
오늘은 Spring에서 사용하는 마이바티스를 정리해보겠습니다.
마이바티스란?
- 객체지향 언어인 자바의 관계형 데이터베이스 프로그래밍을 좀더 쉽게 할 수 있게 도와주는
개발 프레임워크다. - 잘게 나눠져 있는 JDBC에 비해 여러 개의 메소드 호출을 더 적은 수의 메소드 호출로 처리할 수 있는 API를 제공한다.
- Mybatis는 객체지향 언어인 자바의 관계형 데이터베이스 프로그래밍을 쉽게 할 수 있도록 해주는, JDBC(=자바에서 제공하는 데이터베이스 프로그래밍 API) 를 개선해서 나온 프레임워크이다.
마이바티스 작동 방식
코어 프레임워크
JDBC를 단순화하고, SQL을 XML에 정의하게 해준다. (마이바티스의 본질)
일반적으로 ‘마이바티스’라고 하면, 이 ‘코어 프레임워크’를 말한다.마이바티스 제너레이터
자바로 데이터베이스 프로그래밍을 하면, 테이블 별로 SQL을 만들거나,
조회 결과를 담는 자바 모델 클래스 등을 만들어야 해서 시간이 많이 소요된다.
마이바티스 제너레이터는 테이블별로 SQL과 모델 클래스를 자동으로 만들어준다.스키마 마이그레이션
데이터베이스가 변경될 때, 그에 맞게 마이바티스 관련 파일을 변경해주는 도구이다.
운영중인 시스템의 데이터베이스를 변경하는 경우는 거의 없어서, 사용할 기회가 적다.마이바티스를 사용할 때의 장점
- 데이터베이스 프로그래밍을 하는 데 기존 JDBC API를 사용할 때의 불편함을 없애준다.
- 마이바티스 내부에서는 JDBC API를 사용하고 개발자가 직접 JDBC를 사용할 때의 중복 작업을
대부분 없애준다. - SQL을 별도의 XML이나 애노테이션으로 정의하기 때문에 SQL을 관리하기 편하다.
- SQL을 XML에 선언한 형태를 매핑 구문이라고 부른다.
마이바티스의 특징
- JDBC 프레임워크다.
- 개발자는 SQL을 작성하고, 마이바티스는 JDBC를 사용해서 실행한다.
- JDBC를 사용할 때의 try/catch 구문을 사용할 필요가 없다.
- SQL매퍼다.(ORM이 아니다.) ORM 프레임워크는 데이터베이스 객체를 자바 객체로 매핑함으로써 객체 간의 관계를 바탕으로 SQL을 자동으로 생성해주지만, 마이바티스는 SQL을 명시해줘야 한다. 여기서 ORM프레임 워크는 SQL을 직접 작성하지 않아도 적절한 데이터를 넣어주는 프레임 워크이다.
- 객체 프로퍼티를 Prepared 구문의 파라미터로 자동으로 매핑한다.
- 조회 결과를 객체로 자동으로 매핑한다.
- N+1 쿼리의 문제를 제거하게 지원한다.
- 트랜잭션을 관리한다.
- 스프링 같은 외부 트랜잭션 관리자를 사용할 수 도 있다.
- 스프링 연동 모듈을 제공해서 스프링과 연동할 수 도 있다.
- 가장 큰 특징으로는 JDBC에서 사용한 SQL을 별도 XML에 분리해서 관리한다.
마이바티스의 구조
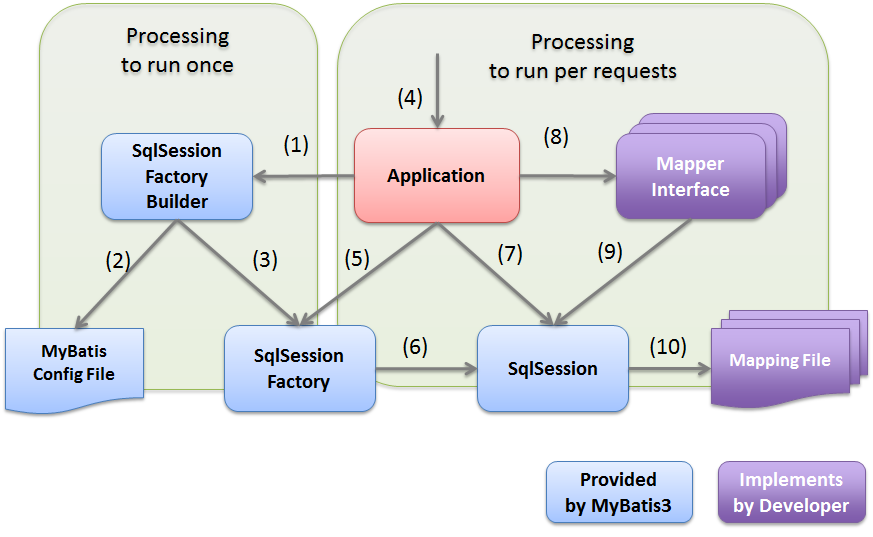
- 설정 파일(mybatis-config.xml) : 데이터베이스 설정과 트랜잭션 등 마이바티스가 동작하는 규칙을 정의한다.
- 매퍼 : SQL을 XML에 정의한 매퍼 XML 파일(1개 이상)과 SQL을 인터페이스의 메소드마다 애노테이션으로 정의한 매퍼 인터페이스(1개 이상)를 의미한다.
- 결과 매핑과 매핑구문 : 조회 결과를 자바 객체에 설정하는 규칙을 나타내는 결과 매핑과
SQL을 XML에 정의한 매핑 구문을 말한다. 매핑 구문을 정의하는 방법은 애노테이션과 XML 방식
두 가지가 있다. - 지원하는 파라미터 타입 : MAP 객체, 자바 모델 클래스, 원시 타입(int, String 등)이 있다.
마이바티스 파일 설명
- mybatis-3.2.1.jar : 마이바티스 API를 가진 jar파일이다. 우리가 사용할 땐, 이 파일만 있으면 된다.
- mybatis-3.2.1-javadoc.jar : 마이바티스의 API를 설명해주는 javadoc이다. (설명서)
- mybatis-3.2.1.pdf : 마이바티스 사용자 가이드 문서이다.
- mybatis-3.2.1-source.jar : 마이바티스는 오픈소스라 소스를 공개하고 있다. (소스코드)
- lib 디렉토리 : 라이브러리. 다른 프레임워크(스프링 등)와 혼용 시 필요한 파일이다.
마이바티스를 사용하려면..
- getSqlSessionFactory 메소드를 사용해 마이바티스 객체를 생성하고 API를 호출하면 된다.
- 설정 정보를 로드하는 과정에서 다음과 같은 세 개의 클래스를 사용한다.
- org.apache.ibatis.io.Resources
- org.apache.ibatis.session.SqlSessionFactoryBuilder
- opg.apache.ibatis.session.SqlSessionFactory
- 마이바티스 설정 파일의 이름은 mybatis-config.xml이며 클래스패스를 기준으로 가장 상위에 존재한다. 설정 파일은 클래스 패스를 기준으로 파일명을 적어주면 된다.
- JDBC에서는 데이터베이스 연결 객체를 가져오기 위해 데이터베이스 URL과 계정 정보를 사용해 자바 API로 연결 객체를 생성하였는데, 마이바티스에서는 마이바티스 설정 파일을 생성하고,
마이바티스의 SqlSessionFactory 객체를 생성한다.
마이바티스 프로세스 구조
마이바티스 활용
마이바티스 객체 생성하는 방법
- 마이바티스 객체 생성
-
설정 정보를 가진 객체 생성 :
1) String resource = “mybatis-config.xml”; 구문으로 설정파일을 생성하고
2) InputStream inputStream; 구문으로 호출한다.
-
SqlSessionFactory 생성 :
1) SqlSessionFactoryBuilder를 먼저 생성하고
2) SqlSessionFactoryBuilder의 build메소드를 호출해 SqlSessionFactory를 생성한다.
→ SqlSessionFactory의 객체는 일반적으로 ‘하나만’ 생성한다.
⇒ SqlSessionFactory 객체생성은 JDBC에서의 ‘데이버테이스 연결 객체 생성’과 유사하다.
⇒ SqlSessionFactory 객체는 마이바티스 API를 사용하는 기본 객체이다.
⇒ SqlSessionFactory 객체가 마이바티스의 전반적인 정보를 제어하기 때문에 하나만
-
CRUD(create, read, update, delete)
- CRUD를 수행하기 위한 사전 준비가 필요한데,
- 데이터의 구조를 먼저 파악해야 한다.
- 마이바티스 파라미터 표기법
- 추출한 SQL을 XML에 명시하는 경우 값의 설정은 #{ } 형태의 문법을 제공한다.
- 방법은 파라미터 이름을 그대로 적어주면 된다. 자바빈일 경우엔 변수명 또는
getter/setter 메소드에서 get/set을 뺀 나머지 문자를 소문자로 시작해서 적어준다. - 자바빈에 getter메소드가 있으면 getter 메소드를 사용해 값을 가져오지만, getter 메소드가
없을 경우에는 자바의 리플렉션(JVM의 기능)을 사용해 값을 가져온다.
Map 객체일 때는 key 값을 적어주면 설정해준다. - 또한, 파라미터의 값이 한 개인 원시타입의 경우 #{ } 안에 아무값이나 적어줘도 알아서 설정해준다. 일부 타입은 자동으로 잡아주지 않고 명시적으로 지정해줘야 한다.
-
${ something }
JDBC의 PreparedStatement 의 ? 를 사용하지 않고 문자열 치환으로 처리하기 위한 표기법이다. #{ } 과 달리 변환과정이 생략되지만, SQL 인젝션 공격에 노출될 위험이 있다.
### 데이터 조회 방식(JDBC와 마이바티스의 차이점) -
JDBC방식
- 데이터베이스 연결 객체 생성(Connection con)
- SQL을 준비하고 PreparedStatement 객체 생성
- PreparedStatement에 파라미터 설정 후 실행
- 조회 결과를 ResultSet 객체에 세팅하고
- 자원 해제(마지막으로 작성된 순서대로 close() 처리한다.
-
마이바티스 방식
-
SQL을 별도의 XML에 작성한다.(자바코드가 아닌, 별도의 XML파일이나 어노테이션)
- XML과 DOCTYPE 선언
- 매퍼 네임스페이스(=매핑 구문들의 그룹) 설정
- 매핑 구문 설정
(id:key값, parameterType:매개변수 타입,resultType:반환값 타입)
-
매핑 구문을 사용하기 위한 마이바티스 코드 생성
- 마이바티스 객체 → 구문을 생성&호출할 자바 클래스 생성
- 자바 클래스에 마이바티스 객체 생성
(SqlSessionFactoryBuilder → SqlSessionFactory → SqlSession 생성)
-
매핑된 구문을 사용해 데이터 CRUD (마이바티스 API를 사용)
→ 끝났으면 데이터베이스 자원 해제(SqlSession 객체 close)
-
매퍼(Mapper)
- 매퍼를 사용하는 방식에는 크게 3가지가 있다.
- XML만 사용하는 방식
resultMap에 컬럼을 설정하고, select 구문에 id(키 값)에 붙은 쿼리를 불러와 실행하는 방식이다.
구문을 ‘정의’하는 장점을 가지고 있다. - 인터페이스만 사용하는 방식
추상 메소드에 어노테이션으로 쿼리를 입력해놓고, getMapper로 쿼리를 불러와 실행하는 방식이다. 구문을 ‘호출’하는 장점을 가지고 있다. - XML과 인터페이스의 장점을 섞은 remix방식
XML 매핑 구문은 그대로 작성하고, 이에 대응하는 인터페이스 파일을 생성, 메소드를 선언한다. 하지만 어노테이션은 작성하지 않는다. 이 때 주의해야 할 점은 XML매핑 구문을 어노테이션 매핑 구문으로 변경하는 규칙을 맞춰야 한다. XML매핑 구문의 네임스페이스와 인터페이스의 이름,
패키지가 동일하고, 아이디가 같고, 반환 타입과 파라미터도 동일해야 한다.
이것들의 설정을 마치면 마이바티스가 자동으로 연결을 해준다.
트랜잭션 관리
- 마이바티스 사용 시 중요한 객체는 SqlSessionFactory 객체이다.
- 각각의 세부 작업은 SqlSessionFactory에서 만들어지는 SqlSession이 관리한다.
- SqlSession 객체 생성 시점에 트랜잭션에 관한 속성을 설정하기 때문에,
트랜잭션을 처리하는 방법을 보기 전에 SqlSessionFactory와 SqlSession을 먼저 알아볼 필요가 있다.
- SqlSessionFactory로 SqlSession 생성
- SqlSessionFacotry가 가진 메소드가 많지만, 대부분 openSession 메소드만 호출해 처리한다.
- openSession 메소드는 다양하게 오버로딩 되어있어서 사용이 편리하다.
- openSession 메소드를 사용하여 SqlSession 생성 시 다음과 같은 특성을 가진다.
-
객체를 생성할 때마다 트랜잭션을 시작한다.
-
마이바티스 설정 파일의 데이터 소스를 사용한다.
-
설정 값을 사용해 트랜잭션에 관련한 설정을 한다.
-
PreparedStatement는 재사용되지 않고 배치 형태로 처리하지 않는다.
→ 다양하게 오버로딩 되어있는 openSession 메소드들은 위의 특성을 변경하고 싶을 때,
매개변수를 넣어 사용한다.
- 트랜잭션 처리
-
데이터베이스에서 데이터를 조작하는 각종 작업 시,
특정 시점에 변경사항을 물리적으로 완전히 적용 혹은 취소하는 것이다.
보통 if구문으로 true일 시 commit // flase일 시rollback 사용(미리 정의)
-
마이바티스 사용 시, ‘트랜잭션 작업 시작’을 명시적으로 시작하는 메소드는 따로 없고,
openSession 메소드 호출로 SqlSession 생성 시에 시작될 뿐이다.
commit 이나 rollback 을 말하는 게 아님. 해당 작업은 해당 메소드를 호출해서 가능.
⇒ 스프링 미사용 시, SqlSession 클래스가 제공하는 commit과 rollback을 사용하고,
스프링 사용 시, 트랜잭션 제어는 마이바티스가 수행하지 않고 스프링에 위임된다.
→ 데이터 변동을 확인하기 위해, 대개 API가 반환한 값을 확인(0보다 크면 커밋, 0이나 음수면 롤백)한다.
-
조회 결과를 자바 객체에 세팅(= 결과 매핑)
- DB 조회 시 결과 값은 객체에 담아서 사용하게 된다.
- DB에서 가져온 값을 자바 객체에 설정하기 위해 마이바티스는 결과 매핑이라는 기법을 제공.
- 결과 매핑을 처리하기 위해서 XML엘리먼트나 어노테이션을 사용할 수 있다.
- 마이바티스의 결과 매핑은 컬럼명과 자바 모델 클래스의 필드명, 혹은 setter 메소드가 설정하고자 하는 값과 일치하면 자동으로 값을 설정해준다.
- 만약, 일치하지 않으면 마이바티스의 XML엘리먼트를 이용해 직접 값을 설정해주어야 한다.
-
ResultMap : 결과 매핑을 사용하기 위한 가장 상위 엘리먼트.
결과 매핑을 구분하기 위한 id속성과, 매핑 대상 클래스를 정의하는 type속성을 사용 -
id : 기본 키에 해당하는 값 설정
-
result : 기본 키가 아닌 나머지 칼럼에 대한 매핑
-
constructor : setter메소드나 리플렉션을 통하지 않고, 생성자를 통해 설정하는 경우 사용
-
association : 1:1 관계 처리 시
-
collection : 1:N(1:다수) 관계 처리 시
-
discriminator : 매핑 과정에서 조건을 지정해 값 설정 시
-
XML 엘리먼트
마이바티스(전역, 기본)에서 가장 많이 사용하는 XML 엘리먼트들
- properties : 설정 내부에서 사용하는 각종 설정값을 외부 파일에서 추출함
- setting : 마이바티스 전반에 영향을 끼치는 설정
- typeAliases : ‘파라미터 타입’이나 ‘결과 매핑 타입’에 별칭을 지정
- environments : 데이터베이스 연결 정보와 트랜잭션 관리자를 설정
- mappers : 매핑 구문을 갖는 매퍼 위치를 설정
상황에 따라 유용하게 사용하는 엘리먼트들
- typeHandlers : 칼럼 타입과 자바 타입별로 처리를 담당하는 핸들러를 지정
- objectFactory : 결과 데이터를 만들 때, 처리과정을 담당하는 객체 팩토리(Object Factory) 들을 정의
- plugins : 마이바티스가 처리하는 시점 별로 부가적인 작업을 처리하는 플러그인을 정의
매퍼 XML 엘리먼트(chap05-mapper-elements)
매핑 시 사용할 수 있는 XML 엘리먼트
- cache-ref, cache 엘리먼트
: 캐시를 설정하는 엘리먼트이다. 캐시는 매핑구문과 파라미터에 따라 사용 여부를 결정한다.
사용자가 작성하는 메소드 단위가 아닌, 마이바티스에서 제공하는 SqlSession 객체의 API호출 단위로 작동한다. - cache : 현재 네임스페이스에 대한 캐시 설정
- cache-ref : 다른 네임스페이스에 대한 캐시 설정 참조 시 사용
- resultMap 엘리먼트
- 데이터베이스 결과 데이터를 객체에 로드하는 방법을 정의하는 엘리먼트이다.
- 마이바티스에서 가장 중요하고 강력한 엘리먼트이다.
- ResultMap에서 데이터를 가져올 때, JDBC 코드를 대부분 줄여주게 된다.
- resultMap으로 설정 가능한 4가지
- id : 매핑 구문에서 결과 매핑을 사용할 때 구분하기 위한 아이디값.
- type : 결과 매핑을 적용하는 대상 객체 타입. 결과 데이터를 갖는 자바 타입을 지정.
- extends : 자바의 상속처럼 기존에 정의된 결과 매핑을 상속받아, 추가적인 매핑 정보 확장 시 사용한다.
- autoMapping : 결과 매핑을 자동으로 할 것인지를 결정한다.
-
resultMap 엘리먼트에 딸려있는, 하위 엘리먼트
-
id : primary key 컬럼을 매핑하기 위한 태그. (성능 향상)
-
result : pk가 아닌 컬럼을 매핑하기 위한 태그.
-
constructor : 인스턴스화 되는 클래스의 생성자에 결과를 삽입하기 위해 사용.
→ 하위 엘리먼트로 , 엘리먼트가 있다. 각각 ‘키’ 와 ‘값’ 역할.
-
association : 복잡한 타입의 연관관계로 1:1 포함관계인 경우 사용한다.
-
collection : 복잡한 타입의 연관관계로 1:N 포함관계인 경우 사용한다.
-
discriminator
- sql 엘리먼트
: 매핑 구문에서 공통적으로 사용할 수 있는, SQL문자열 일부를 정의,재정의하기 위해 사용된다.
별도로 빼둔 SQL의 일부에 엘리먼트를 변수처럼 사용한다.<select id=”selectCommentByPrimaryKey” parameterType=”long” resultType=”Comment”> SELECT <include refid=”columns”> FROM COMMENT WHERE comment_no = # { commentNo } ⇒ 위와 같은 구문이 있을 때, ‘<include refid’= “columns”> 부분 같은 경우를 말함. → 정적인 내용 뿐만 아니라 동적 SQL도 넣을 수 있다.
매퍼 인터페이스
-
마이바티스는 매퍼 인터페이스를 사용해 매핑구문과 결과 매핑 등을 정의할 수 있다.
-
매퍼 인터페이스의 ‘패키지명 인터페이스명’은 매퍼의 네임스페이스가 되고,
매퍼 인터페이스에 선언한 메소드는 매핑 구문 id가 된다.
-
매핑 구문에서 사용하는 SQL은 어노테이션을 사용해 정의한다.
-
매퍼 인터페이스가 사용하는 XML 엘리먼트
- 캐시 엘리먼트 : CacheNamespace, CacheNamespaceRef
- 매핑 구문 엘리먼트 :
- insert, update, delete : 각각 입력, 수정 , 삭제를 위해 사용된다.
- selectkey 엘리먼트 : 자동 생성 키의 값을 가져오기 위해 사용한다.
- select 엘리먼트 :
- 결과 매핑 엘리먼트 : Arg, Results, Result, Case, MapKey …
-
간단한 CRUD 를 처리하기 위한 매퍼 인터페이스
기존에 매퍼 XML에서 매핑 구문의 엘리먼트마다 SQL을 정의하던 것을
→ 어노테이션의 ‘파라미터’로 정의하면, 패키지명 인터페이스명을 네임스페이스로 사용하고
메소드명은 매핑 구문의 id, 메소드의 파라미터는 매핑 구문의 ‘파라미터 타입’이 된다.
⇒ 매퍼 XML을 구성하는 각 엘리먼트가 매퍼 인터페이스에서 무엇으로 바뀌는지
잘 숙지하면 매퍼 인터페이스 사용이 어렵지는 않을 것이다.(라고 책에 써있네요)
-
XML 결과 매핑과, 어노테이션 결과 매핑 사이에 몇가지 공통점이 있다.
-
XML 결과 매핑이 resultMap엘리먼트 + 하위에 id, result 엘리먼트를 쓰는 것처럼,
어노테이션 결과 매핑도 @Results 어노테이션과 + 하위에 @Result을 사용한다.
-
XML 결과 매핑의 id와 result 엘리먼트의 속성들은, 어노테이션 결과 매핑의 @Result
어노테이션에서도 동일한 속성을 가진다.
-
정리하면 :
- @Results 어노테이션은 resultMap 엘리먼트를 대체 가능하다.
- @Result 어노테이션은 result 엘리먼트를 대체 가능하다.
- id 속성이 true인 @Result 어노테이션은 id 엘리먼트를 대체 가능하다.
- id 속성이 false 인 @Result 어노테이션은 result 엘리먼트를 대체 가능하다.
- @Result 어노테이션은 id와 result 엘리먼트의 속성을 대부분 그대로 가진다.
-
-
그러나, XML 결과 매핑과 어노테이션 결과 매핑 사이에 차이점도 있다. (중요)
-
XML 결과 매핑의 타입은 type 속성을 사용해 정의했지만,
어노테이션 결과 매핑은 메소드 반환 타입을 사용한다.
-
어노테이션 결과 매핑은 다른 결과 매핑에서 재사용할 수 없다.
→ 따라서 XML 결과 매핑에서 제공하는 id 속성도 제공하지 않는다.
-
동적 SQL
‘조건’에 의해 생성되는 ‘분기’에 대한 처리를 하기 위한 SQL 구조가 ‘동적 SQL’이다.
예를 들어, SELECT문으로 A라는 테이블에 대한 조회를 하고 싶은데,
- ‘성별’ 을 기준으로 조회
- ‘나이’ 를 기준으로 조회
- ‘주소’ 를 기준으로 조회
등등 비슷한 구문이지만 조건절이나 조회할 컬럼 등 일부분만 다른 경우,
각각의 경우의 수에 대한 모든 쿼리문을 일일이 따로 작성해야 할까?
이럴 때, 쿼리문 자체에 조건문을 달아 경우에 맞게 ‘알아서 변동되는’ SQL이 동적 SQL이다.
단점으로는, 자바 코드를 사용해 동적SQL을 만드는 것 자체는 쉽지만, 분기처리가 많아질수록
가독성이 떨어지고, 오타 발생 확률이 높아져 유지보수가 어려워진다는 점이 있다.
-
마이바티스에서의 동적 SQL 사용법 : 3가지
- XML에서 SQL을 위한 엘리먼트를 사용해 생성
- 마이바티스의 구문 빌더 API를 사용해 생성
- JDBC를 사용할 때처럼 자바 코드로 SQL을 만드는 문자열 처리
-
XML에서 SQL을 위한 엘리먼트를 사용 시
-
마이바티스의 구문 빌더 API 사용 시
-
JDBC를 사용할 때처럼 자바 코드로 SQL을 만드는 문자열 처리
-
마이바티스를 사용하는 데이터 액세스 계층
‘조건’에 의해 생성되는 ‘분기’에 대한 처리를 하기 위한 SQL 구조가 ‘동적 SQL’이다.
예를 들어, SELECT문으로 A라는 테이블에 대한 조회를 하고 싶은데,
- ‘성별’ 을 기준으로 조회
- ‘나이’ 를 기준으로 조회
- ‘주소’ 를 기준으로 조회
등등 비슷한 구문이지만 조건절이나 조회할 컬럼 등 일부분만 다른 경우,
각각의 경우의 수에 대한 모든 쿼리문을 일일이 따로 작성해야 할까?
이럴 때, 쿼리문 자체에 조건문을 달아 경우에 맞게 ‘알아서 변동되는’ SQL이 동적 SQL이다.
단점으로는, 자바 코드를 사용해 동적SQL을 만드는 것 자체는 쉽지만, 분기처리가 많아질수록
가독성이 떨어지고, 오타 발생 확률이 높아져 유지보수가 어려워진다는 점이 있다.
-
마이바티스에서의 동적 SQL 사용법 : 3가지
- XML에서 SQL을 위한 엘리먼트를 사용해 생성
- 마이바티스의 구문 빌더 API를 사용해 생성
- JDBC를 사용할 때처럼 자바 코드로 SQL을 만드는 문자열 처리
-
마이바티스를 사용하는 데이터 액세스 계층
