
Go에서 슬라이스를 사용할 때, 표기법은 a[start:end]이다. 여기서 start는 포함되지만, end는 포함되지 않는다. 즉, start 인덱스부터 end-1 인덱스까지의 요소들이 선택된다.
Go뿐만 아니라 다른 언어에서 array를 분리할 때 start는 포함시키지만 end는 포함시키지 않는다.
특별한 이유가 있는걸까? 문득 의문점이 들어서 찾아보았다.
-
명확한 길이 계산:
end - start는 슬라이스의 길이를 직접 나타낸다. 예를 들어,a[1:4]는1, 2, 3의 세 요소를 포함하므로 길이는4 - 1 = 3입니다. 이는 길이 계산을 단순하고 명확하게 만든다. -
중첩 및 연속적인 슬라이싱 용이:
a[start:end]와a[end:x]형태로 슬라이스를 연속해서 사용할 때, 중복이나 빈 요소 없이 연속적인 슬라이스를 생성하기 쉽다. 예를 들어,a[0:5]와a[5:10]은a의 첫 번째 요소부터 열 번째 요소까지를 두 개의 슬라이스로 나눈다. -
경계값 처리의 간결함:
start와end가 슬라이스의 경계를 넘지 않도록 하는 것이 더 쉽다. 예를 들어,a[0:len(a)]는 전체 슬라이스를 나타내며, 이 때len(a)는 슬라이스의 길이를 초과하지 않는다. -
역사적 및 다른 언어와의 일관성: 이러한 방식은 다른 프로그래밍 언어, 예를 들어 Python에서도 사용되는 방식이다. 따라서 프로그래머들이 이미 익숙한 패턴을 따르는 것이다.
- 배열이 저장되는 방식: 메모리상에서 배열은 순차적으로 저장된다.
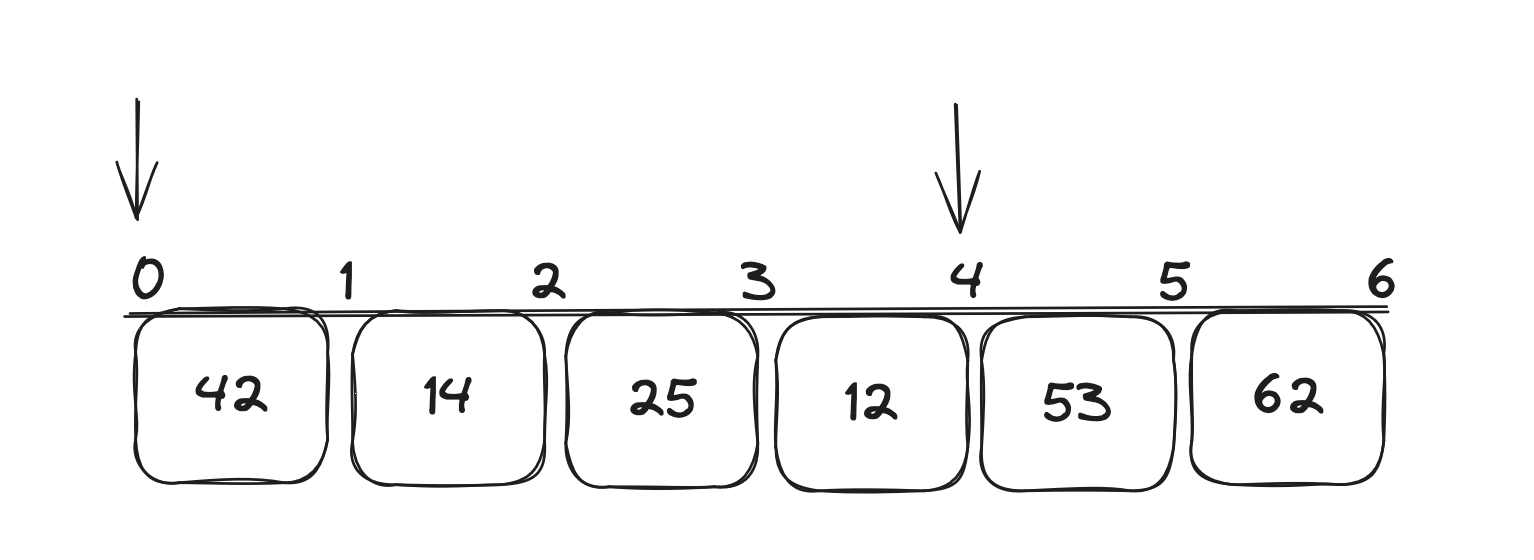
위에 그림을 보자. 메모리에서 배열은 위와 같이 저장이된다. index는 배열이 해당 값에 접근하기위한 계산에 사용된다. 다시 말해요소 하나의 사이즈 * index를 하면 해당 인덱스의 출발점에 도달하게되는 것이다. 그래서 0출발점에서 4출발점을 자르면 (arr[0:4]) index 4의 값은 포함되지 않는다.
이러한 이유들로 인해 Go의 슬라이스 표현은 사용하기 편리하고, 오류를 줄이며, 다른 언어들과의 일관성을 유지하면서 효율적인 프로그래밍을 가능하게 한다.
