
1. Sharding
way to divide indexes into smaller pieces
- each piece is called a shard
- sharding is done at index level
- main purpose is to horizontally scale data volume
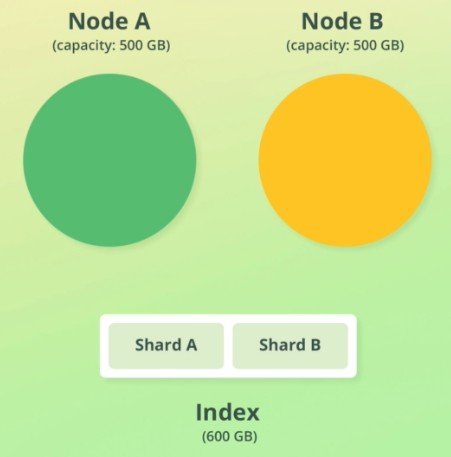
2. How Sharding Works
- Index is divided into shards
- Node can have multiple shards
- Each shard is an Apache Lucene index
- One shard can store two billion docs
-
sharding also improves performance by parallelizing queries
-
default number of shards in a index is 1
-
increase shards with Split API
-
decrease shards with Shrink API
3. Replication
fault tolerance machanism for ElasticSearch
ensures data availability on a different node if a node goes down
- configured at index level
- create copies of shards called replica shards
- a shard that has been replicated is called primary shard
- a primary shard and its replica shards are referred to as replication group
- number of replicas can be configured at index creation
4. How Replication Works
-
replica shards are never stored on the same node as primary shards
-
multiple nodes must exist for replication to work
- if only one node exist, replication is disable even if configured until additional node is added
-
number of replicas depends on availability, criticality of data, etc.

-
Replicas can also improve performance
- replica and primary can be used simultaneously
- ElasticSearch auto routes request to best shard
- if multiple replica shards are stored on the same node, CPU can parallelize
-
default number of replica per shard is 1
5. Replication vs Snapshot
- Replication saves "live data" and ensure that there is no data loss
- Snapshot save a specific state
- Replication cannot be used to revert changes that are already applied
6. Creating Index
-
create index from Kibana Console
PUT /{index_name}- cluster health is yellow(warning) if replica shard not allocated
- add node to allocate replica shard
-
check shards info from Kibana Console
GET /_cat/shards -
Kibana by default is set to
auto_expand_replicaswhich dynamically change number of replicas depending on the number of nodes in cluster
