
개요
그동안 여러 프로젝트들을 하며 JPA와 Spring Data JPA를 사용해왔지만, 지식의 빈공간이 많이 있는 채로 프로젝트만 진행하다 보니, 다소 생각지 못한 에러들을 접하기도 하고, 실력이 더 올라가지 않을 것 같다는 생각이 들었습니다.
이러한 생각에 다시 JPA의 내부 동작과 이론에도 초점을 맞춰 공부를 진행하고 있었는데, 궁금한 점이 생겨 찾아보게 되었고, 그에 대한 포스팅을 진행하려 합니다.
JPA를 통해서 우리는 SQL중심적인 개발이 아닌 객체 중심의 개발을 할 수 있고, 이것이 JPA의 사상과도 밀접하게 관련이 있습니다. 이러한 일이 가능하게 해주는 데에는 JPA의 영속성 컨텍스트라는 것이 있습니다.
영속성 컨텍스트를 통해 우리는 1차 캐시를 활용한 약간의 성능상의 이점을 얻을 수 있지만, 더 중요한 것은 엔티티의 동일성을 보장받을 수 있습니다.
가령, SQL 쿼리를 두번 보낸다고 해보겠습니다.
Member member1 = memberDao.getMember(memberId);
Member member2 = memberDao.getMember(memberId);
member1 == member2 // falseSQL 쿼리로 2번의 member를 조회한 member1과 member2는 동일하지 않은 객체가 됩니다.
하지만, 저희가 자바 컬렉션에서 객체를 가져올 때는 두번 객체를 가져와도 두 객체는 같은 객체임을 알고 있습니다.
JPA를 사용하면, 같은 트랜잭션안에서 find메소드를 두번 호출해도 두 객체는 같은 객체임을 보장받을 수 있고, 이러한 것이 가능하게 하는 중심에는 영속성 컨텍스트가 있습니다.
영속성 컨텍스트에 대한 말이 조금 길어진 것 같은데, 영속성 컨텍스트에 대해서는 추후 다시 포스팅하겠습니다.
아무튼 하나의 트랜잭션 안에서 JPA는 영속성 컨텍스트의 내부 쿼리 저장소에 쿼리문을 모아두었다가, 트랜잭션이 커밋되는 시점에 쿼리를 데이터베이스로 보내게 됩니다.
이 과정에서 저는 궁금증이 생긴 점이 있었습니다.
엔티티의 PK를 auto increment나 오라클의 sequence 전략을 통해 생성할 경우, 쿼리가 나가서 데이터베이스에 저장이 되기전까지는 id 값을 모르는 거 아닌가?
즉, 하나의 트랜잭션 안에서 테스트 코드를 작성하거나 다른 작업을 할때 id값은 알 수가 없는 것인가와 영속화가 되기 위해서는 ID가 필요하지 않나라는 의문이 생긴 것이었습니다.
테스트
테스트는 JPA와 Java만을 사용하여 진행하였습니다.
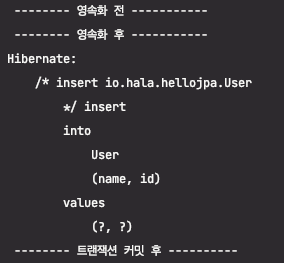
1. ID를 직접 입력하는 경우
transaction.begin();
try {
User user = new User("123", "james");
System.out.println(" -------- 영속화 전 ----------- ");
entityManager.persist(user);
System.out.println(" -------- 영속화 후 ----------- ");
transaction.commit();
System.out.println(" -------- 트랜잭션 커밋 후 ---------- ");
} catch (Exception e) {
transaction.rollback();
}쿼리가 언제 데이터베이스로 가는지 보는 간단한 테스트였습니다.
결과는 예상한 대로, 영속화할 때가 아닌 트랜잭션 커밋 시점에 쿼리가 갔습니다.
2. ID 생성을 데이터베이스에 위임하는 경우
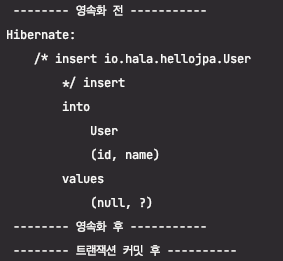
생각했던 것과 달리, 이 경우 영속화가 일어날 때 insert 쿼리가 나가게 된 것을 알 수 있습니다.
디버깅
우선 이에 대한 내용을 먼저 찾아보니, IDENTITY 식별자 생성 전략(mysql의 auto-increment 등)은 어쩔 수 없이, 쓰기 지연이 동작하지 않고 insert 쿼리가 먼저 데이터베이스로 나간다는 것을 알게 되었습니다. Sequence 전략은 조금 다르지만, 이번 포스팅에서는 Identity 전략에 대해서만 다루겠습니다.
디버깅을 해본 결과 우리가 간편하게 사용하는 JPA는 역시 내부적으로 많은 일을 하는 것을 느끼게 할만큼 복잡해서, 큰 부분에 대해서만 작성하려합니다.
틀린 내용이 있을 수 있으니 알려주시면 감사하겠습니다
1. persist event
먼저 우리는 엔티티 매니저의 persist 메소드를 호출했으므로, persist event가 발생하고, 이벤트 리스너가 이를 받아들입니다.
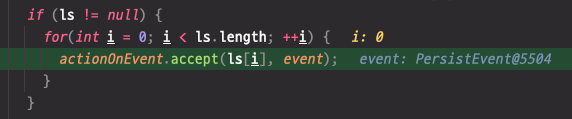
이후, entity라는 오브젝트에 User 객체를 넣게 됩니다.
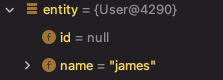
2. 영속 상태에 따른 분기
우리가 현재 영속화를 시키려하는 User 객체는 영속 상태 중 비영속 상태(new/transient) 입니다.
그렇기 때문에, 분기문에서 비영속 상태에 해당하는 곳으로 들어가게 됩니다.

디버깅을 포스팅에 담으려니 다소 어렵긴 하지만 계속 진행해보겠습니다. 비영속 상태 즉, Transient 상태인 경우에 saveWithGenerateId라는 메소드를 만나게 됩니다. 계속해서 들어가보겠습니다.
3. ID를 어떻게 만들 것인가
우리는 User 엔티티에 ID를 IDENTITY 식별자 생성 전략으로 매핑했습니다.
saveWithGenerateId 메소드에 들어가니, generateId에 POST_INSERT_INDICATOR가 매핑되어있는 것을 알게 되었습니다.

POST_INSERT_INDICATOR
public static final Serializable POST_INSERT_INDICATOR
Marker object returned from IdentifierGenerator.generate(org.hibernate.engine.SessionImplementor, java.lang.Object) to indicate that the entity's identifier will be generated as part of the datbase insertion.
즉, 데이터베이스에 Insert가 될 때 식별자가 생성되는 것을 나타내주는 것이라고 생각하면 될 것 같습니다.
우리가 의도한 방식과 일치하므로, performSave로 들어가겠습니다.
이름에서도 알 수 있듯이 이제 곧 저장을 실행할 것 같습니다. 논외로 SHORT_CIRCUIT_INDICATOR 전략 같은 경우는 위에서보니 바로 식별자를 가져오는 듯한 추측을 메소드 이름을 통해 해볼 수 있을 것 같네요.
4. 저장 수행

자세히 다 담지는 못했지만, 영속화 과정 중에 insert action을 수행하는 것을 알 수 있었습니다.
분기가 워낙 많지만, 디버깅을 하면 충분히 해보실 수 있으실텐데요 결국 마지막에 JPA가 생성한 insertSQL까지 발견하실 수 있게 됩니다.


마치며
결국, JPA는 Identity 식별자 생성 전략에 있어서 울며 겨자먹기 식으로 트랜잭션이 커밋되는 시점이 아닌, 영속화가 일어날 때 Insert 쿼리문을 데이터베이스에 보내는 것을 알 수 있었습니다.
당연한 이야기일 수도 있지만, 영속성 컨텍스트에서 관리를 하려면 식별자가 필요하고 이러한 식별자 생성을 데이터베이스에 위임하는 전략에 대해서는 어쩔 수 없이 Insert 쿼리를 먼저 수행해야 되는 것이겠죠 😃
