
- Text values are analyzed when indexing docs
- the result is stored in data structures that are efficient for searching etc.
_sourceobject is not directly used when searching for docs
1. Analyzer
Analyzer processes text before data store
3 components of analyzer
-
Character filters
-
Tokenizer
-
Token filters
1-1. Character filters
Adds, removes, or changes characters
- there can be zero or more character filters that are applied in the order specified
ex) html_strip filter
1-2. Tokenizers
an analyzer contains one tokenizer. Tokenizing string into tokens
- characters may be removed as part of tokenization
ex) ["I", "really", "like", "beer"]
1-3. Token filters
Receive output of tokenizer as input. Token filters add, remove, or modify tokens
- analyzer contains zero or more token filters that are applied in the order specified
ex) lowercase filter
1-4. Default behavior of standard analyzer

- works on every text input by default
2. Analyze API
POST /_analyze
{
"text" : "2 guys wal into a bar, but the third... DUCKS! :-)",
"analyzer": "standard"
}Output
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<NUM>",
"position" : 0
},
{
"token" : "guys",
"start_offset" : 2,
"end_offset" : 6,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "wal",
"start_offset" : 7,
"end_offset" : 10,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "into",
"start_offset" : 11,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 3
},
...
]
}- Standard Tokenizer takes care of whitespaces, special characters, ellipses, etc.
// same request as using standard analyzer
POST /_analyze
{
"text" : "2 guys wal into a bar, but the third... DUCKS! :-)",
"char_filter" : [],
"tokenizer" : "standard",
"filter" : ["lowercase"]
}3. Inverted indexes
Field's values are stored in one of several data structures depending on it's data type, which ensures efficient data access
- Data Structures are handled by Apache Lucene
- One of the index data structure is inverted indexes
- Inverted index = mapping between terms and which docs contain them (terms = tokens by analyzer)
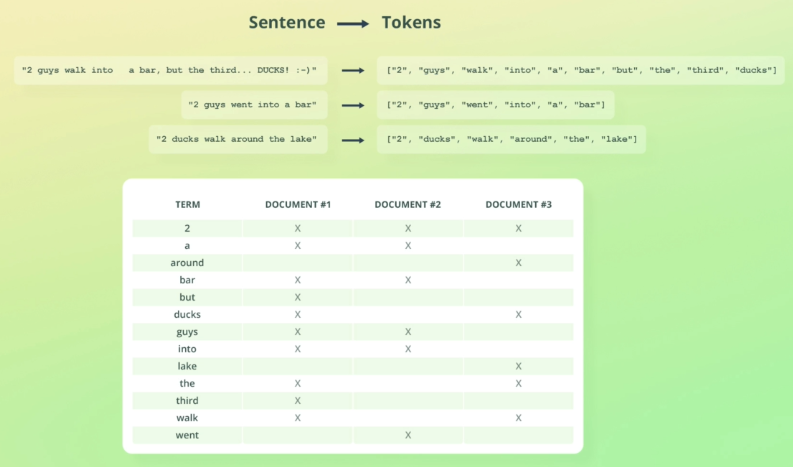
-
inverted index enables efficient search of docs by term
-
inverted index contain many information including relevance scoring
(rank by how well doc match) -
inverted index is created for each text field

-
fields with data type other than text uses different index data structures
- ex) numeric, date, geospatial data uses BKD trees
