RTL simulation
DPI-C & UVM
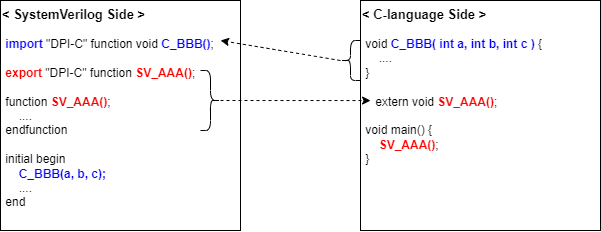
- DPI is an interface between SystemVerilog and a foreign programming language.
- Two layers, both sides of DPI are fully isolated
- the SystemVerilog layer
- a foreign language layer
- For now, SystemVerilog defines a foreign language layer only for the C programming language
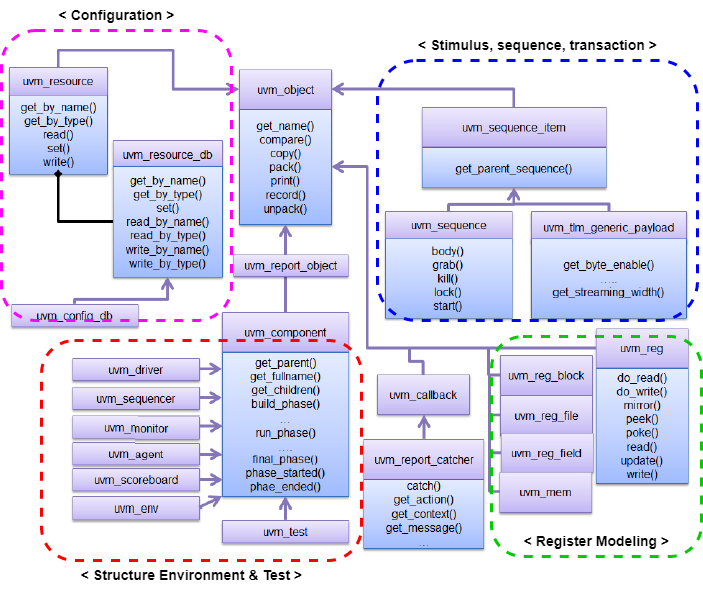
UVM
Universial Verification Methodology
https://wikidocs.net/170314!
https://systemc.org/
SystemC™ addresses the need for a system design and verification language that spans hardware and software. It is a language built in standard C++ by extending the language with the use of class libraries. The language is particularly suited to model system's partitioning, to evaluate and verify the assignment of blocks to either hardware or software implementations, and to architect and measure the interactions between and among functional blocks.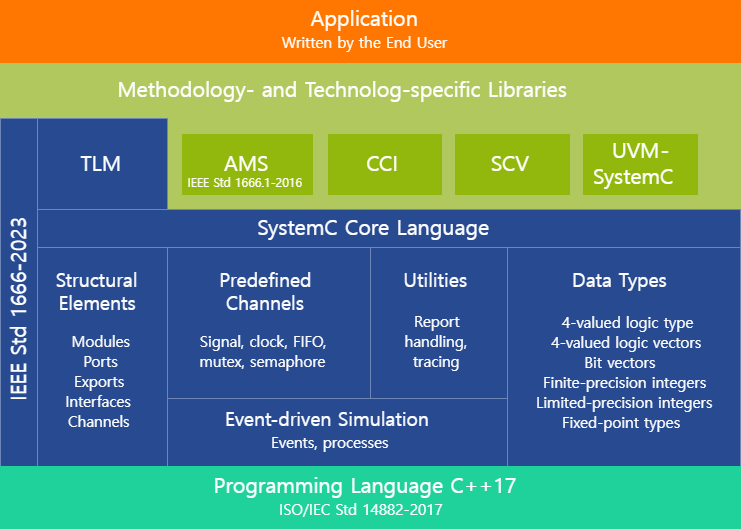
An SoC is literally a system on a chip, consisting of both silicon and embedded software. Its design involves complex algorithm and architecture development and analysis similar to that performed in system design – a trade-off process that determines critical metrics, such as SOC performance, functionality, and power consumption.
Consequently, design tools must deliver orders-of-magnitude improvement in productivity at both architectural and implementation (RT and physical) levels. Moreover, tools must support a methodology that enables the early development of embedded application and system software, long before the availability of the RTL design or silicon prototype. Failure to achieve the requisite improvements in design productivity would result in missed market windows, and exploding design costs.
SystemC is a single, unified design and verification language that expresses architectural and other system-level attributes in the form of open-source C++ classes. It enables design and verification at the system level, independent of any detailed hardware and software implementation, as well as enabling co-verification with RTL design. This higher level of abstraction enables considerably faster, more productive architectural trade-off analysis, design, and redesign than is possible at the more detailed RT level. Furthermore, verification of system architecture and other system-level attributes is orders of magnitude faster than that at the pin-accurate, timing-accurate RT level.
The SystemC community consists of a large and growing number of system design companies, semiconductor companies, intellectual property providers, and EDA tool vendors who have joined together to support and promote the standard.
QEMU
https://www.qemu.org/docs/master/
QEMU is a generic and open source machine emulator and virtualizer.
QEMU can be used in several different ways. The most common is for System Emulation, where it provides a virtual model of an entire machine (CPU, memory and emulated devices) to run a guest OS. In this mode the CPU may be fully emulated, or it may work with a hypervisor such as KVM, Xen or Hypervisor.Framework to allow the guest to run directly on the host CPU.
The second supported way to use QEMU is User Mode Emulation, where QEMU can launch processes compiled for one CPU on another CPU. In this mode the CPU is always emulated.
QEMU also provides a number of standalone command line utilities, such as the qemu-img disk image utility that allows you to create, convert and modify disk images.
When operating in user mode, only the user-level code is translated. In system mode, the entire system, including kernel-level code is translated.
-
Execute
QEMU is not an RTL‑accurate simulator.
It is a full‑system emulator that translates a guest CPU's binary code into host instructions at run‑time, drives that code from a software‑defined "soft‑MMU," and connects the resulting virtual machine to an extensive catalogue of device models. This approach gives near‑native speed on a developer laptop while remaining completely architecture‑agnostic. -
Dynamic binary translation with TCG Stage
Because translation is demand‑driven, hot paths stay cached while cold code never incurs compilation cost. With this "Tiny Code Generator" (TCG) design, a new host CPU needs only a ~2 kLOC back‑end, while each new guest ISA needs a front‑end translator. This split is why QEMU today supports more than 20 architectures without exploding in size.
| Stage | What happens | Key data-structures / APIs |
|---|---|---|
| Front-end decode | When the guest PC points at code QEMU has never seen, the "translator" for that ISA decodes a translation block (TB)—roughly one basic block of guest instructions. | DisasContext, per-ISA translate functions |
| TCG IR build | Each guest instruction is lowered into a small, RISC-like TCG op sequence. The IR is architecture-neutral, which is why the translator back-ends are small and easy to port. | tcg/optimize.c, TCGOp, TCGTemp |
| Local optimisation | Peephole passes (constant folding, dead-code elimination, simple CSE) trim the IR. | tcg/optimize.c |
| Back-end code-gen | The IR is emitted as host machine code (x86-64 in your scenario). The generated code plus a short prologue/epilogue is copied into a global code cache. | tcg/target/x86/tcg-target.c.inc |
| Execution & chaining | The host CPU jumps into the cache. At TB exit, QEMU can direct-chain to the next TB to remove dispatcher overhead. | cpu_exec(), TB links |
-
The Soft‑MMU and memory‑mapped I/O
3.1 Address translation
Every guest memory access issued by generated code is wrapped in a helper that goes through QEMU's soft‑MMU TLB. The TLB entries are patched directly into the host code, so the fast path is just a couple of host instructions. A miss traps back into C, performs page‑table walks, and repatches the TB‑‑exactly mirroring real hardware, but in software.3.2 MMIO hooks
If the physical address lies inside a MemoryRegion flagged as device, the load/store is re‑routed to an emulated callback (, ). Device authors therefore implement register‑level side‑effects in standard C while the common memory API handles endianness, burst limitations, coalesced writes, and KVM ioeventfd plumbing.
-
Device modelling architecture
- QOM (QEMU Object Model). All devices, buses and even CPUs are QOM objects, enabling run‑time type checking, property wiring and hot‑plug.
- Bus hierarchy. Templates exist for PCI, USB, VirtIO, SPI, I²C, AXI, etc. A MemoryRegion can be placed behind any bus master to create bridges, address windows or DMA engines.
- Firmware integration. ACPI tables or Flattened Device Tree blobs are generated automatically so that unmodified kernels "see" the devices exactly as hardware would present them. Compared with cycle‑accurate simulators, the timing model is intentionally loosely timed: the goal is functional correctness plus "good enough" latency to boot real OSes and run benchmarks.
-
Acceleration paths: pure TCG vs. KVM/HVF/WHPX
Pure TCG – portable, single‑binary, no privileges required; speed is 10‑30 × slower than hardware but fast enough for firmware bring‑up, CI and fuzzing.
KVM/Hypervisor.framework/WHPX – when the host supports hardware virtualisation for the same ISA, QEMU can skip TCG for most user code and let the CPU run it natively. Device emulation, soft‑MMU for MMIO, and snapshot logic remain identical, preserving the portable machine description.
Switching between these modes is often just on the command line.-accel kvm:tcg
-
How it differs from RTL simulation Aspect
| Aspect | QEMU (TCG) | RTL simulator (e.g., Verilator, Synopsys VCS) |
|---|---|---|
| Granularity | Instruction / basic-block; ignores clock phases | Signal-accurate, delta-cycle |
| Performance | Near native when JIT cached | <1 kHz for SoC-scale designs |
| Fidelity | Architectural state + programmer's view of devices | Flip-flop accurate; includes metastability, CDC |
| Use-cases | OS bring-up, driver dev, CI, fuzzing, co-simulation | SoC/Micro-architecture validation, timing closure |
| Build artefacts | Plain C and host assembly | Elaborated netlists, SDF, waveform dumps |
Because QEMU does not model wire‑level timing, it cannot expose hazards like hold‑time violations or DDR read levelling errors. Conversely, RTL cannot realistically boot Linux in seconds on a laptop. Many silicon teams therefore run both‑‑QEMU for software velocity, RTL for hardware sign‑off.
- Typical workflow for an Arm‑on‑x86 project
# Build
$ ../configure --target-list=aarch64-softmmu --enable-debug
$ make -j$(nproc)
# Run U‑Boot and Linux kernel under TCG
$ qemu-system-aarch64 \
-machine virt,secure=on,gic-version=3 \
-cpu cortex-a55 \
-m 2G \
-bios u-boot.elf \
-kernel Image \
-append "earlycon console=ttyAMA0" \
-device loader,file=rootfs.cpio,addr=0x84000000
# Attach gdb to inspect MMIO registers
(gdb) target remote :1234Device events () will fire in the host process every time the guest kernel touches an emulated register, letting you printf‑trace firmware interactions without hardware.readfn/writefn
Virtualization?
https://www.slideshare.net/GauravSuri1/virtualization-and-hypervisors
