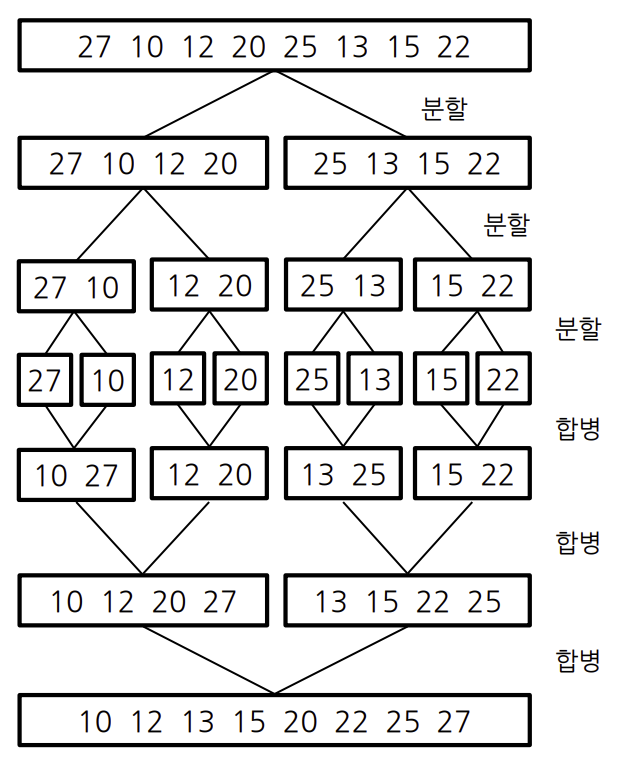
- 정렬되지 않은 영역을 쪼개서 각각의 영역을 정렬하고 이를 합치며 정렬
- 리스트를 두 개의 균등한 크기로 분할하고 분할된 부분리스트를 정렬
- 정렬된 두 개의 부분 리스트를 합하여 전체 리스트를 정렬
- Divide & Conquer
- 단점 : 분할한 자료를 저장할 별도의 저장 공간 필요
public static void mergeSort(int[] numbers, int left, int right) {
if (left < right) {
int mid = (left + right) / 2;
mergeSort(numbers, left, mid);
mergeSort(numbers, mid + 1, right);
merge(numbers, left, mid, right);
}
}
private static void merge(int[] numbers, int left, int mid, int right) {
int[] temp = new int[right - left + 1];
int i = left;
int j = mid + 1;
int k = 0;
while(i <= mid && j <= right) {
if (numbers[i] <= numbers[j]) {
temp[k++] = numbers[i++];
} else {
temp[k++] = numbers[j++];
}
}
while (i <= mid) {
temp[k++] = numbers[i++];
}
while (j <= right) {
temp[k++] = numbers[j++];
}
for(k = 0; k < temp.length; k++){
numbers[left + k] = temp[k];
}
}
- 비교횟수 :
- 크기 n인 리스트를 균등 분배 → log n
- 각 합병에서 리스트의 모든 레코드 n개 비교 → n
- n log n
- 이동횟수 :
- 레코드의 이동이 각 패스에서 2n번 발생
- 전체 레코드의 이동은 2n*log(n)
- 레코드 크기 크면 매우 큰 시간적 낭비
- 레코드를 연결리스트로 구성하여 합병 정렬하면
- 링크 인덱스만 변경 → 데이터 이동은 무시할 수 있을 정도로 작아짐
- 크기가 큰 레코드를 정렬하면 효율적
- 최적/평균/최악 → O(n log n) 의 복잡도
- 데이터의 초기 분산 순서에 영향을 덜 받음
- 합병을 일찍 시작하면 성능이 향상 (재귀 호출의 빈도 감소)
성능 향상
재귀 호출 감소
- 크기 1까지 재귀호출하지 말고 소수의 크기(10 이내)일때에는 삽입정렬
- sorted를 list로 복사하는 대신 두 개의 배열을 번갈아 사용
- O(n log n)
반복 합병 정렬
- D&C이 아니라 2개-4개-8개를 바로 합병하는 방식
