based Recommender Systems
앞서 말한 3개의 시스템은 서로 다른 데이터를 사용하기 때문에 서로 다른 필드에서 효과적임. 협업 필터링은 community ratings에, content는 target user's rating과 textual description에, knowledge-based는 user's linking을 파악하기 위한 interaction에 의존적임. 각각의 시스템은 장단점과 세팅이 다른데, 지식 기반 시스템은 cold-start에 강하고 협업의 경우 데이터가 많을 때 효과적임
inputs의 종류가 다양할 수록 여러개의 추천 시스템을 사용할 수 있는 유연성이 생김. 하이브리드 방식은 앙상블의 관점에서 일반화할수 있다는 점에서 좋은 성능을 냄. 6장에서 이를 다룸
1.3.6 Evaluation of Recommender Systems
몇 개의 추천 알고리즘이 주어졌을 때 성능 파악을 할 수 있어야 함. 분류-회귀 문제는 행렬에서 특정 열을 예측해야 하는 반면에 추천의 경우 특정 행이나 열이 아닌 특정 인덱스를 예측해야 한다는 점에서 분류-회귀 문제보다 더 넓은 범주의 일반적인 문제로 볼 수 있음. 그래서 분류-회귀 문제에 쓰이는 평가 방식을 조금의 수정을 거치면 추천에도 사용할 수 있음. rating prediction은 분류-회귀와 관련이 있고 ranking은 검색이나 정보 추출과 관련있음
1.4 Domain-Specific Challenges in Recommender Systems
온도, 지역, 사회 데이터와 같은 여러 도메인에서 추천에 필요한 문맥정보는 중요한 역할을 함. 그래서 각각의 도메인 지식에 따라 다르게 추천시스템이 개발되었음
1.4.1 Context-Based Recommender Systems
context-based나 context-aware 추천 시스템은 다양한 타입의 정보를 추천에 활용함. 시간, 장소, 사회적인 일등이 이러한 context에 해당. 옷을 판매하는 사람에게는 계절이나 장소가 중요하고 소비자의 여가활동에는 휴일이나 축제같은 행사등이 중요하게 작용함.
이러한 정보는 여러 도메인과 매우 밀접한 관련이 있어 사용하면 성능이 굉장히 좋아짐. 추후에 context-specific rec를 위한 다차원 모델을 사용하면서 다시 환기할 것임. context-aware recsys는 8장에서 다룰건데, time, location과 같은 context의 개별적인 측면은 다른 챕터에서 더 자세히 다룰 것임
1.4.2 Time-Sensitive Recommender Systems
여러 환경에서 시간이 지날수록 아이템 추천은 변화함. 개봉 당시의 영화를 추천해주는 것과 3년이 지난 영화를 추천해 주는 것에는 분명한 차이가 있음. 따라서, 추천에 시간 정보를 고려하는 것은 매우 중요함. 시간 정보에 관해서는 다음과 같은 두 가지 시각이 있음
1) 여론이나 유저의 흥미는 시간이 지날수록 바뀌기 마련. 유저의 선호도는 시간이 지남에 따라 변화한다
2) 유저의 선호도는 특정 시점에 따라 변화한다. 겨울이 되면 두꺼운 옷이 추천되는 것처럼.
첫번째는 시간 정보를 협업 필터링의 explicit paramter로, 두번째는 context-based의 특별한 경우로 볼 수 있다. 이렇게 시간 정보를 이용하는 추천시스템은 안그래도 sparse matrix문제에 대해 temporal context가 더 악화시키는 문제가 있어서 대용량 데이터셋을 사용하는 것이 특히 중요하다.
1.4.3 Location-Based Recommender Systems
지역을 기반으로 추천할 수도 있음. 공간적 지역성을 이용한 두 가지 방식이 있음
1) User-specific locality : 유저의 위치가 선호도에 큰 영향력이 있다는 전제. 뉴욕에 사는 사람들과 뉴욕과 위스콘신에 사는 사람에게 추천을 했을 때 전자가 좀 더 비슷할 것이다. preference locality라고도 함.
2) Item-specific locality : 아이템의 위치가 선호도에 큰 영향력이 있다는 전제. 보통 유저는 본인이 좋아하는 아이템과 비슷한 아이템들이 멀리있는 것을 좋아하지는 않을테니. travel locality라고도 함.
preference locality와 travel locality는 꽤 다르며 전자는 context-sensitive system, 후자는 ad hoc heuristics임. 특히 전자는 최근 GPS의 대량 보급으로 관심이 증가하는 추세.
1.4.4 Social Recommender Systems
이 시스템은 network structures, social cues, tags 그리고 다양한 network 요소의 결합 기반으로 구성됨. structure가 기반인 시스템은 node와 link를 추천하고 그 외에는 social cues등을 이용해 제품들을 추천함.
1.4.4.1 Structural Recommendation of Nodes and Links
node와 link로 구성된 social network에서 많이 쓰이는데, WebSearch 역시 그래프 구조이기 때문에 node rec.가 적용될 수 있음. 이런 문제들은 많은 ranking algorithms을 필요로 하고 그 중 하나가 PageRank algorithm 또는 personalized PageRank algorithm으로 불리는 알고리즘. 어떤 노드가 관심있어 하는 다른 노드들을 학습 데이터로 사용해, 아직 관심이 있는지 없는지 모르는 노드들을 예측할 수 있게 훈련함. collective classification이라고도 불림. sns에서 유저들에게 친구들을 소개하는 방법으로 추천이 많이 되며, 이러한 link prediction은 ranking 방법과 비슷해 한쪽에서 효과적인 해결책은 다른쪽에서도 효과가 있음. 또, 그래프 문제로도 변환할 수 있음. 10장에서 추후에 다룸
1.4.4.2 Product and Content Recommendations with Social Influence
제품 추천의 많은 유형은 network connection과 social cue의 도움으로 수행됨. 그래서 바이럴 마케팅으로도 불림. 일단 어떤 제품을 유저들에게 익숙하게 만드는 추천 방식이며 그래서 영향력있는 node를 찾는것이 중요함. influence analysis 라고도 불림.
1.4.4.3 Trustworthy Recommender Systems
유저가 호불호를 직접 표현하거나 다른 유저의 리뷰에 호불호를 표현할 수 있는데, 이러한 특징은 굳건한 추천시스템을 만들 때에 좋음. 11장에서 다룸
1.4.4.4 Leveraging Social Tagging Feedback for Recommendations
유저는 다양한 방법으로 feedback을 제공하는데, 대표적인 방법이 태그. 이러한 태그는 컨텐츠에 대해 유저가 짧은 정보나 키워드를 제공하는 meta-data임. 추천에 매우 효과적이며 context-sensitive rec.에 적용될 수 있음. 11장에서 다룸.
1.5 Advanced Topics and Applications
여러가지 토픽들에 대해 간단히 이야기하고 12~13장에서 자세히 언급함. 여기서 언급한 내용이 없을 수도 있음.
1.5.1 The Cold-Start Problem in Recommender Systems
추천 시스템의 주요 문제점 중 하나는 Cold-Start문제. 그래서 전통적인 협업 필터링에서는 더욱이 문제가 되었음. 컨텐츠 기반이나 지식 기반은 이 문제가 덜 작용하지만 문제가 되긴 마찬가지. 그래서 많은 방법이 등장했고 여러 모델에 대해 이러한 해결책이 얼마나 효과가 있었는지 이야기 할 것임
1.5.2 Attack-Resistant Recommender Systems
추천시스템은 제품 판매량에 지대한 영향을 미치기 때문에 누군가는 이를 조작하고 누군가는 이를 공격한다. 예를 들어, 제품 판매자는 리뷰를 조작해 긍정적인 리뷰만 존재하도록 하고 경쟁사는 악의적이고 부정적인 리뷰를 단다. 이러한 행위는 추천시스템의 질과 효과를 떨어뜨리기 때문에 이러한 공격에도 버틸 수 있는 robust rec.가 필요하다. 이러한 방법들은 12장에서 소개된다.
1.5.3 Group Recommender Systems
때때로는 개인보다 그룹에 맞춰 추천을 하는것이 효과적일 수 있음. 헬스장 회원들 개인개인이 아닌, 헬스장에 맞추어 음악을 선곡한다던가 등등. 초기에는 그룹 내 유저들의 선호를 집계해서 그룹 추천을 구성했지만, 단순히 평균 집계는 유저들이 다양하거나 이질적일수록 효과적이지 않았고 오히려 유저들간의 조율(또는 합의; 평균 낸 결과에 대한 추천을 감당하겠다는)보다는 여러 유저간의 상호작용이 가능한 추천시스템을 이용하는 것이 더 좋았음. 사람은 보통 감정 전염이나 감정 형성과 같은 사회 심리학적 현상에 의해 다른 사람의 취향에 영향을 많이 받기 때문. 자세한 내용은 13.4장에서 다룸
1.5.4 Multi-Criteria Recommender Systems
전체적인 rating이 비슷해도 해당 rating에 대한 criteria가 다를 수 있기 때문에 추천의 어려움이 있을 수 있음. sparse matrix에서는 더욱 더 challenge가 됨. group recsys에 적용되는 방법들이 multi-criteria recsys에 적용될 수 있음. 다만, 추천 프로세스의 다운 측면을 다룬다는 점에서 차이점은 있음. 13.5장에서 다룸
1.5.5 Active Learning in Recommender Systems
추천시스템은 충분한 rating이 있어야 robust한 성능을 내는데, 실제로는 그러기 쉽지 않다. 그래서 유저들에게 인센티브를 제공하며 피드백을 주기를 장려한다. 여기서, 이미 많은 rate를 한 유저에게 장려하는 것보다는, rate를 잘 하지 않은 유저에게 하는 것이 더 좋다. 또, 주로 rate되지 않은 항목에 대해서 장려하는 것이 좋다. 그렇지만, 주로 rate되지 않은 항목들은 유저들도 잘 보지 않았을 가능성이 높기 때문에 여러 trade-off가 있다. active learning methods들은 13.6장에서 다룬다.
1.5.6 Privacy in Recommender Systems
추천시스템은 유저의 피드백에 굉장히 의존적이게 되는데, 이 때 이러한 피드백은 개인의 정치적 의견이나 성적 취향등이 반영될 수도 있는데 굉장히 민감한 문제로 대두될 수 있다. 그치만 이런 정보들이 있어야 알고리즘 기술들도 발전할 수 있다는 입장도 있다. 예를 들면 Netflix가 그 예. 최근에 data mining에서 개인정보에 대한 다양한 문제들이 발생했기에 추천시스템도 예외는 아니다. 13.7장에서 자세히 보자.
1.5.7 Application Domains
추천시스템이 특정 도메인에 쓰일 때에는 특별한 방법들이 필요하다. 13장에서 3가지 recsys를 다룰 것.
1.6 Summary
이 책에서는 가장 중요한 알고리즘 들을 다룰 것이며 이들의 장단점과 적용되는 시나리오, 문제점과 효율성등을 다룰 것임
1.7 Bibliographic Notes
생략
1.8 Exercises
1) Explain why unary ratings are significantly different from other types of ratings in the design of recommender systems.

잘 정리해주셔서 감사합니당