실무에서 webflux와 webclient를 사용하는 API 게이트웨이에 작업하면서 내가 지금 뭐하고 있는건지 전혀 모르겠어서 스프링 공식문서를 정리한다. 다 정리하는게 목표는 아니고 일단 일하는데 필요한 만큼씩만 그때그때 정리한다!
1. 스프링 웹플럭스
스프링 웹 MVC는 서브렛 스택을 위해 만들어졌다. 당시에는 블록킹 API만 지원을 했었고, 이후 논블록킹 API를 지원하지만 기존 프레임워크들은 많은 부분 블록킹 API를 사용했다. 리액티브 스택의 웹 프레임워크인 스프링 웹플럭스는 나중에 5.0 버전에서 추가되었다. 웹플럭스는 완전히 논블락킹이고 리액티브 스트림 백프레셔를 지원하고 Netty, Undertow, Servlet 컨테이너와 같은 서버에서 동작한다. 둘 모두 스프링에서 옵셔널한 모듈로 어플리케이션은 둘 중 하나를 사용하거나 MVC에 WebClient처럼 둘 다 사용할 수도 있다
1.1 개요
웹플럭스가 탄생한 이유는 작은 고정된 스레드 수로 동시성을 처리하고, 적은 하드웨어 리소스로 스케일하기 위해 논블락킹 웹 스택이 필요했기 때문이다. 또 다른 이유는 함수형 프로그래밍이다. 자바 8부터 람다식을 지원하면서, 비동기적 로직의 선언적 합성을 하기 좋아졌다.
1.1.1 리액티브의 정의
- 변경에 반응(react)하는 것을 위주로 지어진 프로그래밍 모델을 말한다
- 예시로 io 이벤트에 반응하는 네트워크 컴포넌트나 마우스 이벤트에 반응하는 UI 컨트롤러가 있다
- 논블락킹은 리액티브하다고 할 수 있다, 왜냐하면 블록킹 되는 것과 달리 동작이 완료되거나 데이터가 준비되는 알림에 반응하는 형태가 되기 때문이다
- 리액티브에 중요한 요소 중 하나는 논블락킹 백프레셔이다. 동기적 명시적 코드에서는 블록킹하는 코드의 호출이 자연스럽게 호출자가 기다리도록 하는 백프레셔로서 역할을 한다.
(번역하기 귀찮아서 여기서부터는 영어로 정리) - In non-blocking code, controlling rate of event is important in order to prevent producer from flooding the consumer
Reactive Streamsdefines interaction between async components with back pressure- ex) data repo(Publisher) can produce data that HTTP server(Subscriber) can then write to the response
- main purpose of
Reactive Streamsis to let subscriber control rate of publisher producing data.Reactive Streamsestablish mechanism and boundary for publisher and subscriber - if publisher implementation for some reason cannot slow down, subscriber has to decide whether to buffer, drop, or fail
1.1.2 Reactive API
- because
Reactive Streamsis too low-level, higher level API is needed for application logic Reactoris reactive lib used in webflux. it providesMonoandFluxAPI to work on data seq 0..1 and 0..NReactorhas vocab similar toReactiveX- all operators in
Reactorsupport non-blocking back pressure - Webflux accepts
Publisherof Reactive Streams as input and returnsFluxorMono
1.1.3 Programming Models
spring-webmodule contains reactive foundation such asReactive Streamsadapter for servers and coreWebHandlerAPI (similar to Servelt API but non-blocking)- webflux provides two programming models 1) annoatated controllers 2) functional endpoints
- mvc and webflux both support reactive return types, but only webflux supports reactive @RequestBody
- in functional enpoints model, application is in charge of request handling from start to finish, unline annotated controllers
1.1.4 Applicability
- diagram below shows relationship between mvc and webflux
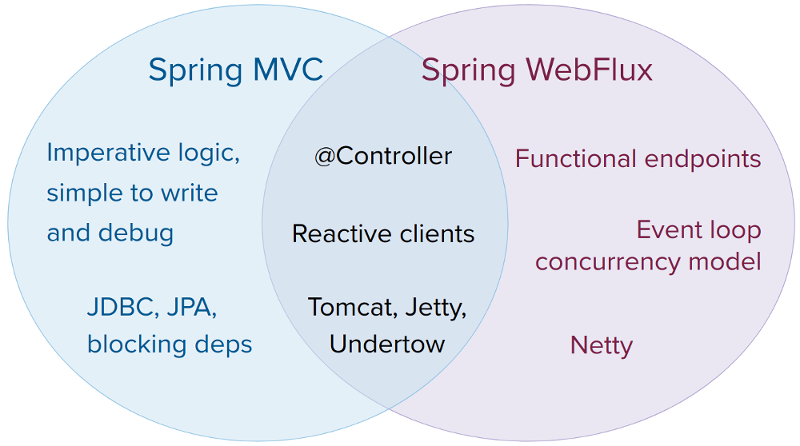
- tips on choosing between two stacks
- don't change if your current app work fine
- if interested in lightweight functional web framework, go for webflux with functional web endpoints
- check your dependencies. if rely on blocking persistence APIs such as JPA, use mvc
- when calling remote services on MVC app, consider using
WebClient. Greater the latency or dependency among calls, the more dramatic the benefits
1.1.5 Servers
- webflux supports
tomcat,jetty,servlet container,netty, andundertow - all servers are adapted to low-level, common api so that programming models can be supported across servers
spring-boot-starter-webfluxby default usesnetty- webflux relies on servlet non-blocking io and uses servlet api behind low-level adapter. servlet api is not exposed for direct use unlike mvc
- so instead of
javax.servlet.ServletRequestorjavax.servlet.Filterspring web abstraction such asorg.springframework.http.server.reactiveServerHttpRequestororg.springframework.web.server.WebFiltershould be used
- so instead of
1.1.6 Performance
- Reactive and non-blocking generally do not make app run faster. It actually requires slightly more processing time
- key benefit of reactive and non-blocking is ability to scale with small, fixed number of threads and less memory. Which makes app more resilient under load as it scales in a more predictable way
- in order to get benefits, latency such as network io is needed
- “To scale” and “small number of threads” may sound contradictory but to never block the current thread (and rely on callbacks instead) means that you do not need extra threads, as there are no blocking calls to absorb.
1.1.7 Concurrency Model
- MVC assumes that app can block current thread. servelt contain use large thread pool
- webflux assumes that app do not block. thus use a small, fixed-size thread pool (event loop workers) to handle req
- when invoking a blocking api is necessary, use
publishOnoperator to process on diff thread. But it is not recommended - because data is processed sequentially in reactive pipeline which is formed at runtime, app does not need to protect mutable state
- on webflux server without data access nor other dependenties, there is 1 thread for server and several others for req processing(typically equals to # of CPU cores). servlet containers may start with more thread to support both blocking and non-blocking io
WebClientoperates in event loop style. there may be fixed number of thread for it. However, if netty is used for both client and server, two share event loop resources by default- Reactor and RxJava provide thread pool abstraction called schedulers. It can be use with
publishOnoperator. shcedulers have names that suggest concurrency strategy.- ex) parallel for CPU-bound work with limited # of thread or elastic for io-bound work with large # of threads
- other lib may also create and use threads
1.2 Reactive Core
spring-web module contains foundational support for reactive web app. For server request processing, there are two levels of support. 1) HttpHandler: Basic contract for HTTP req handling. 2) WebHandler API: higher-level, general-purpose web API for req handling, on top of which annotated controllers anf unctional enpoints are built. For client side, basic ClientHttpConnector contract is there to performance HTTP req. WebClient is built on top of this. For client and server, codecs for serialization and deserialization of HTTP req and res content
1.2.1 HttpHandler
public interface HttpHandler {
Mono<Void> handle(ServerHttpRequest request, ServerHttpResponse response);
}- simple contract with single method to handle a req and res. only purpse is to be a minimal abstaction over different HTTP servier APIS
1.2.2 WebHandler API
org.springframework.web.serverpackage builds on theHttpHandlercontract to provide api for processing req thru chain ofWebExceptionHandler,WebFilter, andWebHandler- while
HttpsHandlersimply abstracts the use of different HTTP servers,WebHandlerAPI aims to provide a broader set of eatures commonly used in web app such as user session, req attributes, locale etc.
1.2.3 Filters
- In WebHandler API,
WebFiltercan be used to apply interception logic before and after the rest of the processing chain of filters and the target WebHandler
1.2.4 Exceptions
- In WebHandler API,
WebExceptionHandlercan be used to handle exceptions from the chain ofWebFilterinstances and the targetWebHandler
1.2.5 Codecs
- The
spring-webandspring-coremodules provide support for serializing and deserializing byte content to and from higher level objects through non-blocking I/O with Reactive Streams back pressure. ClientCodecConfigurerandServerCodecConfigurerare typically used to configure and customize the codecs to use in an application- Custom codecs can be used
val webClient = WebClient.builder()
.codecs({ configurer ->
val decoder = CustomDecoder()
configurer.customCodecs().registerWithDefaultConfig(decoder)
})
.build()
1.2.6 Logging
- In WebFlux, a single request can be run over multiple threads and the thread ID is not useful for correlating log messages that belong to a specific request.
- Which is why WebFlux log messages are prefixed with a request-specific ID by default
- on server side log ID is stored in ServerWebExchange.LOG_ID_ATTRIBUTE, ServerWebExchange#getLogPrefix()
- on WebClient side log ID is sotred in ClientRequest.LOG_ID_ATTRIBUTE, ClientRequest#logPrefix()
- Logging libraries such as SLF4J and Log4J 2 provide asynchronous loggers that avoid blocking. While those have their own drawbacks such as potentially dropping messages that could not be queued for logging, they are the best available options currently for use in a reactive, non-blocking application.
2. WebClient
WebClientis client to perform HTTP request for Spring WebFlux- it is fully non-blocking, supports streaming, and uses the same codec used to decode/encode req/res
WebClientrequires HTTP client lib to perform req. Reactor Netty, JDK HttpClient, etc. has built-in support- non-built-in clients can be plugged via
ClientHttpConnector
2.1 Configuration
- simplest way to create
WebClientis to usecreate()static factory method WebClient.builder()can be used to configure more optionsuriBuilderFactory: Customized UriBuilderFactory to use as a base URL.defaultUriVariables: default values to use when expanding URI templates.defaultHeader: Headers for every request.defaultCookie: Cookies for every request.defaultRequest: Consumer to customize every request.filter: Client filter for every request.exchangeStrategies: HTTP message reader/writer customizations.clientConnector: HTTP client library settings.
2.1.1 MaxInMemorySize
- default limit for codecs is 256KB
- change value like below
val webClient = WebClient.builder()
.codecs { configurer -> configurer.defaultCodecs().maxInMemorySize(2 * 1024 * 1024) }
.build()2.1.2 Reactor Netty
- To customize Reactor Netty settings, provide a pre-configured
HttpClient
val httpClient = HttpClient.create().secure { ... }
val webClient = WebClient.builder()
.clientConnector(ReactorClientHttpConnector(httpClient))
.build()resources
- By default,
HttpClientparticipates in the global Reactor Netty resources held inreactor.netty.http.HttpResources, including event loop threads and a connection pool. - This is the recommended mode, since fixed, shared resources are preferred for event loop concurrency.
- In this mode global resources remain active until the process exits
- declare
ReactorResourceFactorybean to ensure netty global resources are shut down whenApplicationContextis closed - you can also choose not to participate in the global Reactor Netty resources. However, in this mode, the burden is on you to ensure that all Reactor Netty client and server instances use shared resources
timeours
- configure connection timeout
val httpClient = HttpClient.create()
.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 10000);
val webClient = WebClient.builder()
.clientConnector(ReactorClientHttpConnector(httpClient))
.build();- configure read/write timeout
val httpClient = HttpClient.create()
.doOnConnected { conn -> conn
.addHandlerLast(ReadTimeoutHandler(10))
.addHandlerLast(WriteTimeoutHandler(10))
}
// Create WebClient...- configure res timeout
val httpClient = HttpClient.create()
.responseTimeout(Duration.ofSeconds(2));
// Create WebClient...- configure res timeout for specific req
WebClient.create().get()
.uri("https://example.org/path")
.httpRequest { httpRequest: ClientHttpRequest ->
val reactorRequest = httpRequest.getNativeRequest<HttpClientRequest>()
reactorRequest.responseTimeout(Duration.ofSeconds(2))
}
.retrieve()
.bodyToMono(String::class.java)2.1.3 JDK HttpClient
- customize `HttpClient``
val httpClient = HttpClient.newBuilder()
.followRedirects(Redirect.NORMAL)
.connectTimeout(Duration.ofSeconds(20))
.build()
val connector = JdkClientHttpConnector(httpClient, DefaultDataBufferFactory())
val webClient = WebClient.builder().clientConnector(connector).build()2.2 retrieve()
- The
retrieve()method can be used to declare how to extract the response
