1. SQLAlchemy
1-1. SQLALCHEMY auto_increment
ext_id = db.Column(db.Integer, primary_key=True, autoincrement=False)SQLAlchemy는 테이블에 Integer 타입에 기본키로 설정된 애트리뷰트가 있다면 인스턴스 추가시 자동으로 이 숫자를 증가시켜준다. 이 설정을 끄고 싶다면 모델에서 애트리뷰트를 선언할 때 autoincrement=false 플래그를 주면 된다.
1.2 SQLALCHEMY Dynamic Relationship
-
Python Collections : 데이터의 모음을 저장하기 위한 컨테이너로 list, dict, set, tuple 등이 이에 해당한다.
-
relationship()은 두 모델 간 연결을 정의한다. 1:m, n:m 관계에서 객체가 로드되거나 변경될때 이 연결은 파이썬 collection으로 표현된다.
-
relationship()의 기본 설정은 collection의 모든 item을 로드하는 것이다.
-
기본적으로 Session은 현재 session 내에 존재하는 객체만 삭제할 수 있다. 또한 부모 인스턴스 삭제 시 session은 모든 자식 item을 로드하고 삭제되거나 외부키가 null로 설정된다.
위 이유로 인해 자식 item의 모음이 크기가 클 때 성능이 안좋기 때문에 SQLAlchemy는 동적 관계를 통해 로드와 삭제 시 모든 item 로드를 피한다.
class User(Base):
__tablename__ = 'user'
posts = relationship(Post, lazy="dynamic")접근 시 collection 대신 query 객체를 반환한다.
# filter Jack's blog posts
posts = jack.posts.filter(Post.headline=='this is a post')
# apply array slices
posts = jack.posts[5:20]append와 remove를 통해 제한된 쓰기 연산도 지원한다
oldpost = jack.posts.filter(Post.headline=='old post').one()
jack.posts.remove(oldpost)
jack.posts.append(Post('new post'))동적 로더는 collection에만 적용되기 때문에 m:1, 1:1 관계에서는 사용할 수 없다.
2. Jinja2
파이썬을 위한 디자이너 친화적인 템플렛 언어
- {% ... %} : Statements
- {{ ... }} : Expressions
- {# ... #} : Comments
- # ... : Line Statements
2-1. 템플릿 변수
템플릿 변수는 전달받은 컨택스트 사전으로 정의된다. 변수의 애트리뷰트는 .이나 []로 접근할 수 있다.
{{ foo.bar }}
{{ foo['bar'] }}
2-2. 필터
| 로 변수와 구분하고 괄호로 추가적인 인자를 가질 수 있다. 필터끼리는 체이닝도 가능하다.
{{ listx|join(', ') }}
{{ name|striptags|title }}
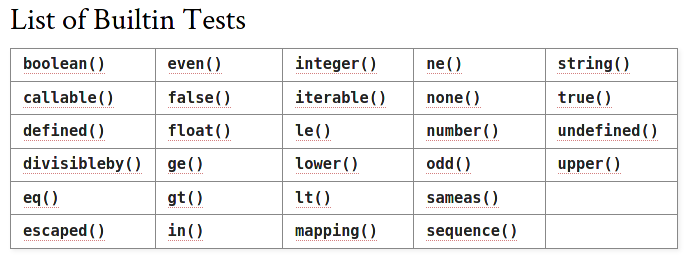
2-3. 테스트
변수나 표현식을 테스트할 수 있다.
{% if loop.index is divisibleby 3 %}
{% if loop.index is divisibleby(3) %}