2023 - 01 - 02
오늘은 파이썬과 다른 언어들 간의 차이점을 아주 간략하게 듣고 파이썬기본 문법을 박두진 강사님에게 강의를 들었다.
프로그래밍 개요
컴퓨터 : 계산수행 : CPU, RAM, SSD(HDD) : OS(물리적장치제어) : APP(물리적장치사용절차)
- 컴파일러언어 : 코드 실행하기 위해 컴파일 시간 소요 : 속도 빠름
- ex) C, C++ C#, 등등 컴파일러를 위해서 build가 필요하고 옛날 부족했던 하드웨어 성능을 알뜰하게 쓰기위해 메모리를 지정하기도 한다.
- 인터프리터언어(한줄 한줄 해석): 컴파일시간필요 X : 속도느림 : 문법쉬움 : Python 하지만 느린 python이 어떻게 성능이 필요로한 머신러닝 데이터분석에 최적화 되었나? 바로 numpy(C언어)로 속도를 올렸다고 한다.
jupyter notebook
cell 단위로 코드를 실행하는 환경(에디터:IDE)(파이참, VScode 등 많은 에디터가 있다.)
mode
-
명령모드(esc) : cell 수정
-
편집모드(enter) : cell 내용 수정
style
-
코드 : python 문법실행
-
텍스트 : markdown 문법실행 : 코드를 설명하거나 이미지를 추가할때
shortcut
-
shift + enter : 코드 실행
-
esc + a, b : 셀 생성
-
ctrl + space : 자동완성
Python
컴퓨터의 CPU, RAM, SSD(HDD)를 사용하는 방법, 문법 학습
- 변수선언
- RAM을 사용하는 문법 : 메모리에 저장공간을 만들어 데이터 저장
- 데이터타입
- RAM를 효율적으로 사용하는 문법
- int, float, str, bool, list, tuple, dict, set
- 연산자
- CPU를 사용하는 문법
- 산술, 할당, 비교, 논리, 멤버
코드를 효율적으로 작성할수 있도록 도와주는 문법
- 조건문
- 특정 조건에 따라서 다른 코드를 실행
- if, elif, else
- 반복문
- 특정 코드를 반복적으로 실행
- while, for, break, continue, range(), zip(), enumerate()
- 함수
- 반복되는 코드를 묶어서 코드 작성 및 실행
- def, args, params, docstring, scope, lambda
- 클래스
- 비슷한 기능의 변수, 함수를 묶어서 코드 작성 및 실행
- 객체지향을 구현한 문법
- class, self, init(), add(), str()
- 모듈, 패키지
-
모듈 : 변수, 함수, 클래스를 파일(.py)로 묶어서 코드 작성 및 실행
-
패키지 : 여러개의 모듈을 디렉토리로 묶어서 코드 작성 및 실행 : 버전정보
-
import, from, as
%% PEP8문서를 잘 읽고 숙지하자 현업,기업에서 활용한다. PEP8에 맞지않으면 git을 통한 협업도 이루지지 않을 수 있다.
- 예외처리
- 코드 에러에 대한 처리를 하는 문법
- try, except, finally, raise
- 입출력
- SSD(HDD)를 사용하는 문법 : RAM(data) > SSD(data), RAM(data) < SSD(data)
- pickle
변수선언
RAM 저장공간을 만들어서 데이터를 저장하는 문법
식별자 : 저장공간을 구별해주는 문자열
식별자규칙 - 문법 : 틀리면 에러발행 > 코드실행 X
- 대소문자, 숫자, _ 사용가능
- 가장 앞에 숫자 X : data_1(O), 1_data(X)
- 명령어(예약어) 사용 X : def, if, for(X) print(O)
- 컨벤션 : 틀려도 코드실행 O > 보기에 안좋음 : PEP8
- 변수 : jupyter_notebook : snake_case
- 상수 : 대문자로 작성 : JUPYTER_NOTEBOOL
%whos 명령어
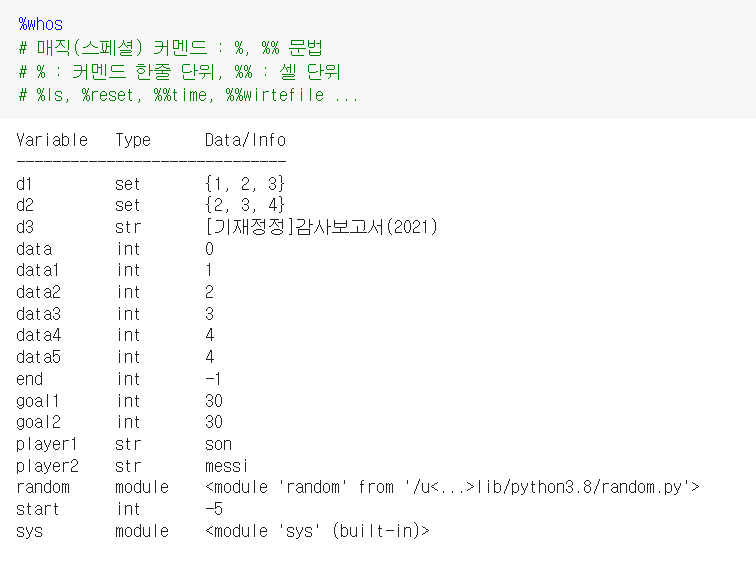
이런 식으로 알 수 있다.
변수 선언

데이터타입
RAM를 효율적으로 사용하는 문법
- 기본 데이터타입
- int, float, bool, str
- 컬렉션 데이터타입 : 식별자 1개, 데이터 n개
- list, tuple, dict, set
- CRUD : create, read, update, delete
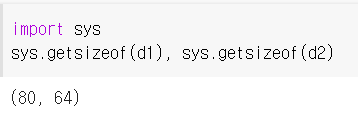
# type() : 식별자의 데이터 타입 출력
type(data1), type(data2), type(data3), type(data4)입력하세요 동적타이핑 : 변수선언시 데이터 타입 지정 X > 자동으로 데이터타입 지정
인터프리터 언어의 특징
컴퍼일러 언어 : int data1 = -10
데이터 선택 : masking
data[] : [idx], [key], [start:end], [start:end:stride]
print(data1)
data1[3], data1[2:4], data1[:2]
masking : -(음수) 사용
print(data1)
data1[-2], data1[-2:], data1[::-1]
tuple : () : 순서가 있고, 수정이 불가능
data2 = (1, 2, 3, 'A', 'B')
data2, type(data2)
- tuple 사용하는 이유 : 같은 데이터를 가지고 있으면 tuple이 list보다 저장공간을 적게 사용
d1, d2 = [1, 2, 3], (1, 2, 3)
type(d1), type(d2)
얕은복사, 깊은복사
data1 = [1, 2, 3]
data2 = data1 # 얕은복사 : 주소값 복사
data3 = data1.copy() # 깊은복사 : 데이터 복사
print(data1, data2, data3)
data1[1] = 4
print(data1, data2, data3)

- 얕은 복사와 깊은 복사의 차이
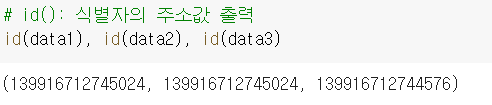
data1과 data2의 주소가 똑같아 data2의 데이터를 바꾸면 data1도 훼손된다. 그래서 깊은 복사를 통해 데이터만 복사해 다른 곳에 저장하는 방식으로 진행한다.
list, dict를 해보자
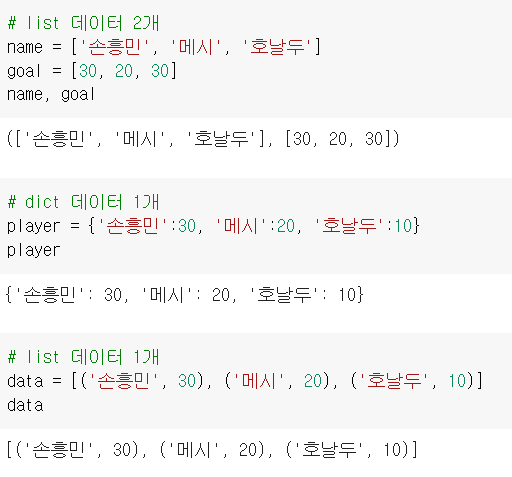
마지막 list 데이터 1개에서는 [list]와 (tuple)을 활용했다.
멀티라인 문자열
d6 = '''
jupyter
notebook
'''formatting

3가지 방식이 있고 공부 할때는 3번 쨰 방식이 편했는데 나중에 수정할 때는 2번 째가 좋을 것 같다.
